









 本文探讨了知识图谱在推荐系统中的应用,对比分析了KGCN、KGAT及RGCN三种方法。KGCN利用GCN聚合邻居信息,KGAT引入注意力机制,而RGCN则处理关系型数据。实验表明,这些方法能有效提升推荐效果。
本文探讨了知识图谱在推荐系统中的应用,对比分析了KGCN、KGAT及RGCN三种方法。KGCN利用GCN聚合邻居信息,KGAT引入注意力机制,而RGCN则处理关系型数据。实验表明,这些方法能有效提升推荐效果。
文章目录
- KGCN: Knowledge Graph Convolutional Networks for Recommender Systems
- KGAT: Knowledge Graph Attention Network for Recommendation
- RGCN:Modeling Relational Data with Graph Convolutional Networks
- [待看] Heterogeneous Graph Attention Network
- [待看] GraphRec:Graph Neural Networks for Social Recommendation
- KGCN vs KGAT vs RGCN
[截图的公式好丑呀…有时间改下…]
一般分为xxxxx
KGCN: Knowledge Graph Convolutional Networks for Recommender Systems
www2019
本文利用kg的结构(structure)信息和语义(semantic)信息来提高推荐的效果。受到gcn的启发,提出KGCN( Knowledge Graph Convolutional Networks),KGCN核心跟GCN一样,都是通过将a邻居结点的信息传播到结点a上(想到了概率图模型中的belief)。这样设计有两个好处1)通过聚合操作,每个实体能够捕获到( local proximity structure)局部近似结构,
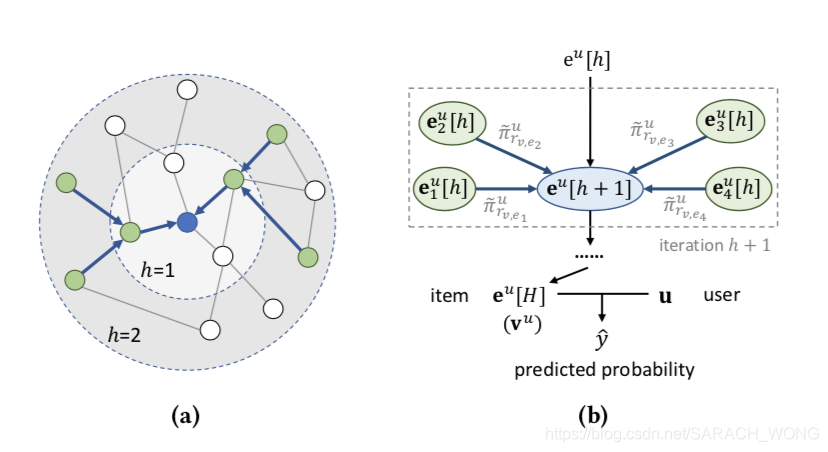
方法
文章将entity u u u和item v v v中对齐,因此后面可以当作同样的理解。
Propagation
