




在大模型应用快速落地的今天,RAG(Retrieval-Augmented Generation)系统已成为连接业务与智能的核心桥梁。然而,当 RAG 从 PoC 走向生产环境,可观测性(Observability)便成为保障系统稳定、可维护、可优化的关键能力。本文将围绕 日志、指标、分布式追踪 三大支柱,结合告警与可视化,手把手教你构建一个“透明可运维”的 RAG 系统。
一、为什么 RAG 系统需要可观测性?
RAG 系统通常包含多个组件:用户 Query 接收、向量检索、上下文拼接、LLM 推理、结果返回。任一环节出问题,都可能导致“答非所问”或“响应超时”,而这些问题在黑盒系统中极难定位。
- 用户问:“为什么昨天能答,今天答不了?”
- 运维问:“是检索没召回?还是 LLM 崩了?”
- SRE 问:“P99 延迟飙升,瓶颈在哪?”
没有可观测性,RAG 就是“薛定谔的智能”——你永远不知道它是否真的在工作。
二、日志:记录关键路径,还原用户行为
日志是可观测性的基础。在 RAG 系统中,应至少记录以下三类信息:
- 原始 Query:用户输入的完整问题(脱敏后)。
- 检索结果:Top-K 文档 ID、相似度分数、原始文本片段。
- 生成答案:LLM 输出内容及所用 Prompt。
建议采用结构化日志(如 JSON 格式),便于后续分析:
{
"trace_id": "a1b2c3d4",
"query": "如何重置系统密码?",
"retrieved_docs": [
{"doc_id": "doc_789", "score": 0.92, "content": "..."},
{"doc_id": "doc_456", "score": 0.87, "content": "..."}
],
"generated_answer": "请进入恢复模式,执行 passwd 命令...",
"timestamp": "2025-10-26T10:00:00Z"
}
关键点:所有日志必须携带 trace_id,这是后续链路追踪的“身份证”。
三、指标:量化系统健康度
仅靠日志无法快速发现趋势性问题。我们需要指标(Metrics)来实时监控系统状态。RAG 系统的核心指标包括:
|
指标 |
说明 |
告警阈值建议 |
|
P99 延迟 |
99% 请求的端到端耗时 |
>2s |
|
召回率 |
检索返回非空结果的比例 |
<95% |
|
缓存命中率 |
向量/答案缓存命中比例 |
<80% |
|
LLM 超时率 |
LLM 推理超时请求占比 |
>1% |
这些指标可通过 Prometheus 采集,配合业务代码埋点实现。例如在 Go 中:
histogram := prometheus.NewHistogramVec(
prometheus.HistogramOpts{
Name: "rag_request_duration_seconds",
Help: "RAG request latency",
Buckets: prometheus.DefBuckets,
},
[]string{"stage"}, // stage: retrieval, llm, total
)
四、分布式追踪:看清请求全链路
RAG 请求横跨多个服务(API 网关 → 检索服务 → LLM 服务),分布式追踪是定位性能瓶颈的利器。
我们采用 OpenTelemetry(OTel)作为标准协议,实现跨服务的上下文传递。
上下文传递的关键:Span 与 TraceID
- 每个请求生成唯一
trace_id。 - 每个处理阶段(如检索、LLM)创建一个
span,并继承父上下文。 - 通过 HTTP Header(如
traceparent)在服务间透传上下文。
