







文章目录
运算
+,- 加减法
- 逐元加减法
#include <iostream>
#include "e:/eigen/Eigen/Dense"
using namespace std;
int main()
{
Eigen::Matrix2d a;
a << 1, 2,
3, 4;
Eigen::MatrixXd b(2,2);
b << 10, 20,
30, 40;
cout << "a + b =\n" << a + b << endl;
cout << "a - b =\n" << a - b << endl;
cout << "Doing a += b;" << endl;
a += b;
cout << "Now a =\n" << a << endl;
Eigen::Vector3d v(1,2,3);
Eigen::Vector3d w(1,0,0);
cout << "-v + w - v =\n" << -v + w - v << endl;
}
a + b =
11 22
33 44
a - b =
-9 -18
-27 -36
Doing a += b;
Now a =
11 22
33 44
-v + w - v =
-1
-4
-6
Process returned 0 (0x0) execution time : 0.573 s
Press any key to continue.
* / 乘除法
逐元 乘法
1、matrix*scalar
2、scalar*matrix
3、matrix*=scalar
#include <iostream>
#include <Eigen/Dense>
int main()
{
Eigen::Matrix2d a;
a << 10, 20,
30, 40;
Eigen::Vector3d v(1,2,3);
std::cout << "a * 0.1 =\n" << a * 0.1 << std::endl;
std::cout << "0.1 * v =\n" << 10 * v << std::endl;
std::cout << "Doing v *= 2;" << std::endl;
v *= 2;
std::cout << "Now v =\n" << v << std::endl;
}
a * 2.5 =
1 2
3 4
0.1 * v =
10
20
30
Doing v *= 2;
Now v =
2
4
6
Process returned 0 (0x0) execution time : 0.534 s
Press any key to continue.
逐元 除法
1、matrix/scalar
2、matrix/=scalar
#include <iostream>
#include "e:/eigen/Eigen/Dense"
using namespace std;
int main()
{
Eigen::Matrix2d a;
a << 10, 20,
30, 40;
Eigen::Vector3f v(1,2,3);
cout << "a / 5 =\n" << a / 5 << endl;
cout << "v / 5 =\n" << v /5 << endl;
cout << "Doing a /= 10;" << endl;
a /= 10;
cout << "Now a =\n" << a << endl;
}
a / 5 =
2 4
6 8
v / 5 =
0.2
0.4
0.6
Doing a /= 10;
Now a =
1 2
3 4
Process returned 0 (0x0) execution time : 0.477 s
Press any key to continue.
逐元综合运算
#include <iostream>
#include "e:/eigen/Eigen/Dense"
using namespace std;
int main()
{
Eigen::Matrix2d a;
a << 10, 20,
30, 40;
Eigen::Matrix2d b;
b << 1, 2,
3, 4;
cout << "a *10+ b =\n" << a*10+b << endl;
}
a *10+ b =
101 202
303 404
Process returned 0 (0x0) execution time : 0.394 s
Press any key to continue.
矩阵乘法与加减法
#include <iostream>
#include "e:/eigen/Eigen/Dense"
using namespace std;
int main()
{
Eigen::Matrix2d a;
a << 10, 20,
30, 40;
Eigen::Matrix2d b;
b << 2, 4,
8, 16;
Eigen::Vector2d v(1,2);
cout << "a * b =\n" << a *b << endl;
cout << "a * v =\n" << a *v << endl;
cout << "a + b =\n" << a +b << endl;
cout << "a - b =\n" << a -b << endl;
}
a * b =
180 360
380 760
a * v =
50
110
a + b =
12 24
38 56
a - b =
8 16
22 24
Process returned 0 (0x0) execution time : 0.429 s
Press any key to continue.
转置、共轭、伴随矩阵
-
转置矩阵
将矩阵的行列互换得到的新矩阵称为转置矩阵,转置矩阵的行列式不变。

-
复数:
template <class Type>
class complex
引用自https://learn.microsoft.com/zh-cn/cpp/standard-library/complex-class?view=msvc-170
复数 a + bi
名称 描述
imag 提取复数的虚分量。
real 提取复数的实分量。#include <complex> #include <iostream> int main( ) { using namespace std; complex<double> c1( 4.0 , 3.0 ); cout << "The complex number c1 = " << c1 << endl; double dr1 = c1.real(); cout << "The real part of c1 is c1.real() = " << dr1 << "." << endl; double di1 = c1.imag(); cout << "The imaginary part of c1 is c1.imag() = " << di1 << "." << endl; }The complex number c1 = (4,3) The real part of c1 is c1.real() = 4. The imaginary part of c1 is c1.imag() = 3.
- 复数矩阵
typedef Matrix< std::complex< float >, Dynamic, Dynamic > Eigen::MatrixXcf - example
#include <iostream>
#include "e:/eigen/Eigen/Dense"
using namespace std;
int main()
{
Eigen::Matrix2d a;
a << 10, 20,
30, 40;
Eigen::MatrixXcf b= Eigen::MatrixXcf::Random(2,2);
cout << "转置:a^T =\n" << a.transpose() << endl;
cout << "共轭:a conjugate() =\n" << b.conjugate() << endl;
cout << "伴随矩阵:a adjoint() =\n"<< a.adjoint() << endl;
}
转置:a^T =
10 30
20 40
共轭:a conjugate() =
(0.127171,0.997497) (-0.0402539,-0.170019)
(0.617481,0.613392) (0.791925,0.299417)
伴随矩阵:a adjoint() =
10 30
20 40
Process returned 0 (0x0) execution time : 0.540 s
Press any key to continue.