π r u = g ( u , r ) \pi_{r}^{u}=g(\mathbf{u}, \mathbf{r}) πru=g(u,r)
π ~ r v , e u = exp ( π r v , e u ) ∑ e ∈ N ( v ) exp ( π r v , e u ) A ˚ \tilde{\pi}_{r_{v}, e}^{u}=\frac{\exp \left(\pi_{r_{v}, e}^{u}\right)}{\sum_{e \in \mathcal{N}(v)} \exp \left(\pi_{r_{v, e}}^{u}\right)}Å π~rv,eu=∑e∈N(v)exp(πrv,eu)exp(πrv,eu)A˚
v N ( v ) u = ∑ e ∈ N ( v ) π ~ r v , e u e \mathbf{v}_{\mathcal{N}(v)}^{u}=\sum_{e \in \mathcal{N}(v)} \tilde{\pi}_{r_{v}, e}^{u} \mathbf{e} vN(v)u=e∈N(v)∑π~rv,eue
π
r
v
\pi_r^v
πrv:relation
r
r
r对 user
u
u
u 的重要性,作用等同于个性化过滤(personalized filters)
N
(
v
)
N(v)
N(v) :直接和entity/item
v
v
v 关联的entity集合;
v
S
(
v
)
u
v_{S(v)}^u
vS(v)u: 用户
v
v
v邻居的表示
考虑到对不同的 e e e, N ( e ) N(e) N(e)的数量变化很大,文章为每个实体均匀采样了固定大小的邻居 S ( e ) S(e) S(e)而不是用它全部的邻居,如下, k k k表示了一层感知域的范围。
S ( v ) ≜ { e ∣ e ∼ N ( v ) } and ∣ S ( v ) ∣ = K \mathcal{S}(v) \triangleq\{e | e \sim \mathcal{N}(v)\} \text { and }|\mathcal{S}(v)|=K S(v)≜{e∣e∼N(v)} and ∣S(v)∣=K
聚合(aggregate)过程
提出了三种聚合实体 v v v和邻居 S ( v ) S(v) S(v)的方法:
