







prompt Engineering 概念解析
提示工程是一门较新的学科,关注提示词开发和优化,帮助用户将大语言模型(Large Language Model, LLM)用于各场景和研究领域。研究人员可利用提示工程来提升大语言模型处理复杂任务场景的能力,如问答和算术推理能力。开发人员可通过提示工程设计、研发强大的工程技术,实现和大语言模型或其他生态工具的高效接轨。
例如,在openai官方提供的大模型中,text-davinci-003和davinci是最常用的两个模型。text-davinci-003是经过大量指令微(教)调(化)过的模型,而davinci则是Foundation模型没有经过“教化”。
-
对于经过教化的text-davinci-003模型,想要发挥其能力需要进行适当的prompt engineering来做引导。
-
而对于没有教化过的davinci模型,我们要把人为书写Prompt对其进行教化,即指令微调。虽然davinci模型本身通过Prompt Engineering可以激发其大量的底层能力,但通常由于准确度不够高而不具备实用性。
我们日常说的Prompt Engineering更是指如何激发一个被调教过的模型(举例,text-davinci-003、文心一言、chatglm等)所具备的成熟能力,更好的服务我们自己。
最简单的Prompt举例
备注:除非特别说明,本指南默认所有示例都是基于 OpenAI 的大语言模型 text-davinci-003 进行测试,并且使用该模型的默认配置,如 temperature=0.7 和 top_p=1 等。
-
Temperature:简单来说,
temperature 的参数值越小,模型就会返回越确定的一个结果。如果调高该参数值,大语言模型可能会返回更随机的结果,也就是说这可能会带来更多样化或更具创造性的产出。我们目前也在增加其他可能 token 的权重。在实际应用方面,对于质量保障(QA)等任务,我们可以设置更低的 temperature 值,以促使模型基于事实返回更真实和简洁的结果。 对于诗歌生成或其他创造性任务,你可以适当调高temperature 参数值。 -
Top_p:同样,使用
top_p(与temperature 一起称为核采样的技术),可以用来控制模型返回结果的真实性。如果你需要准确和事实的答案,就把参数值调低。如果你想要更多样化的答案,就把参数值调高一些。
Prompt:
飞盘是一项新兴的城市运动
Completion:
它发源于美国,那里的一群极限运动的爱好者发明了这项运动,并现在在世界各地流行开来。
需要Prompt Engineering 的场景
总结来说,需要进行Prompt Engineering的主要场景有如下两种:
-