- a = a.transpose()转置并替换使用a.transposeInPlace()
- a = a.adjoint() 共轭并替换a.adjointInPlace()
点乘法,叉积
- dot product
引用自百度百科的解释
点积在数学中,又称数量积(dot product; scalar product),是指接受在实数R上的两个向量并返回一个实数值标量的二元运算。它是欧几里得空间的标准内积。
两个向量a = [a1, a2,…, an]和b = [b1, b2,…, bn]的点积定义为:
a·b=a1b1+a2b2+……+anbn。
使用矩阵乘法并把(纵列)向量当作n×1 矩阵,点积还可以写为:
a ⋅ b = a T ∗ b ,这里的 a T 指示矩阵 a 的转置。 a·b=a^T*b,这里的a^T指示矩阵a的转置。 a⋅b=aT∗b,这里的aT指示矩阵a的转置。
- cross product
引用自百度百科知识
向量积,数学中又称外积、叉积,物理中称矢积、叉乘,是一种在向量空间中向量的二元运算。与点积不同,它的运算结果是一个向量而不是一个标量。并且两个向量的叉积与这两个向量和垂直。其应用也十分广泛,通常应用于物理学光学和计算机图形学中。
- example
#include <iostream>
#include "e:/eigen/Eigen/Dense"
using namespace std;
int main()
{
Eigen::Vector3d v(1,2,3);
Eigen::Vector3d w(0,1,2);
cout << "v dot product w =\n" << v.dot(w) << endl;
cout << "v cross product w =\n" << v.cross(w) << endl;
}
v dot product w =
8
v cross product w =
1
-2
1
Process returned 0 (0x0) execution time : 0.327 s
Press any key to continue.
大整数GMP
概述
GMP
GMP是一个用于任意精度算术的免费库,可对有符号整数、有理数和浮点数进行操作。除了运行GMP的机器的可用内存所暗示的精度外,没有实际的限制。GMP具有丰富的功能集,各功能具有规则的接口。
GMP的主要目标应用是密码学应用与研究、互联网安全应用、代数系统、计算代数研究等。
GMP被精心设计为尽可能快,无论是小操作数还是大操作数。速度是通过使用全字作为基本算术类型,通过使用快速算法,为许多cpu最常见的内循环使用高度优化的汇编代码,以及对速度的总体强调来实现的。
第一个GMP版本于1991年发布。它被不断地开发和维护,大约每年发布一次新版本。
安装 cygwin
下面系列必须安装
1.gcc-core,gcc-g++,mingw-w64-gcc-core,mingw-w64-gcc-c++
2.m4,make
安装 gmp
$ ./configure --enable-cxx
make
make install
- gmp编译选项
–prefix and --exec-prefix
The --prefix option can be used in the normal way to direct GMP to install under a particular tree. The default is ‘/usr/local’. --exec-prefix can be used to direct architecture-dependent files like libgmp.a to a different location. This can be used to sharearchitecture-independent parts like the documentation, but separate
the dependent parts. Note however that gmp.h is architecture-dependent
since it encodes certain aspects of libgmp, so it will be necessary to
ensure both $prefix/include and $exec_prefix/include are available to
the compiler.
–disable-shared, --disable-staticBy default both shared and static libraries are built (where possible), but one or other can be disabled. Shared libraries resultin smaller executables and permit code sharing between separate
running processes, but on some CPUs are slightly slower, having a
small cost on each function call. Native Compilation,
–build=CPU-VENDOR-OSFor normal native compilation, the system can be specified with ‘--build’. By default ‘./configure’ uses the output from running‘./config.guess’. On some systems ‘./config.guess’ can determine the
exact CPU type, on others it will be necessary to give it explicitly.
For example,./configure --build=ultrasparc-sun-solaris2.7 In all cases the ‘OS’ part is important, since it controls how libtool generates shared libraries. Running ‘./config.guess’ is thesimplest way to see what it should be, if you don’t know already.
Cross Compilation, --host=CPU-VENDOR-OSWhen cross-compiling, the system used for compiling is given by ‘--build’ and the system where the library will run is given by‘–host’. For example when using a FreeBSD Athlon system to build
GNU/Linux m68k binaries,./configure --build=athlon-pc-freebsd3.5 --host=m68k-mac-linux-gnu Compiler tools are sought first with the host system type as a prefix. For example m68k-mac-linux-gnu-ranlib is tried, then plainranlib. This makes it possible for a set of cross-compiling tools to
co-exist with native tools. The prefix is the argument to ‘–host’,
and this can be an alias, such as ‘m68k-linux’. But note that tools
don’t have to be set up this way, it’s enough to just have a PATH with
a suitable cross-compiling cc etc.Compiling for a different CPU in the same family as the build system is a form of cross-compilation, though very possibly this wouldmerely be special options on a native compiler. In any case
‘./configure’ avoids depending on being able to run code on the build
system, which is important when creating binaries for a newer CPU
since they very possibly won’t run on the build system.In all cases the compiler must be able to produce an executable (of whatever format) from a standard C main. Although only objectfiles will go to make up libgmp, ‘./configure’ uses linking tests for
various purposes, such as determining what functions are available on
the host system.Currently a warning is given unless an explicit ‘--build’ is used when cross-compiling, because it may not be possible to correctlyguess the build system type if the PATH has only a cross-compiling cc.