- Sum aggregator
a g g s u m = σ ( W ⋅ ( v + v S ( v ) u ) + b ) agg_{s u m}=\sigma\left(\mathbf{W} \cdot\left(\mathbf{v}+\mathbf{v}_{\mathcal{S}(v)}^{u}\right)+\mathbf{b}\right) aggsum=σ(W⋅(v+vS(v)u)+b)
-
Concat aggregator
a g g concat = σ ( W ⋅ concat ( v , v S ( v ) u ) + b ) agg_{\text {concat }}=\sigma\left(\mathbf{W} \cdot \operatorname{concat}\left(\mathbf{v}, \mathbf{v}_{\mathcal{S}(v)}^{u}\right)+\mathbf{b}\right) aggconcat =σ(W⋅concat(v,vS(v)u)+b) -
Neighbor aggregator
a g g n e i g h b o r = σ ( W ⋅ v S ( v ) u + b ) agg_{neighbor}=\sigma\left(\mathbf{W} \cdot \mathbf{v}_{\mathcal{S}(v)}^{u}+\mathbf{b}\right) aggneighbor=σ(W⋅vS(v)u+b)
预测目标
表示用户u将会engage(可以理解为喜好)商品v的程度。
Y
Y
Y是交互历史。
y
^
u
v
=
F
(
u
,
v
∣
Θ
,
Y
,
G
)
\hat{y}_{u v}=\mathcal{F}(u, v | \Theta, \mathrm{Y}, \mathcal{G})
y^uv=F(u,v∣Θ,Y,G)
损失函数
这里loss的计算考虑了负采样的策略。
J
J
J表示交叉熵,每个<u,v>采样的数量
T
u
T^u
Tu取决于原始的<u,v>的历史交互次数
T
u
=
∣
v
:
y
u
v
=
1
∣
T^u=|{v:y_{uv}=1}|
Tu=∣v:yuv=1∣,
P
P
P是采样的分布,文中服从均匀分布。