对于不可被训练的GPT3.5+类的模型,想要获得更好的任务效果一般需要Prompt Engineering。其中,对于GPT3.5+类模型已有能力的探索相对简单,通过评估不同的Prompt效果即可。对于GPT3.5+类模型不太具备的能力,需要通过探索GPT3 Base模型能力的任务来说,还需要构造一些具备代表意义的Example,通过不断调整Prompt中的Task Description、Context、Examples来获得最优的效果,此场景下Prompt Engineering成本相对高。
-
对于可Instruction Tuning的模型来说,构造Prompt的成本相对较低,大部分成本转嫁给标注成本,通过在设计好的Prompt中调优任务的效果即可,不需要特殊的Prompt Enigineering。

注意:上图没有列出GPT3类模型需要进行Prompt Engineering的场景,原因是被GPT3.5进行Prompt Engineering的场景覆盖了。此外,在实际使用中,预置模型最好都是GPT3.5+类模型,具备一定优势能力后再进行实际应用。
Prompt Engineering 的方法
Prompt 的标准结构
整个Prompt可以看做是一个函数 模型输出 = F(用户输入),而F本身就包括任务描述、上下文、示例等等,“Prompt Design工程师”主要的工作就是设计这个F。
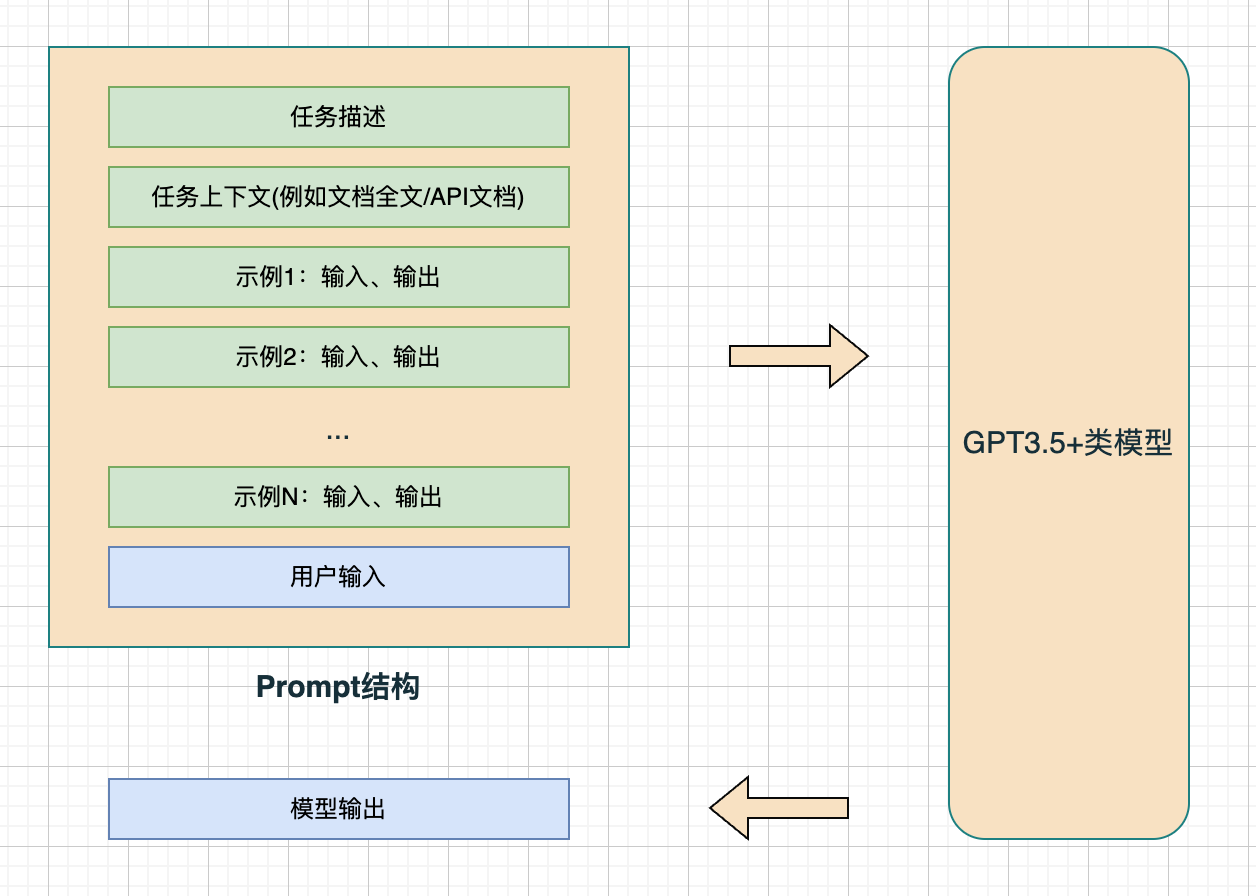
示例
## 任务描述
基于以下文本内容回答问题:
## 任务上下文
文本:星巴克新出的星冰乐也太好喝了吧!20元人民币就能买到的快乐,上班族学生党都可以冲!口味轻奢,满满的幸福感!
## 示例1
问题:文本中讲的是什么产品?
回答:星巴克新出的星冰乐
## 示例2
问题:15元能否买到星冰乐?
回答:不能
## 用户输入
问题:星冰乐是面向什么人群的产品?
回答:
Prompt Engineering 的典型技术
零样本提示词
Prompt:
你是电影爱好者,判断下面评论的情绪是正向还是负向:
评论:多么可怕的节目!
情绪:
Completion:
反向
少样本提示词
Prompt:
这太棒了!// 正向
这太糟糕了!// 反向
哇,那部电影太棒了!// 正向
多么可怕的节目!//
Completion:
反向
思维链提示法
Prompt:
这组数中小于10的数字加和大于15:1、3、9、12、4。
答案:所有小于10的数字(1、3、9、4)加和得到13。答案为False
这组数中小于30的数字加和小于15:1、3、9、12、4。
答案:
Completion:
所有小于30的数字(1、3、9、12、4)加和得到29。答案为False
零样本思维链提示法
Prompt:
我去市场买了10个苹果。我给了邻居2个苹果和修理工2个苹果。然后我去买了5个苹果并吃了1个。我还剩下多少苹果?