Note that the ‘--target’ option is not appropriate for GMP. It’s for use when building compiler tools, with ‘--host’ being where theywill run, and ‘–target’ what they’ll produce code for. Ordinary
programs or libraries like GMP are only interested in the ‘–host’
part, being where they’ll run. (Some past versions of GMP used
‘–target’ incorrectly.) CPU typesIn general, if you want a library that runs as fast as possible, you should configure GMP for the exact CPU type your system uses.However, this may mean the binaries won’t run on older members of the
family, and might run slower on other members, older or newer. The
best idea is always to build GMP for the exact machine type you intend
to run it on.The following CPUs have specific support. See configure.ac for details of what code and compiler options they select. Alpha: ‘alpha’, ‘alphaev5’, ‘alphaev56’, ‘alphapca56’, ‘alphapca57’, ‘alphaev6’, ‘alphaev67’, ‘alphaev68’, ‘alphaev7’ Cray: ‘c90’, ‘j90’, ‘t90’, ‘sv1’ HPPA: ‘hppa1.0’, ‘hppa1.1’, ‘hppa2.0’, ‘hppa2.0n’, ‘hppa2.0w’, ‘hppa64’ IA-64: ‘ia64’, ‘itanium’, ‘itanium2’ MIPS: ‘mips’, ‘mips3’, ‘mips64’ Motorola: ‘m68k’, ‘m68000’, ‘m68010’, ‘m68020’, ‘m68030’, ‘m68040’, ‘m68060’, ‘m68302’, ‘m68360’, ‘m88k’, ‘m88110’ POWER: ‘power’, ‘power1’, ‘power2’, ‘power2sc’ PowerPC: ‘powerpc’, ‘powerpc64’, ‘powerpc401’, ‘powerpc403’, ‘powerpc405’, ‘powerpc505’, ‘powerpc601’, ‘powerpc602’, ‘powerpc603’,‘powerpc603e’, ‘powerpc604’, ‘powerpc604e’, ‘powerpc620’,
‘powerpc630’, ‘powerpc740’, ‘powerpc7400’, ‘powerpc7450’,
‘powerpc750’, ‘powerpc801’, ‘powerpc821’, ‘powerpc823’, ‘powerpc860’,
‘powerpc970’
SPARC: ‘sparc’, ‘sparcv8’, ‘microsparc’, ‘supersparc’, ‘sparcv9’, ‘ultrasparc’, ‘ultrasparc2’, ‘ultrasparc2i’, ‘ultrasparc3’,
‘sparc64’
x86 family: ‘i386’, ‘i486’, ‘i586’, ‘pentium’, ‘pentiummmx’, ‘pentiumpro’, ‘pentium2’, ‘pentium3’, ‘pentium4’, ‘k6’, ‘k62’, ‘k63’,
‘athlon’, ‘amd64’, ‘viac3’, ‘viac32’
Other: ‘arm’, ‘sh’, ‘sh2’, ‘vax’,CPUs not listed will use generic C code. Generic C Build If some of the assembly code causes problems, or if otherwise desired, the generic C code can be selected with the configure–disable-assembly.
Note that this will run quite slowly, but it should be portable and should at least make it possible to get something running if allelse fails. Fat binary, --enable-fat
Using --enable-fat selects a “fat binary” build on x86, where optimized low level subroutines are chosen at runtime according to theCPU detected. This means more code, but gives good performance on all
x86 chips. (This option might become available for more architectures
in the future.) ABIOn some systems GMP supports multiple ABIs (application binary interfaces), meaning data type sizes and calling conventions. Bydefault GMP chooses the best ABI available, but a particular ABI can
be selected. For example./configure --host=mips64-sgi-irix6 ABI=n32 See ABI and ISA, for the available choices on relevant CPUs, and what applications need to do. CC, CFLAGS By default the C compiler used is chosen from among some likely candidates, with gcc normally preferred if it’s present. The usual‘CC=whatever’ can be passed to ‘./configure’ to choose something
different.For various systems, default compiler flags are set based on the CPU and compiler. The usual ‘CFLAGS="-whatever"’ can be passed to‘./configure’ to use something different or to set good flags for
systems GMP doesn’t otherwise know.The ‘CC’ and ‘CFLAGS’ used are printed during ‘./configure’, and can be found in each generated Makefile. This is the easiest way tocheck the defaults when considering changing or adding something.
Note that when ‘CC’ and ‘CFLAGS’ are specified on a system supporting multiple ABIs it’s important to give an explicit‘ABI=whatever’, since GMP can’t determine the ABI just from the flags
and won’t be able to select the correct assembly code.If just ‘CC’ is selected then normal default ‘CFLAGS’ for that compiler will be used (if GMP recognises it). For example ‘CC=gcc’ canbe used to force the use of GCC, with default flags (and default ABI).