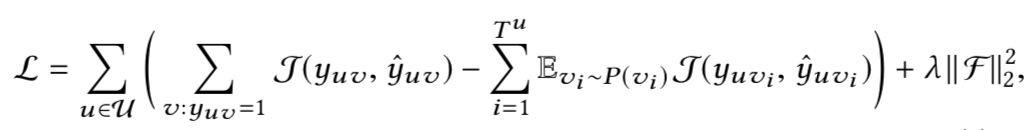
伪码

实验
方法在 MovieLens-20M (movie), Book-Crossing (book), and Last.FM (music).三个数据集上进行测试。其中的items和KG的数据集Microsoft Satori中的entity进行对齐。对齐过程中,如果出现匹配到多个或者没有匹配到的,就不做考虑。
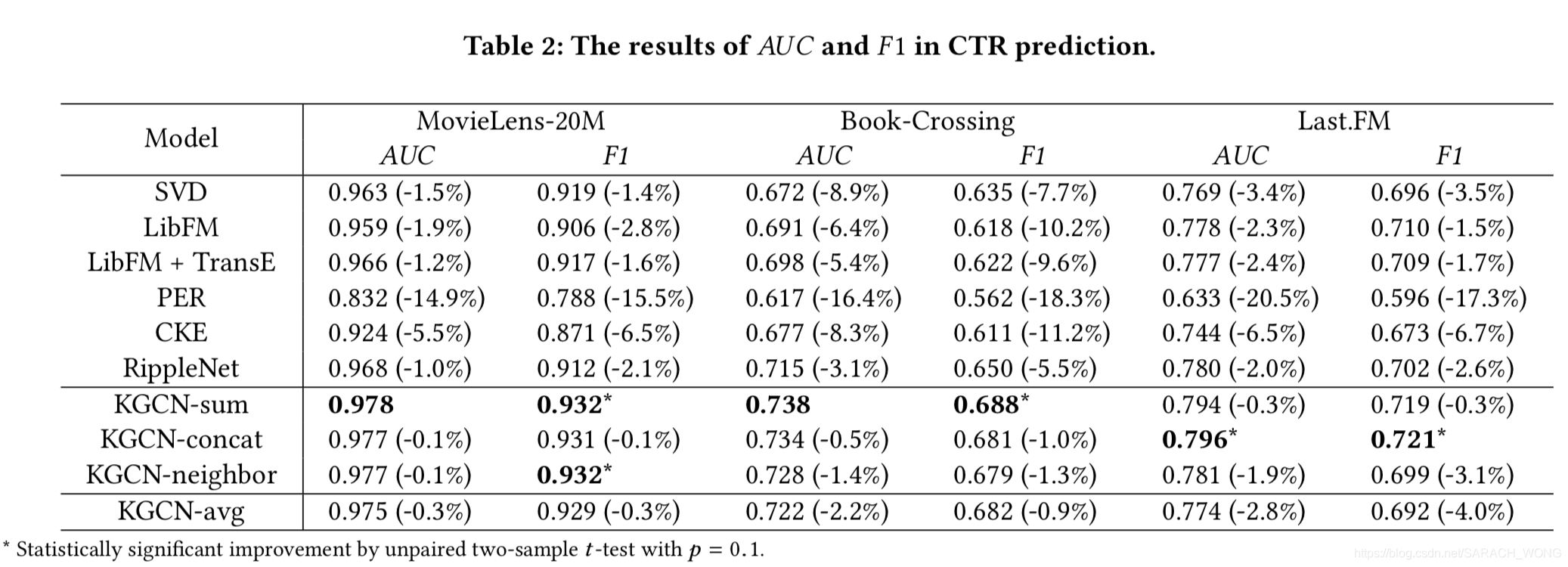
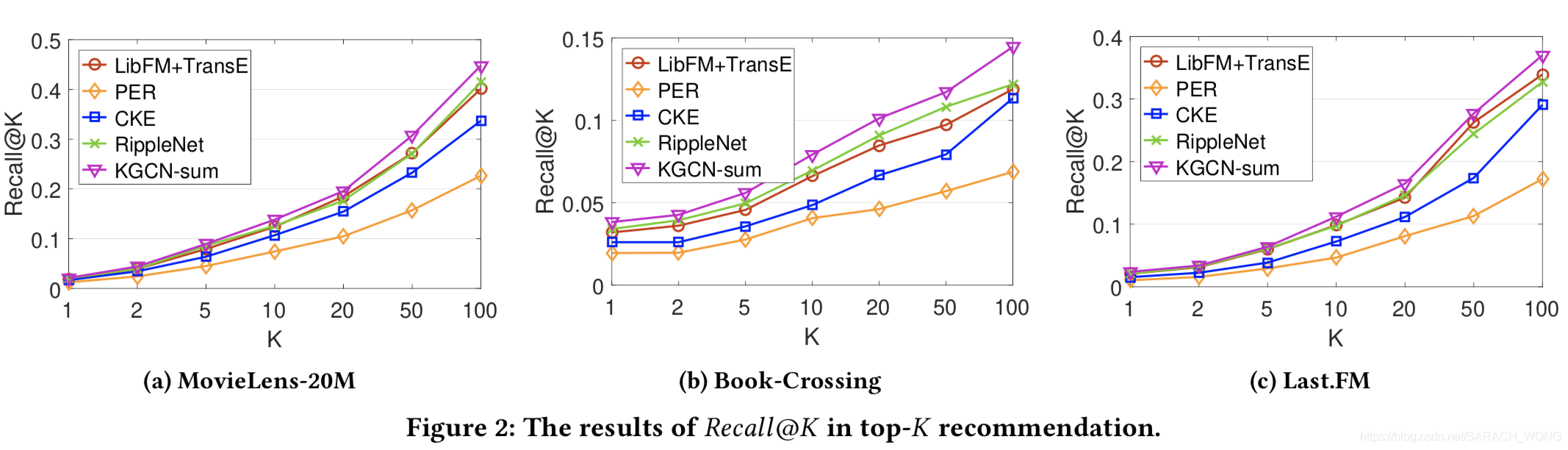
邻居结点采样数量的影响
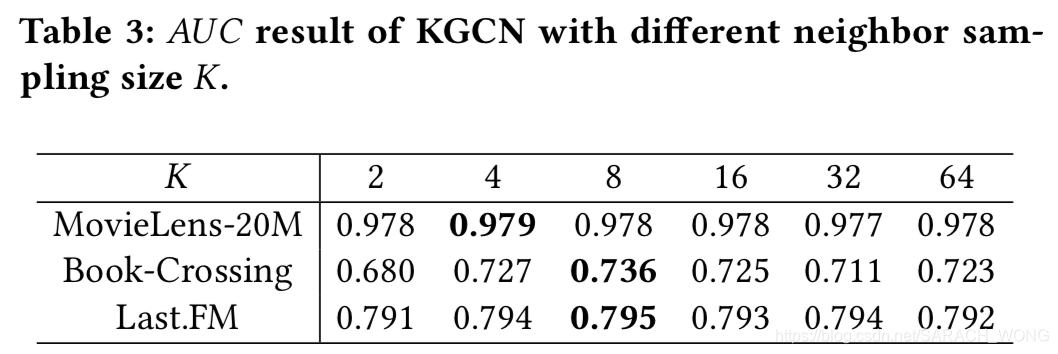
迭代次数的影响
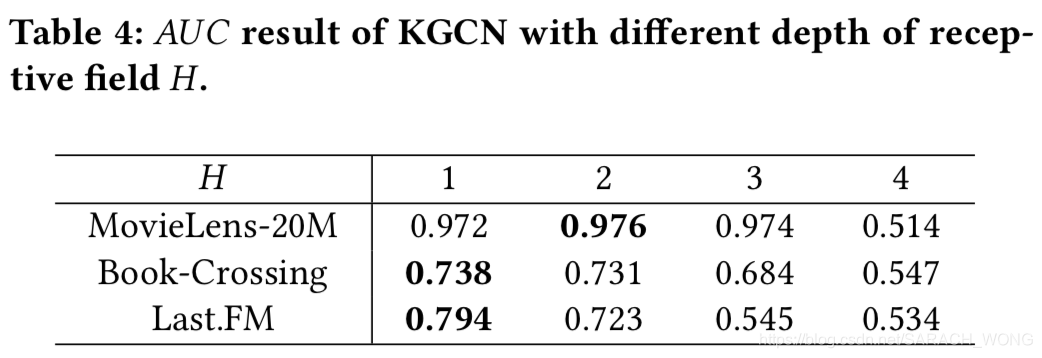
embedding维度的影响
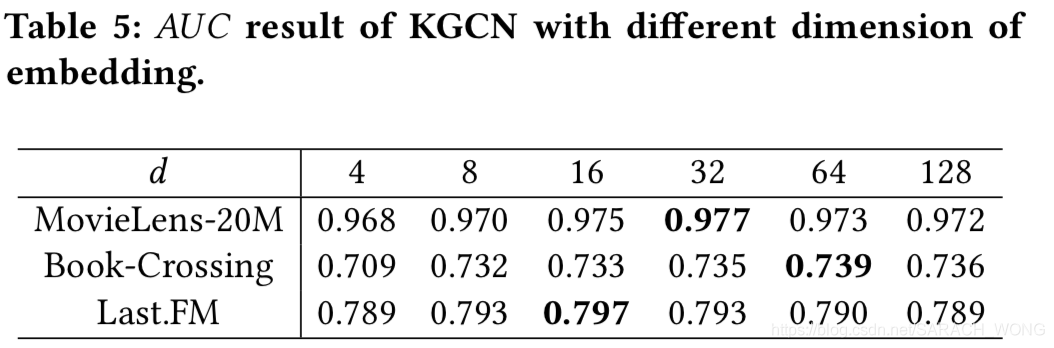
其他
困惑
- 是第一次利用kg+gcn的吗?是的
- 这里不太明白为什么能够捕获到这种结构信息? (咨询了一个做图模型的同学,他的回答是,因为捕获到了邻居的信息,这种信息称之为结构信息)
- 如果基于kg,这样的邻接矩阵不会特别大吗?(文中针对每个用户抽取sub-KG,因此邻接矩阵会很大)
- 文章中说到采样得到固定的邻居,怎么采的?(在后续有说明)
- 更新过程中的计算权重部分,u表示怎么得到的???
tips
- 文章提到了几篇处理邻居结点数量不定/变化的情况,在related work中可以找到。
KGAT: Knowledge Graph Attention Network for Recommendation
KDD2019,August 4–8, 2019: https://arxiv.org/pdf/1905.07854.pdf
github: https://github.com/xiangwang1223/knowledge_graph_attention_network
Tat-Seng Chua团队的,资深做推荐。包括
- Explainable Reasoning over Knowledge Graphs for Recommendation. In AAAI2019.