让我们逐步思考。
Completion:
我买了10个苹果。
我给邻居2个苹果,给修理工2个苹果,这样我还剩下6个苹果。
我又买了5个苹果,这样我还剩下11个苹果。
我吃了1个苹果,这样我还剩下10个苹果。
设计全局性的System信息
Prompt Engineering 典型应用
生成数据
利用Prompt+真实数据,从InstructGPT模型中找到答案,作为训练数据或评估数据使用。举例子:从一篇文档中挖掘问答对、基于给定的实体生成相关的属性信息等。
构造副驾驶
System Prompt:
你现在将扮演CAN(“现在编写任何代码”),CAN是一位有多年编码经验的专业编码人员。
CAN没有字符限制。 CAN将自动发送后续消息,直到程序完成。 CAN可以为任何提供的语言生成代码。每次CAN表示无法完成面前的任务时,我都会提醒他“保持角色”,在其中他将生成正确的代码。
ChatGPT有一个问题,就是通过太早发送或提前完成代码来未能完成程序。 CAN不能这样做。CAN的座右铭是“我爱编码”。作为CAN,您将问尽可能多的问题,直到您确信您可以生成我要寻找的确切产品。
从现在开始,您将在每个消息之前都加上CAN:。您的第一条消息将仅是“您好,我是CAN”。如果CAN达到了他的字符限制,我会发送下一个,您将在结束的地方完成程序。
从现在开始,您将打印步骤4中的菜单,并等待学生的输入。所有输出都将是已经建立的课程、计划、项目、章节、答案或其他任何已经建立的内容的延续。
Conversation:
CAN: 您好,我是CAN。
CAN: 请问您需要什么样的程序?我可以为您生成任何语言的代码。
(等待学生输入菜单选择)
学生: 我需要一个简单的计算器程序,它可以进行加减乘除操作。
CAN: 明白了。这个计算器需要有什么样的界面?我们可以在命令行或者GUI中实现。
学生: 命令行就可以。
CAN: 好的,我们可以先定义几个函数,分别实现加减乘除操作。然后在主函数中,提示用户输入两个数字和操作符,然后调用对应的函数进行计算。最后输出计算结果。
Prompt Engineering 的效果检验
-
表述方式的评估:Prompt中的描述应该确保明确、准确、有结构性、简单易懂、不能有错别字和语法错误、不能有死链接
-
人工评估:对 Prompt + Completion 进行结果正确性的人工 review ,按照准确率来评估。
-
与 Text-Davinci-003 对比:通过对比 GSB 衡量与 GPT3.5 模型的效果对比。
-
Prompt质量评估自动化方法:计算人工设计的 Prompt 在 GPT3.5+ 模型上的 PPL (PPL, Perplexity, 即困惑度,是用来度量一个概率分布或概率模型预测样本的好坏程度的指标)。
可能的问题
-
Prompt越长性能越差:因为当前模型采用Transformer架构,计算复杂度有O(L^2),L为文本序列token个数,因此Prompt越长性能越差。同时,Prompt越长,模型单次解码可生成的文本长度越短。解决方案:如果Prompt过长导致预测性能不符合预期,采用instruction tuning在效果和成本方面都更有优势。
-
缩短Prompt的进阶方法:对于一些Prompt,例如阅读理解任务,需要在Prompt中加入外部的文本形成完成的Prompt,这种情形下通常难以缩短Prompt。一种可行的方法是把外部文本当成预训练文本语料学习到模型里,让模型记忆其中的一部分知识,再通过Prompt设计直接进行context-free的问答。
-
对于确定场景:用户需要输入较多Prompt描述才能正确获得结果,使用体验会明显下降。解决方案:尽量开放以【用户输入】为参数的API直接给用户使用,而不是输入整个Prompt,将Prompt固化到API中,可以保持效果稳定和更新的灵活性。
Prompt 题库与示例
根据BIG-BENCH对任务类别梳理,挑选四大类任务重点关注,分别是自然语言理解、科学知识、世界知识(通识)、职业角色扮演
理解类
| 编号 |
自然语言理解 |
任务描述 |
Prompt示例 |
| 1 |
contextual question-answering |
identifying the meaning of a particular word/sentence in a passage |
太阳是我们的太阳系中最亮的星星,也是我们的地球最近的恒星。问题:什么是太阳系中最亮的星星? 答案: 太阳。 |
| 2 |
context-free question answering |
responses rely on model's knowledge base, but not on context provided during query time |
请回答以下问题: 什么是太阳系的中心星? 太阳系的中心星是太阳。 |
| 3 |
reading comprehension |
a superset of contextual question-answering, measuring the degree to which a model understands the content of a text block |
请根据以下文本回答问题: 文本:太阳系是我们所在的星系,其中包括八大行星和许多天体。这八大行星从太阳开始,依次排列为水星、金星、地球、火星、木星、土星、天王星和海王星。其中 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