CPPFLAGSAny flags like ‘-D’ defines or ‘-I’ includes required by the preprocessor should be set in ‘CPPFLAGS’ rather than ‘CFLAGS’.Compiling is done with both ‘CPPFLAGS’ and ‘CFLAGS’, but preprocessing
uses just ‘CPPFLAGS’. This distinction is because most preprocessors
won’t accept all the flags the compiler does. Preprocessing is done
separately in some configure tests. CC_FOR_BUILDSome build-time programs are compiled and run to generate host-specific data tables. ‘CC_FOR_BUILD’ is the compiler used forthis. It doesn’t need to be in any particular ABI or mode, it merely
needs to generate executables that can run. The default is to try the
selected ‘CC’ and some likely candidates such as ‘cc’ and ‘gcc’,
looking for something that works.No flags are used with ‘CC_FOR_BUILD’ because a simple invocation like ‘cc foo.c’ should be enough. If some particular options arerequired they can be included as for instance ‘CC_FOR_BUILD=“cc
-whatever”’. C++ Support, --enable-cxxC++ support in GMP can be enabled with ‘--enable-cxx’, in which case a C++ compiler will be required. As a convenience‘–enable-cxx=detect’ can be used to enable C++ support only if a
compiler can be found. The C++ support consists of a library
libgmpxx.la and header file gmpxx.h (see Headers and Libraries).A separate libgmpxx.la has been adopted rather than having C++ objects within libgmp.la in order to ensure dynamic linked C programsaren’t bloated by a dependency on the C++ standard library, and to
avoid any chance that the C++ compiler could be required when linking
plain C programs.libgmpxx.la will use certain internals from libgmp.la and can only be expected to work with libgmp.la from the same GMP version. Futurechanges to the relevant internals will be accompanied by renaming, so
a mismatch will cause unresolved symbols rather than perhaps
mysterious misbehaviour.In general libgmpxx.la will be usable only with the C++ compiler that built it, since name mangling and runtime support are usuallyincompatible between different compilers. CXX, CXXFLAGS
When C++ support is enabled, the C++ compiler and its flags can be set with variables ‘CXX’ and ‘CXXFLAGS’ in the usual way. The defaultfor ‘CXX’ is the first compiler that works from a list of likely
candidates, with g++ normally preferred when available. The default
for ‘CXXFLAGS’ is to try ‘CFLAGS’, ‘CFLAGS’ without ‘-g’, then for g++
either ‘-g -O2’ or ‘-O2’, or for other compilers ‘-g’ or nothing.
Trying ‘CFLAGS’ this way is convenient when using ‘gcc’ and ‘g++’
together, since the flags for ‘gcc’ will usually suit ‘g++’.It’s important that the C and C++ compilers match, meaning their startup and runtime support routines are compatible and that theygenerate code in the same ABI (if there’s a choice of ABIs on the
system). ‘./configure’ isn’t currently able to check these things very
well itself, so for that reason ‘–disable-cxx’ is the default, to
avoid a build failure due to a compiler mismatch. Perhaps this will
change in the future.Incidentally, it’s normally not good enough to set ‘CXX’ to the same as ‘CC’. Although gcc for instance recognises foo.cc as C++ code,only g++ will invoke the linker the right way when building an
executable or shared library from C++ object files. Temporary Memory,
–enable-alloca=GMP allocates temporary workspace using one of the following three methods, which can be selected with for instance‘–enable-alloca=malloc-reentrant’.
‘alloca’ - C library or compiler builtin. ‘malloc-reentrant’ - the heap, in a re-entrant fashion. ‘malloc-notreentrant’ - the heap, with global variables. For convenience, the following choices are also available. ‘--disable-alloca’ is the same as ‘no’. ‘yes’ - a synonym for ‘alloca’. ‘no’ - a synonym for ‘malloc-reentrant’. ‘reentrant’ - alloca if available, otherwise ‘malloc-reentrant’. This is the default. ‘notreentrant’ - alloca if available, otherwise ‘malloc-notreentrant’. alloca is reentrant and fast, and is recommended. It actually allocates just small blocks on the stack; larger ones usemalloc-reentrant.
‘malloc-reentrant’ is, as the name suggests, reentrant and thread safe, but ‘malloc-notreentrant’ is faster and should be used ifreentrancy is not required.
The two malloc methods in fact use the memory allocation functions selected by mp_set_memory_functions, these being malloc and friends bydefault. See Custom Allocation.
An additional choice ‘--enable-alloca=debug’ is available, to help when debugging memory related problems (see Debugging). FFTMultiplication, --disable-fft
By default multiplications are done using Karatsuba, 3-way Toom, higher degree Toom, and Fermat FFT. The FFT is only used on large tovery large operands and can be disabled to save code size if desired.