- Unifying Knowledge Graph Learning and Recommendation: Towards a Better Understanding of User Preferences. In WWW 2019
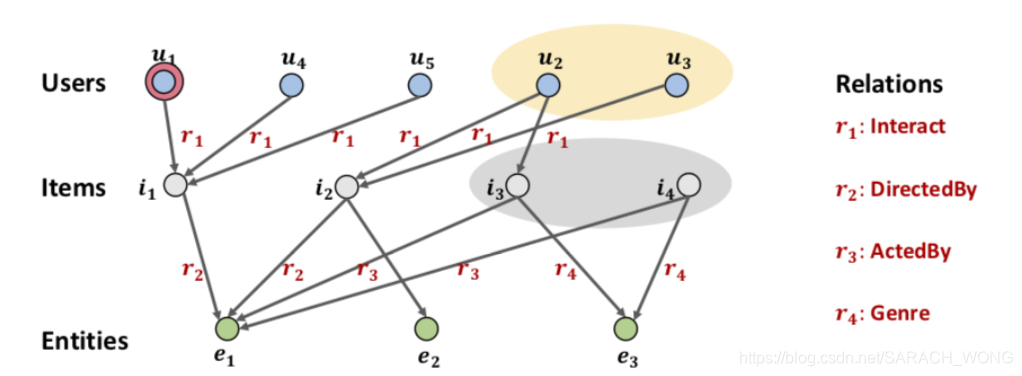
黄色部分和灰色部分通过KGAT方式可以发现相关但是传统方式捕获不到。
之前利用CKG的论文可以分为两种:
1)Path-based方式,抽取一些路径去训练模型,相当于两个阶段,因此第一个阶段路径的抽取对最后的性能有很大的影响。另外抽取path是 labor-intensive。
2)Regularization-based 方式主要是在loss中加入了跟kg相关的部分去捕获KG结构信息。这种方式encode kg的方式比较implicit,因此“neither the long-range connectivities are guaranteed to be captured, nor the results of high-order modeling are interpretable.”
因此提出Knowledge Graph Attention Network (KGAT),“ a model that can exploit high-order information in KG in an efficient, explicit, and end-to-end manner.”
方法
- User-Item Bipartite Graph: 将历史交互信息构建bipartite graph G 1 G1 G1
- KG: G 2 G2 G2
- CKG: G = G 1 + G 2 G = G1+ G2 G=G1+G2 , 通过match entity和item 将 G 1 G1 G1, G 2 G2 G2合并成 G G G
- embedding: 在CKG上用TransR训练
GCN的整个过程分为Information Propagation和Information Aggregation
- Information Propagation
h h h能够的邻居结点 N h N_h Nh中获取到的信息:
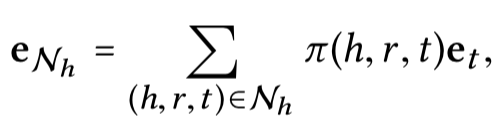
Knowledge-aware Attention的计算过程
1) 利用TransR计算embedding表示

2.)计算attention
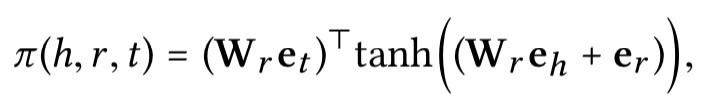
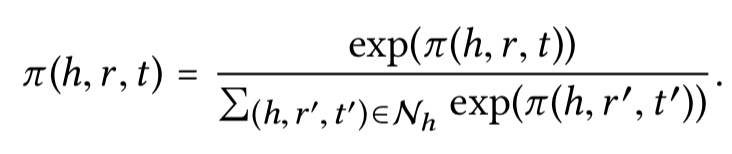
- Information Aggregation
三种聚合方式:- GCN Aggregator (和上面的Sum aggregator的激活函数不同)
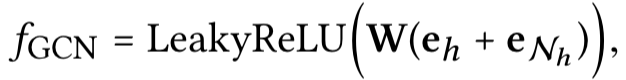
- GraphSage Aggregator (和上面的Concact aggregator的激活函数不同)
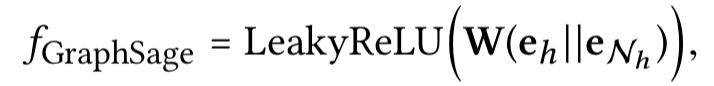
- Bi-Interaction Aggregator
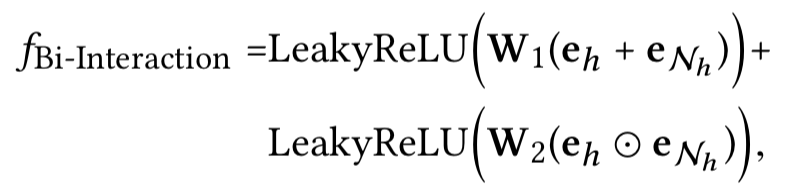
- GCN Aggregator (和上面的Sum aggregator的激活函数不同)
将上述传递,扩展到多跳:(直接看公式就是加了层次的上标
(
l
)
(l)
(l))
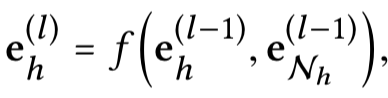
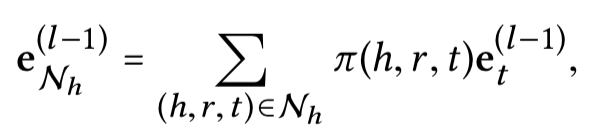
3. prediction
各层拼接作为最终表示:

预测:
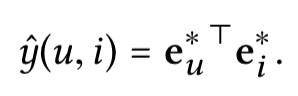
4. loss: BPR loss
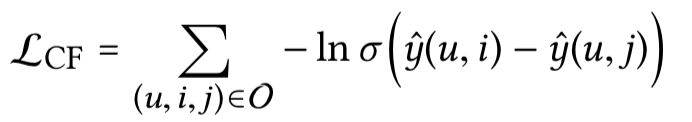
其中,
O
=
{
(
u
,
i
,
j
)
∣
(
u
,
i
)
∈
R
+
,
(
u
,
j
)
∈
R
−
}
O = \{(u,i,j)|(u,i) ∈ R^+,(u,j) ∈ R^−\}
O={(u,i,j)∣(u,i)∈R+,(u,j)∈R−},
R
−
R^−
R−表示历史记录中跟user
u
u
u没有交互记录的item
j
j
j。
(负采样的时候,被采样的是跟用户没有交互的item,但是并不表示用户dislike这些,应该是考虑到item量大…?反正交互稀疏?)
