









2019 刘知远/孙茂松团队
ERNIE: Enhanced Language Representation with Informative Entities
paper:https://arxiv.org/pdf/1905.07129.pdf
code:https://github.com/thunlp/ERNIE
KG中rich structured knowledge能够帮助跟好的理解句子,但是目前的预训练语言模型基本上都只考虑了rich semantic patterns。于是,本文结合text和KG训练了一个enhanced language representation model (ERNIE)。
要融合text和KG将会面临两个主要挑战:
- Structured Knowledge Encoding:如何编码text中的实体相关的结构化信息?
- Heterogeneous Information Fusion: text和KG的信息如何融合?
简要概括:
- 整个模型包括两个模块:Knowedge module和semantic module,ERNIE将Knowedge module中实体相关信息集成到semantic module的底层中。TransE 算法获得实体向量。(针对第1个挑战)
- 训练任务和bert一样包括两个:masked language model 和 the next sentence prediction。需要强调,在mask任务上,为了能够更好的融合KG和text,文章除了考虑mask一些token进行预测外,还考虑了mask掉entities (针对第2个挑战)
- 测试任务包括两个:entity typing 和 relation classification
方法:
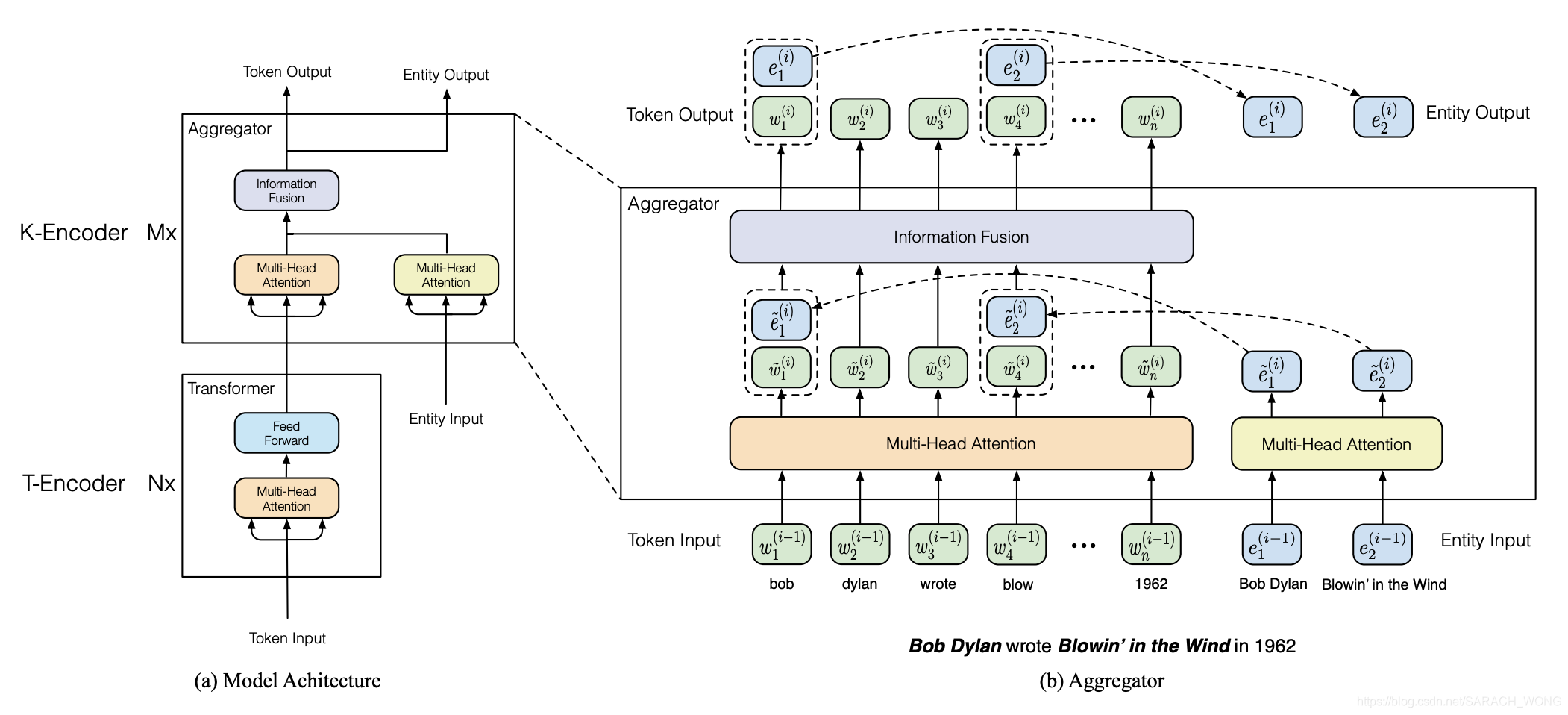
- token sequence: w 1 , w 2 , . . . , w n {w_1,w_2,...,w_n} w1,w2,...,wn
- entity sequence: e 1 , e 2 , . . . , e m {e_1,e_2,...,e_m} e1,e2,...,em, 如何链接到实体?,从模型图中可以看到将实体对齐到了第一个token上
Knowledgeable Encoder
- 先MH-ATT处理token和entity
- $$ \{\tilde{w}_1^{(i)},...,\tilde{w}_n^{(i)} \} = MH\_ATT(\{\tilde{w}_1^{(i-1)},...,\tilde{w}_n^{(i-1)} \})\\ \{\tilde{e}_1^{(i)},...,\tilde{e}_m^{(i)} \} = MH\_ATT(\{\tilde{e}_1^{(i-1)},...,\tilde{e}_m^{(i-1)} \}) $$
- 之后分两部分处理:
- 针对有entity的token 和 entity:
- $$\begin{aligned} \boldsymbol{h}_{j} &=\sigma\left(\tilde{\boldsymbol{W}}_{t}^{(i)} \tilde{\boldsymbol{w}}_{j}^{(i)}+\tilde{\boldsymbol{W}}_{e}^{(i)} \tilde{\boldsymbol{e}}_{k}^{(i)}+\tilde{\boldsymbol{b}}^{(i)}\right) \\ \boldsymbol{w}_{j}^{(i)} &=\sigma\left(\boldsymbol{W}_{t}^{(i)} \boldsymbol{h}_{j}+\boldsymbol{b}_{t}^{(i)}\right) \\ \boldsymbol{e}_{k}^{(i)} &=\sigma\left(\boldsymbol{W}_{e}^{(i)} \boldsymbol{h}_{j}+\boldsymbol{b}_{e}^{(i)}\right) \end{aligned}$$
- 针对没有entity的token:
- $$\begin{aligned} \boldsymbol{h}_{j} &=\sigma\left(\tilde{\boldsymbol{W}}_{t}^{(i)} \tilde{\boldsymbol{w}}_{j}^{(i)}+\tilde{\boldsymbol{b}}^{(i)}\right) \\ \boldsymbol{w}_{j}^{(i)} &=\sigma\left(\boldsymbol{W}_{t}^{(i)} \boldsymbol{h}_{j}+\boldsymbol{b}_{t}^{(i)}\right) \end{aligned}$$
- 简化成:
- $$ \{w_1^{(i)},...,w_n^{(i)} \} ,\{e_1^{(i)},...,e_m^{(i)} \} =Aggregator(\{w_1^{(i-1)},...,w_n^{(i-1)} \} ,\{e_1^{(i-1)},...,e_m^{(i-1)} \} )$$
Pre-training for Injecting Knowledge
任务定义为知道tokens预测对齐的entity:
p
(
e
j
∣
w
i
)
=
e
x
p
(
l
i
n
e
a
r
(
w
i
o
)
⋅
e
j
)
∑
k
=
1
m
e
x
p
(
l
i
n
e
a
r
(
w
i
o
)
⋅
e
k
)
p(e_j|w_i) = \frac{exp(linear(w_i^o)\cdot e_j) }{\sum_{k=1}^mexp(linear(w_i^o)\cdot e_k)}
p(ej∣wi)=∑k=1mexp(linear(wio)⋅ek)exp(linear(wio)⋅ej)
如果预测到所有实体上,会面临搜索空间大的问题,因此本文给定了一个实体序列。
实体对齐的时候会有两个问题:1)token对齐到了entity上,但是有错误;2)token没有对齐到entity上。对这个问题,文章的将训练划分:1)5%的时间,随机替换到对齐的实体,这是针对第一个问题;2)15%的时间,mask掉了对齐的实体,针对第二个问题;3)其余时间正常训练。
整体损失包括:dEA + MLM + NSP。1)MLM:masked language model;2)NSP:next sentence prediction;3)dEA:denoising entity auto-encoder,本小节上面所述的。
fine-tune for
三个任务:1)2)relation classfication:3) entity typing
两个问题:1)拿几个实体相关的triple;2)token对应多个entity,EL问题














 1503
1503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