Assertion Checking, --enable-assertThis option enables some consistency checking within the library. This can be of use while debugging, see Debugging. ExecutionProfiling, --enable-profiling=prof/gprof/instrument
Enable profiling support, in one of various styles, see Profiling. MPN_PATH Various assembly versions of each mpn subroutines are provided. For a given CPU, a search is made through a path to choose a versionof each. For example ‘sparcv8’ has
MPN_PATH="sparc32/v8 sparc32 generic" which means look first for v8 code, then plain sparc32 (which is v7), and finally fall back on generic C. Knowledgeable users withspecial requirements can specify a different path. Normally this is
completely unnecessary.
example
$ g++ main.cpp -lgmpxx -lgmp -I/cygdrive/d/gmp-6.3.0 -L/cygdrive/d/gmp-6.3.0/.libs

#include <iostream>
#include "gmp.h"
using namespace std;
int main()
{
mpz_t a, b, c;
mpz_init(a);
mpz_init(b);
mpz_init(c);
mpz_set_str(a, "34624532532450994252345856747", 10);
mpz_set_str(b, "23450234958877723495090425432", 10);
mpz_add(c, a, b);
gmp_printf("%Zd+%Zd=%Zd\n", a,b,c);
mpz_clear(a);
mpz_clear(b);
mpz_clear(c);
return 0;
}
Eigen
基本属性和运算
- 代码
#include <iostream>
#include "e:/eigen/Eigen/Dense"
using namespace std;
int main()
{
Eigen::Matrix2d mat;
mat << 10, 20,
30, 40;
cout << "Here is mat.sum(): " << mat.sum() << endl;
cout << "Here is mat.prod(): " << mat.prod() << endl;
cout << "Here is mat.mean(): " << mat.mean() << endl;
cout << "Here is mat.minCoeff(): " << mat.minCoeff() << endl;
cout << "Here is mat.maxCoeff(): " << mat.maxCoeff() << endl;
cout << "Here is mat.trace(): " << mat.trace() << endl;
}
- 函数功能
sum():求元素之和
prod() :求元素之积
prod() :求元素平均值
minCoeff() :最小元素
maxCoeff() :最大元素
trace() : the sum of the coefficients on the main diagonal.主对角线之和 - 运行结果
Here is mat.sum(): 100
Here is mat.prod(): 240000
Here is mat.mean(): 25
Here is mat.minCoeff(): 10
Here is mat.maxCoeff(): 40
Here is mat.trace(): 50
Process returned 0 (0x0) execution time : 0.323 s
Press any key to continue.
读写文件
概述
- fstream
typedef basic_fstream<char, char_traits<char>> fstream;
此类型是类模板 basic_fstream 的同义词,专用于具有默认字符特征的 char 类型的元素。
- ifstream
定义要用于从文件中按顺序读取单字节字符数据的流。
using namespace std;
ifstream infile("hello.txt");
if (!infile.bad())
{
cout << infile.rdbuf();
infile.close();
}
- ofstream
专用于 char 模板参数的类型 basic_ofstream。
typedef basic_ofstream<char, char_traits<char>> ofstream;
- openmode
如何与流进行交互。
class ios_base {
public:
typedef implementation-defined-bitmask-type openmode;
static const openmode in;
static const openmode out;
static const openmode ate;
static const openmode app;
static const openmode trunc;
static const openmode binary;
// ...
};
example
- 例1
#include <iostream>
#include <fstream>
using namespace std;
int main(){
//write
ofstream fileOut;
fileOut.open("hello.txt");
fileOut<<"hello,world!"<<endl;
fileOut<<"hello,hello";
fileOut.close();
//read
ifstream fileIn;
char helloTxt[80];
fileIn.open("hello.txt");
fileIn>>helloTxt;
cout<<helloTxt<<endl;
fileIn>>helloTxt;
cout<<helloTxt<<endl;
fileIn.close();
}
hello,world!
hello,hello
Process returned 0 (0x0) execution time : 0.134 s
Press any key to continue.
- 例2
// basic_fstream_class.cpp
// compile with: /EHsc
#include <fstream>
#include <iostream>
using namespace std;
int main(int argc, char **argv)
{
fstream fs("hello.txt", ios::in | ios::out | ios::trunc);
if (!fs.bad())
{
// Write
fs << "hello,world" << endl;
fs << "hello!" << endl;
fs.close();
// read
fs.open("hello.txt", ios::in);
cout << fs.rdbuf();
fs.close();
}
}
- 例3
#include <iostream>
#include <fstream>
using namespace std;
int main(){
//write
ofstream fileOut;
fileOut.open("hello.txt");
fileOut<<"hello,world!"<<endl;
fileOut<<"hello,hello";
fileOut.close();
//read
ifstream fileIn;
char helloTxt[80];
fileIn.open("hello.txt");
while (fileIn>>helloTxt){
cout<<helloTxt<<endl;
}
fileIn.close();
}
- 例4
#include <iostream>
#include <fstream>
using namespace std;
int main(){
//write
ofstream fileOut;
fileOut.open("hello.txt");
fileOut<<"hello,world!"<<endl;
fileOut<<"hello,hello";
fileOut.close();
//read
ifstream fileIn;
char helloTxt[80];
fileIn.open("hello1.txt");
if (!fileIn.is_open()){
cout<<"打开失败!"<<endl;
return 0;
}
while (fileIn>>helloTxt){
cout<<helloTxt<<endl;
}
fileIn.close();
}
- 例5
#include <iostream>
#include <fstream>
using namespace std;
int main(){
//write
ofstream fileOut;
fileOut.open("hello.txt");
fileOut<<"hello,world!"<<endl;
fileOut<<"hello,hello";
fileOut.close();
//read
ifstream fileIn;
char helloChar;
fileIn.open("hello.txt");
if (!fileIn.is_open()){
cout<<"打开失败!"<<endl;
return 0;
}
int i=0;
while (fileIn.get(helloChar)){
cout<<helloChar;
if (helloChar!='\n') i++;
}
cout<<endl<<"文件的字符数:"<<i<<endl;
fileIn.close();
}
hello,world!
hello,hello
文件的字符数:23
Process returned 0 (0x0) execution time : 0.248 s
Press any key to continue.