所以怎样的训练是合理的?原始的训练方式
实验设置&数据集
- 推荐数据集:Amazon-book,Last-FM,Yelp2018。
- Amazon-book,Last-FM 中的item跟FB中的实体对齐。除对齐之外,还考虑了2-hop的邻居进行扩展。
- 对于Yelp2018,从文本( local business information network )中抽取 (e.g., category, location, and attribute) 作为KG。
- 为了保证质量,过滤掉KG中entity出现次数小于阈值(10次)的数据
- 简单交叉验证:80%,10%,10%,随机选取。
结果
- 在三个数据集的整体结果,KGAT的方式比其他的方式好

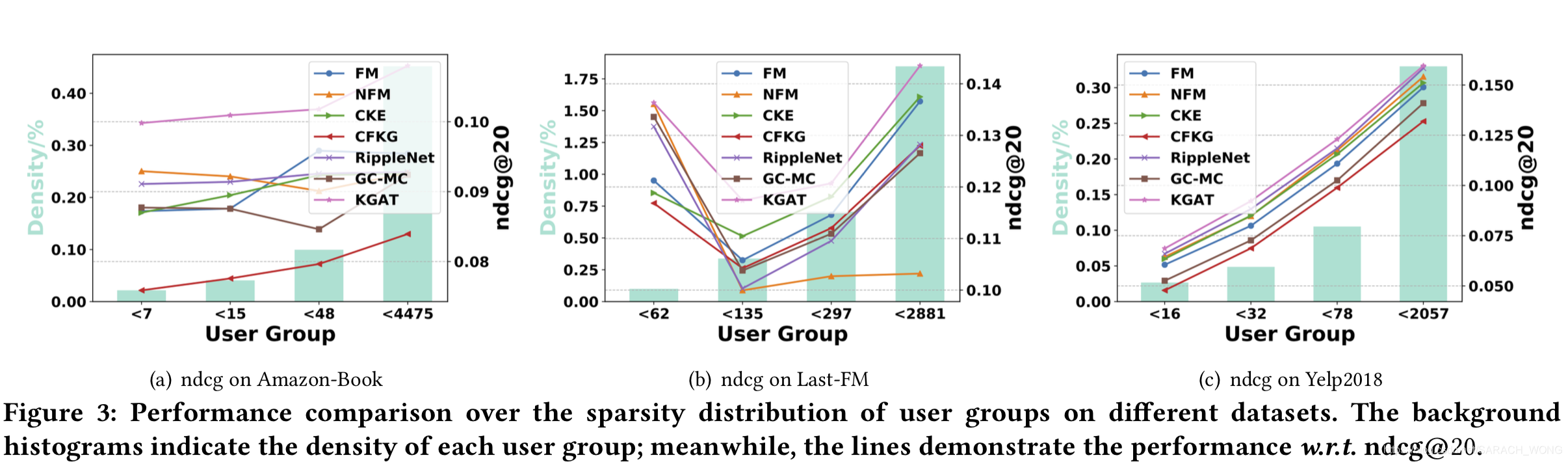
- 递归次数的影响
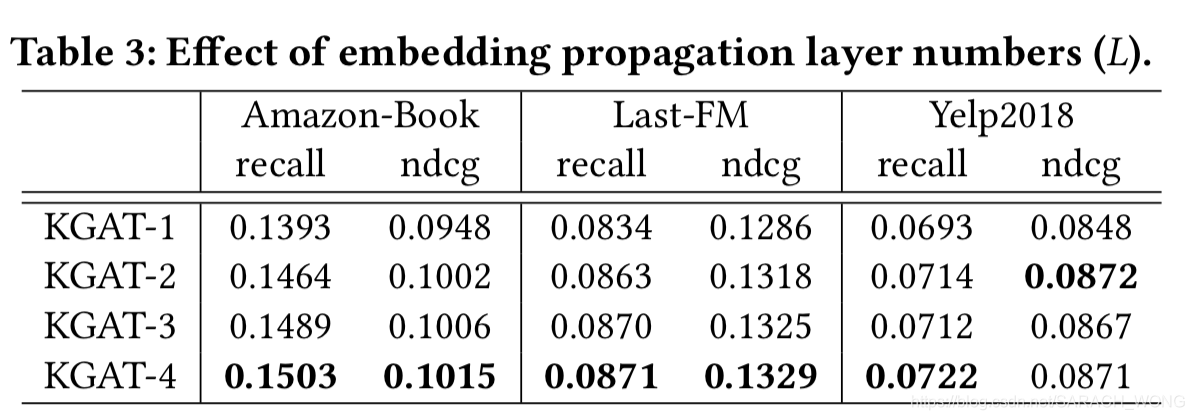
- 聚合方式的影响
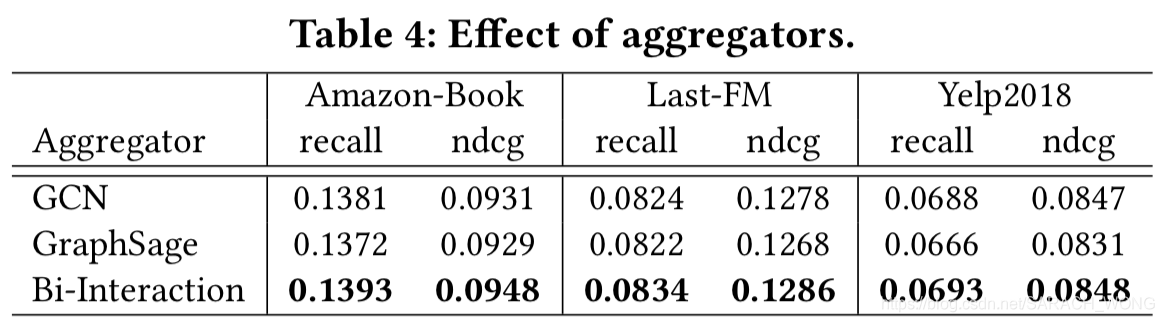
- attention的影响,第一行去掉KG emb用平均的传递方式,第二种是去掉KGE
