









MKL-DNN优化技术里,有一个很重要的技术就是层融合(Layer Fusion)
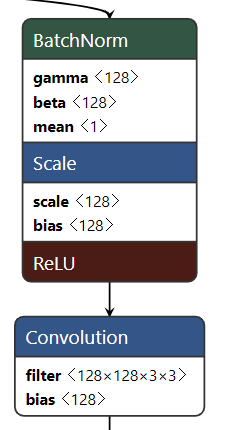
所谓的Layer fusion, 就是把好几层的计算合并成一层的操作里,例如下图左边的计算一共包含了3层Convolution+Sum+ReLU, 每层之间都包含了输入数据和输出数据的读写。通过读取观察每层输出的数据,我们也可以知道神经网络每层到底做了些什么,但是实际应用中我们只关心神经网络最开始的输入数据和最终推理输出的数据,这时候就可以把几层的计算混合在一起计算,这样就节省了大量的Memory I/O操作。

在MKL-DNN开发里,我们可以通过设置每一层计算对象的Post-ops属性来告诉MKL-DNN 这层计算完成后接下来会做哪些计算,这样MKL-DNN会自动在计算中合并一些计算来提高运算效率。具体的post-ops的描述可以参考这里的官方文档,同时官方文档的每一个计算Modules的描述文档里也讲了这个Module支持哪些post-ops操作
在DRRN的计算量,大量的出现了BN+ReLU+Conv的计算顺序,即BatchNorm+Scale算完接着就是ReLU计算
这时候就可以在定义BN计算的时候通过设置post-ops来帮忙带点私活,计算ReLU,
我们把BatchNorm的代码里这句话
auto bnrm_fwd_pd = batch_normalization_forward::primitive_desc(bnrm_fwd_d, cpu_engine);改为
mkldnn::post_ops po1;
po1.append_eltwise(
/* scale = */ 1.f,
/* alg kind = */ mkldnn::algorithm::eltwise_relu,
/* neg slope = */ 0.f,
/* unused for relu */ 0.f);
mkldnn::primitive_attr attr1;
attr1.set_post_ops(po1);
auto bnrm_fwd_pd = batch_normalization_forward::primitive_desc(bnrm_fwd_d, attr1, cpu_engine);编译运行
上篇文章的输出

本篇代码修改后的输出

可以看到前3个不为0的项现在全为0了 :)
接下来试试Conv+Post-ops
把MKL-DNN学习笔记 (五) 实现Conv层的快速计算里的这句
auto conv3_fast_prim_desc = convolution_forward::primitive_desc(conv3_fast_desc, cpu_engine);改为
mkldnn::post_ops po;
po.append_eltwise(
/* scale = */ 1.f,
/* alg kind = */ mkldnn::algorithm::eltwise_relu,
/* neg slope = */ 0.f,
/* unused for relu */ 0.f);
mkldnn::primitive_attr attr;
attr.set_post_ops(po);
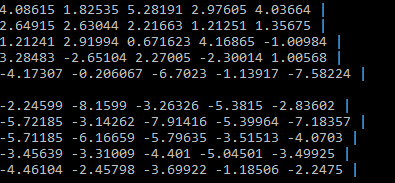
auto conv3_fast_prim_desc = convolution_forward::primitive_desc(conv3_fast_desc, attr, cpu_engine);再修改一下image,weights,bias, 把卷积输出的数据变复杂一下,运行...
没有post-ops
有post-ops
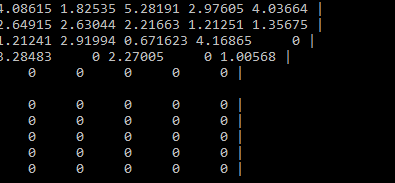
搞定收工!!!
最后代码奉上,仅供参考
https://github.com/tisandman555/mkldnn_study/blob/master/post_ops.cpp
PS
对于BN层来说,还可以通过设置这个normalization_flags 来实现post-ops -> Relu的效果
把
normalization_flags flags = normalization_flags::use_global_stats | normalization_flags::use_scale_shift赋值时多或一个fuse_norm_relu的标志位
normalization_flags flags = normalization_flags::use_global_stats | normalization_flags::use_scale_shift | normalization_flags::fuse_norm_relu;只改这一个句,也可以达到相同的效果















 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