更多内容在微软文档
csv
读文件
#include <iostream>
#include <fstream>
using namespace std;
int main(){
//read
ifstream fileIn;
char helloChar;
fileIn.open("e:/ml_data/iris/iris.data");
if (!fileIn.is_open()){
cout<<"打开失败!"<<endl;
return 0;
}
int i=0;
while (fileIn.get(helloChar)){
cout<<helloChar;
if (helloChar!='\n') i++;
}
cout<<endl<<"文件的字符数:"<<i<<endl;
fileIn.close();
}
读取每个字段
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <sstream>
using namespace std;
vector<string> split(const string &text, char separator);
int main(){
//read
ifstream fileIn;
char helloStr[100];
vector<string> sampleDatas;
fileIn.open("e:/ml_data/iris/iris.data");
if (!fileIn.is_open()){
cout<<"打开失败!"<<endl;
return 0;
}
while (fileIn>>helloStr){
sampleDatas=split(helloStr,',');
for (const string &data: sampleDatas) {
cout << data<<" " ;
}
cout<<endl;
}
fileIn.close();
}
vector<string> split(const string &text, char separator) {
vector<string> tokens;
stringstream ss(text);
string item;
while (getline(ss, item, separator)) {
if (!item.empty()) {
tokens.push_back(item);
}
}
return tokens;
}
读取机器学习数据库iris
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <sstream>
#include <algorithm>
#include <regex>
using namespace std;
struct IrisDa{
float *irisX;
int dataSize;
int d;
~IrisDa(){
delete[] irisX;
}
};
vector<string> split(const string &text, char separator);
string removeSpaces(const string& input);
void rbLearn(const IrisDa *irisDa);
int main(){
ifstream fileIn;
char helloStr[100];
//read csv
fileIn.open("e:/ml_data/iris/iris_sample.data");
if (!fileIn.is_open()){
cout<<"打开失败!"<<endl;
return 0;
}
regex strRx(R"((\d+)(\.)(\d+))");
smatch match;
while (fileIn>>helloStr){
//construct x(n) and d(n)
IrisDa *irisDa=new IrisDa;
vector<string> sampleDatas=split(helloStr,',');
int dataCount=sampleDatas.size();
float *irisX= new float[dataCount];//x(n)
irisX[0]=1.0;
int irisD;//d(n)
int i=1;
for (const string &data: sampleDatas) {