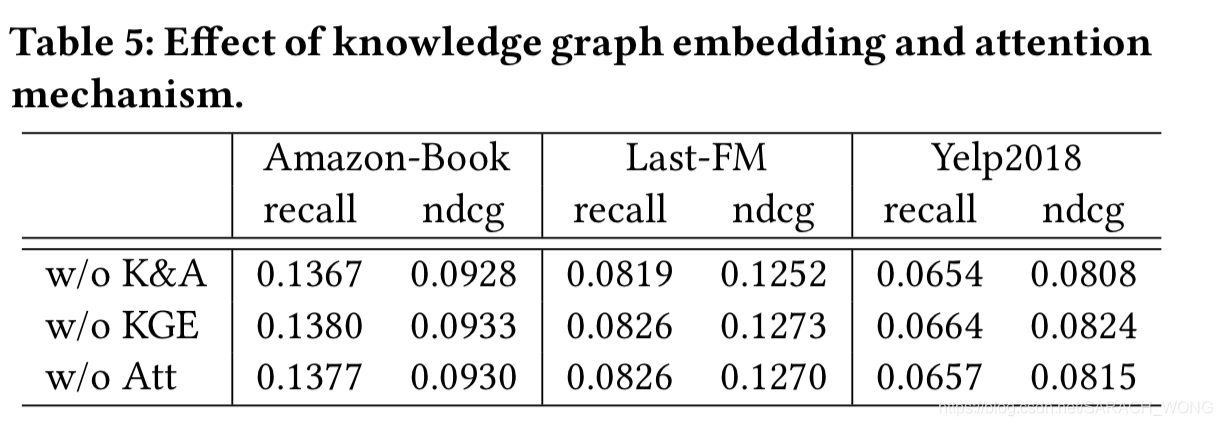
- 可解释
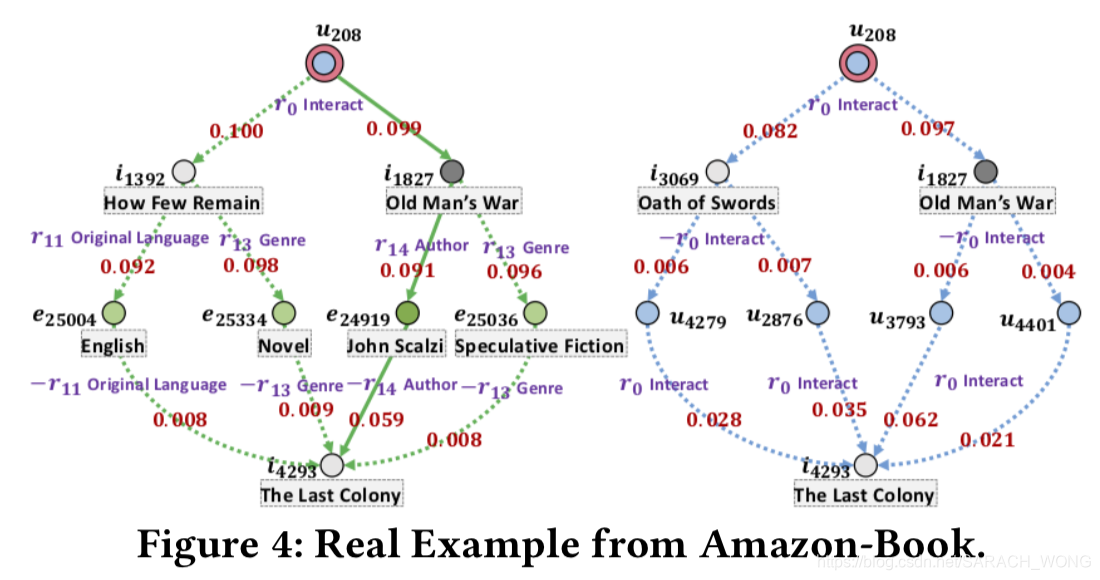
RGCN:Modeling Relational Data with Graph Convolutional Networks
https://arxiv.org/pdf/1703.06103.pdf, 2018
Propagation+ Aggregation
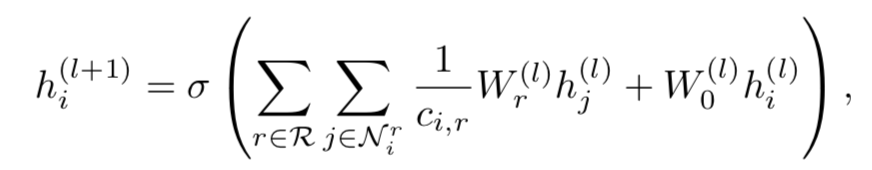
[待看] Heterogeneous Graph Attention Network
https://arxiv.org/pdf/1903.07293.pdf
[待看] GraphRec:Graph Neural Networks for Social Recommendation
https://arxiv.org/pdf/1902.07243.pdf
KGCN vs KGAT vs RGCN
KGCN:
- 场景:推荐
- 针对每个用户,抽取不同图结构。