// 在检索服务入口
ctx := otel.GetTextMapPropagator().Extract(r.Context(), propagation.HeaderCarrier(r.Header))
spanCtx, span := tracer.Start(ctx, "retrieval")
defer span.End()
这样,一次用户请求的所有操作都会被串联成一条完整的 Trace。
五、告警:主动发现问题
可观测性不只是“事后分析”,更要“事前预警”。建议配置以下两类告警:
- 检索为空告警:连续 5 分钟召回率 < 90%,可能向量库异常或 Query 预处理出错。
- LLM 超时告警:单小时内超时请求 > 10 次,可能模型负载过高或网络抖动。
告警可通过 Prometheus Alertmanager 或 Grafana Alerting 实现,通知渠道包括企业微信、钉钉、邮件等。
六、可视化:Grafana 一图看透全局
将日志、指标、Trace 统一接入 Grafana,构建专属 RAG 运维看板。
一个典型的 Dashboard 应包含:
- 延迟热力图:展示 P50/P95/P99 趋势。
- 召回率曲线:按小时统计检索成功率。
- Trace 搜索入口:点击可跳转 Jaeger 查看详情。
- 错误日志流:实时滚动显示异常请求。
下图展示了 RAG 请求在系统中的完整流转路径及可观测性埋点位置: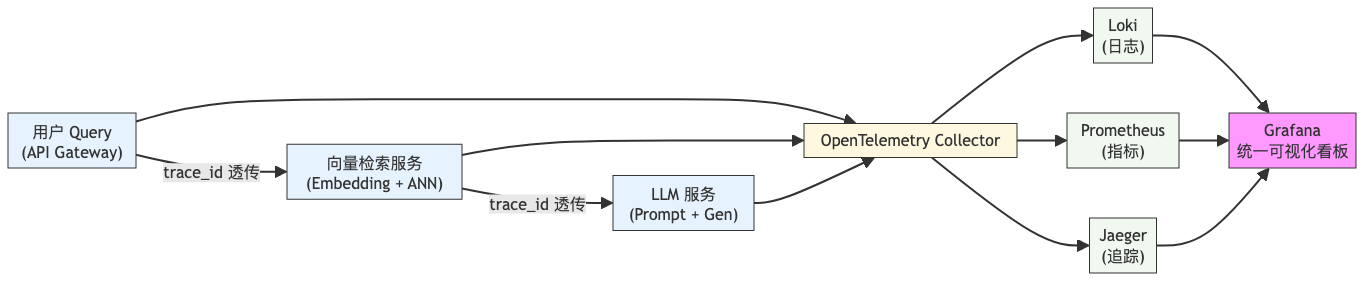
该图清晰展示了从用户请求到数据汇聚再到可视化呈现的全链路,所有组件通过 trace_id 关联,实现“一查到底”。
七、实战:在 Jaeger 中查看一次 RAG Trace
假设用户发起请求:“OS 如何升级内核?”
- 系统生成
trace_id = abc123。 - API 服务记录日志并启动 Span A。
- 调用检索服务,透传
traceparent头,启动 Span B(耗时 120ms)。 - 检索返回 3 篇文档,调用 LLM 服务,启动 Span C(耗时 850ms)。
- 最终返回答案,总耗时 980ms。
在 Jaeger UI 中搜索 abc123,即可看到如下结构:
RAG Request (abc123)
├── /query (API) — 10ms
├── retrieval — 120ms
│ ├── embedding — 30ms
│ └── ann_search — 90ms
└── llm_generate — 850ms
任何一段异常耗时都会高亮显示,帮助 SRE 快速定位是向量检索慢,还是 LLM 推理卡顿。
八、总结:三位一体,构建可信 RAG
要让 RAG 系统真正“透明可运维”,必须做到:
- 日志结构化:记录 Query、检索、生成三要素,带 trace_id。
- 指标量化:监控延迟、召回率、缓存命中率等核心指标。
- 追踪全链路:通过 OpenTelemetry 实现跨服务上下文传递。
- 告警前置化:对空检索、LLM 超时等异常主动告警。
- 可视化统一:Grafana 聚合 Logs/Metrics/Traces,一屏掌控全局。
可观测性不是附加功能,而是 RAG 系统上线的“准入证”。只有当每个请求都可追溯、每个指标都可解释、每个异常都可预警,我们才能真正信任 AI 给出的答案。
本文适用于 SRE、运维工程师及后端开发者。如果你正在将 RAG 投入生产,不妨从今天开始,为你的系统装上“透明之眼”。

















 1237
1237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