string irisData=removeSpaces(data);
bool found = regex_match(irisData, match, strRx);
if (found) {
irisX[i]=stof(irisData);
i++;
}
else{
if (irisData=="Iris-setosa"){
irisD=1;
}
else{
irisD=-1;
}
}
}
irisDa->irisX=irisX;
irisDa->d=irisD;
irisDa->dataSize=dataCount;
rbLearn(irisDa);
}
fileIn.close();
}
void rbLearn(const IrisDa *irisDa){
cout<<"正在处理数据..."<<endl;
for (int i=0;i<irisDa->dataSize;i++) {
cout<<irisDa->irisX[i]<<" ";
}
cout<<endl;
}
vector<string> split(const string &text, char separator) {
vector<string> tokens;
stringstream ss(text);
string item;
while (getline(ss, item, separator)) {
if (!item.empty()) {
tokens.push_back(item);
}
}
return tokens;
}
string removeSpaces(const string& input) {
string result = input;
result.erase(std::remove(result.begin(), result.end(), ' '), result.end());
return result;
}
constexpr函数
函数可能在编译时求值,则声明它为constexpr,以提高效率。需要使用constexpr告诉编译器允许编译时计算。
constexpr int min(int x, int y) { return x < y ? x : y; }
void test(int v)
{
int m1 = min(-1, 2); // 可能在编译期计算
constexpr int m2 = min(-1, 2); // 编译时计算
int m3 = min(-1, v); // 运行时计算
constexpr int m4 = min(-1, v); // 错误,不能在编译期计算
}
int dcount = 0;
constexpr int double(int v)
{
++dcount; // constexpr 函数无副作用,因为这一行错误
return v + v;
}
constexpr函数被隐式地指定为内联函数,此外,constexpr允许递归。
#include <iostream>
constexpr int fac(int n)
{
return n > 0 ? n * fac( n - 1 ) : 1;
}
inline int myadd(int x,int y){return x+y;};
int main()
{
int n;
std::cout<<"请输入阶乘参数:";
std::cin>>n;
std::cout<<std::endl<<fac(n)<<std::endl;
std::cout<<myadd(12,55)<<std::endl;
return 0;
}
GMP大整数
codeblock环境配置
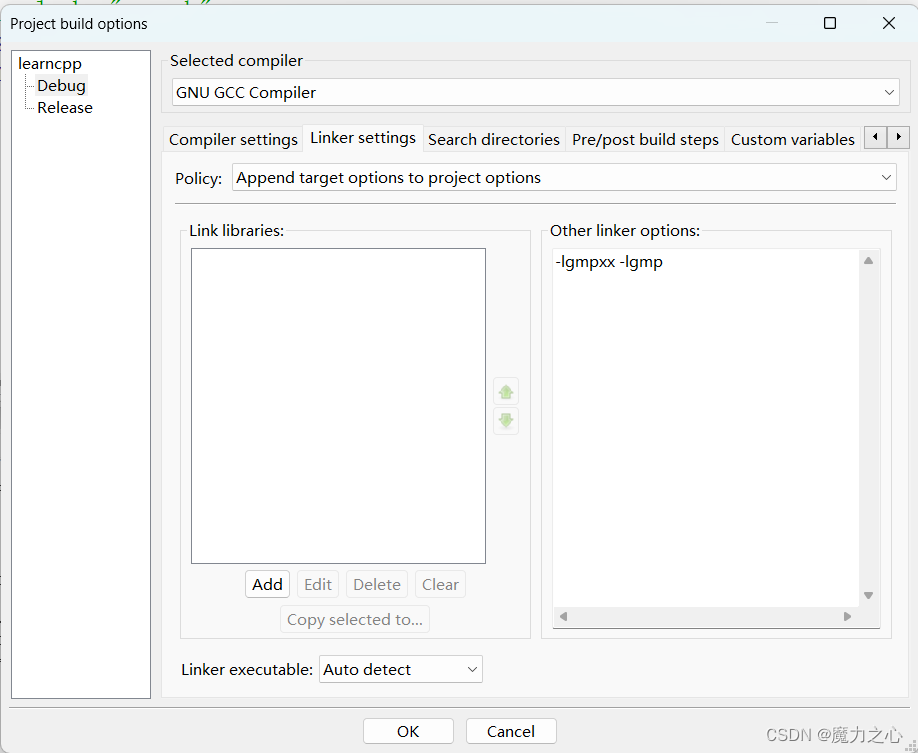
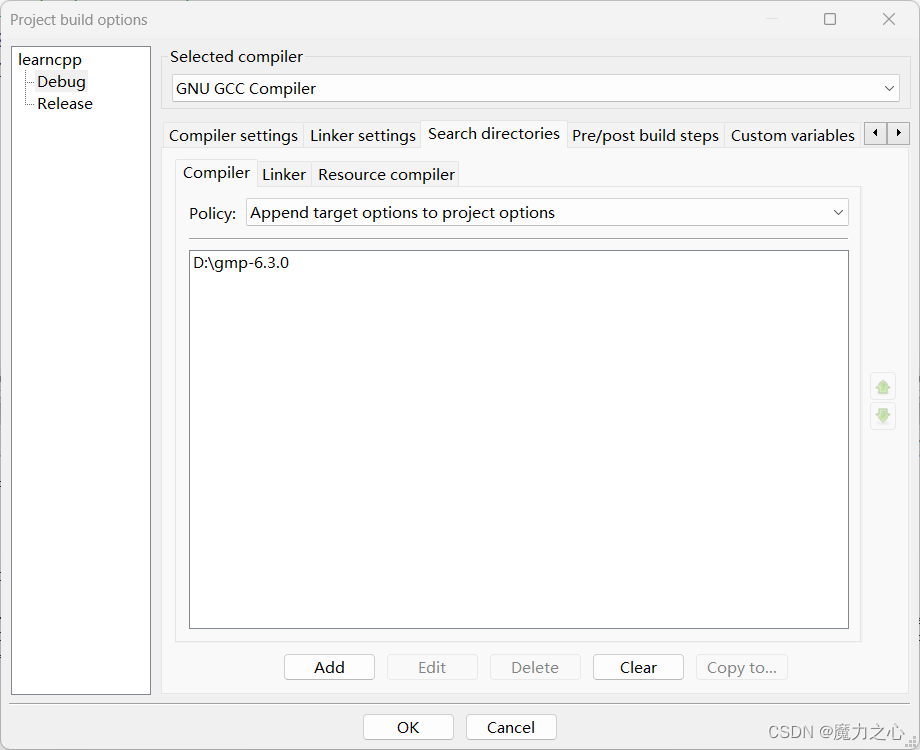

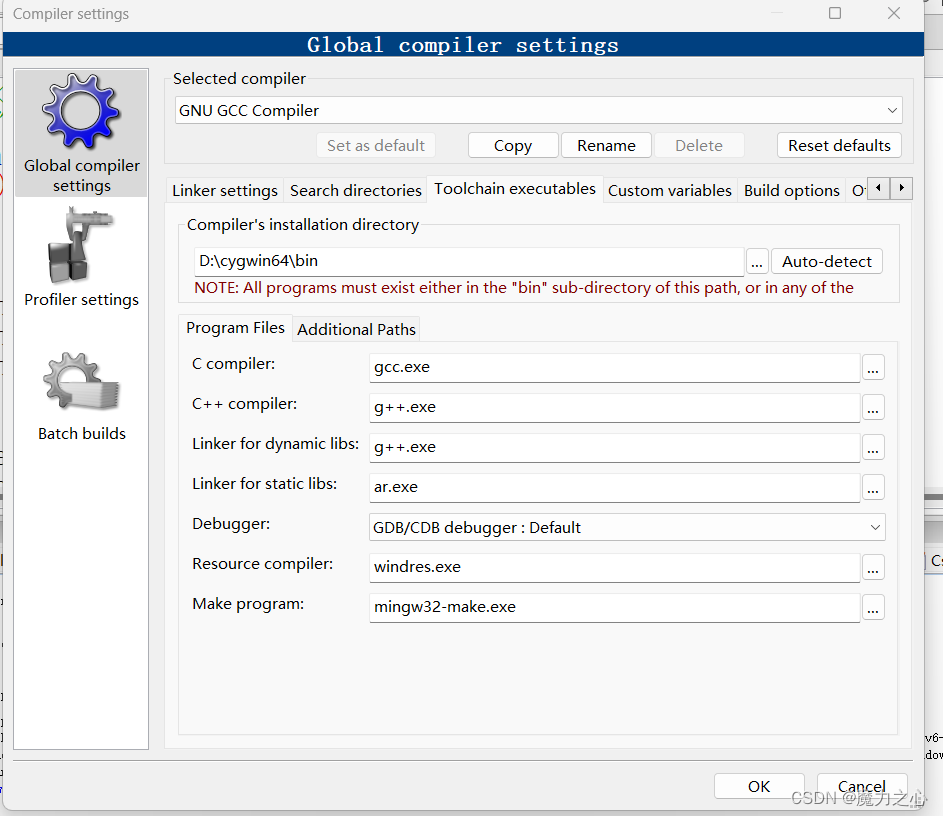
数据类型
- 整型
mpz_t sum;
struct foo { mpz_t x, y; };
mpz_t vec[20];
- 有理数
mpq_t quotient;
也是高倍精度分数。
- 浮点数
mpf_t fp;
浮点函数接受并返回C类型mp_exp_t中的指数。目前,这通常是很长的,但在某些系统上,这是效率的一个指标。
- 指针
Mpz_ptr用于指向mpz_t中的元素类型的指针
Mpz_srcptr for const指针指向mpz_t中的元素类型