- 利用GCN的方式,不同用户对不同relation会有不同的计算不同weight。
| RGCN | KGCN | KGAT | |
|---|---|---|---|
| 场景 | KGE | RS | RS |
| 思路 | 给不同relation不同权重 | 不同用户对不同relation会有不同的计算不同weight,为每个用抽取sub-KG | 将user-item的交互和KG信号放在一张图中 |
| attention | —— |  | 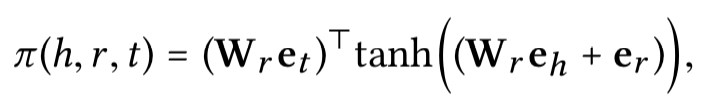 |
| 传播 | 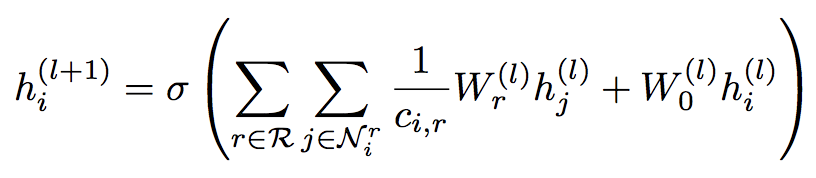 | 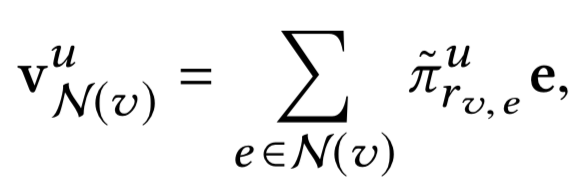 | 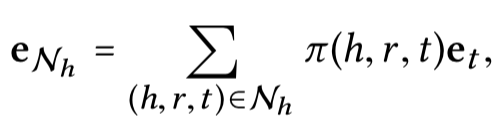 |
RS:推荐
KGE:kg embedding

















 1207
1207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