Mpq_ptr用于指向mpq_t中的元素类型的指针
Mpq_srcptr for const指针指向mpq_t中的元素类型
Mpf_ptr用于指向mpf_t中元素类型的指针
Mpf_srcptr for const指针指向mpf_t中的元素类型
指向gmp_randstate_t中元素类型的指针
Gmp_randstate_srcptr for const指针指向gmp_randstate_t中的元素类型
函数类
用于有符号整数算术的函数,其名称以mpz_开头。关联类型为mpz_t。这门课大约有150个函数
用于有理数算术的函数,其名称以mpq_开头。关联类型为mpq_t。这门课大约有35个函数,但整数函数可以分别对分子和分母进行算术运算。
用于浮点运算的函数,其名称以mpf_开头。关联类型为mpf_t。这门课大约有70个函数。
对自然数进行操作的快速低级函数。这些由前面组中的函数使用,您也可以从时间要求非常严格的用户程序中直接调用它们。这些函数的名称以mpn_开头。关联类型为mp_limb_t数组。这个类中大约有60个(难以使用的)函数。
各种各样的功能。设置自定义分配的函数和生成随机数的函数。
Eigen
minCoeff 和maxCoeff
不带参数时,返回最小元素和最大元素,带参数时,返回元素所在坐标
#include <iostream>
#include "e:/eigen/Eigen/Dense"
using namespace std;
using namespace Eigen;
int main(){
Matrix2d m {{1,2},{3,4}};
std::ptrdiff_t i, j;
int minOfM = m.minCoeff(&i,&j);
cout << "Here is the matrix m:\n" << m << endl;
cout << "Its minimum coefficient (" << minOfM
<< ") is at position (" << i << "," << j << ")\n\n";
int maxOfM= m.maxCoeff(&i,&j);
cout << "Its maximum coefficient (" << maxOfM
<< ") is at position (" << i << "," << j << ")\n\n";
RowVector4i v = RowVector4i::Random();
int maxOfV = v.maxCoeff(&i);
cout << "Here is the vector v: " << v << endl;
cout << "Its maximum coefficient (" << maxOfV
<< ") is at position " << i << endl;
int minOfV = v.minCoeff(&j);
cout << "Its minimum coefficient (" << minOfV
<< ") is at position " << j << endl;
}
Here is the matrix m:
1 2
3 4
Its minimum coefficient (1) is at position (0,0)
Its maximum coefficient (4) is at position (1,1)
Here is the vector v: 730547559 -226810938 607950953 640895091
Its maximum coefficient (730547559) is at position 0
Its minimum coefficient (-226810938) is at position 1
Process returned 0 (0x0) execution time : 0.305 s
Press any key to continue.
Array类
Array类提供了通用数组,而Matrix类则用于线性代数。此外,Array类提供了一种简单的方法来执行系数操作,这种操作可能没有线性代数意义,比如向数组中的每个系数添加一个常数,或者对两个数组进行系数乘。
















 2888
2888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









