







 本文详细探讨了MapReduce的处理流程,并通过一个实际案例解释如何实现Hadoop的二次排序。在Map端,通过自定义组合键将原始数据转化为适配排序的新结构;在Reduce端,按照组合键的第一个字段进行分组并处理。作者强调理解MapReduce基础对解决问题的重要性,并通过日志分析验证了处理流程的正确性。同时,文中指出网络上关于MapReduce的资料可能存在错误,提倡实践验证和深入理解。
本文详细探讨了MapReduce的处理流程,并通过一个实际案例解释如何实现Hadoop的二次排序。在Map端,通过自定义组合键将原始数据转化为适配排序的新结构;在Reduce端,按照组合键的第一个字段进行分组并处理。作者强调理解MapReduce基础对解决问题的重要性,并通过日志分析验证了处理流程的正确性。同时,文中指出网络上关于MapReduce的资料可能存在错误,提倡实践验证和深入理解。
一、概述
MapReduce框架对处理结果的输出会根据key值进行默认的排序,这个默认排序可以满足一部分需求,但是也是十分有限的,在我们实际的需求当中,往往有要对reduce输出结果进行二次排序的需求。对于二次排序的实现,网络上已经有很多人分享过了,但是对二次排序的实现原理及整个MapReduce框架的处理流程的分析还是有非常大的出入,而且部分分析是没有经过验证的。本文将通过一个实际的MapReduce二次排序的例子,讲述二次排序的实现和其MapReduce的整个处理流程,并且通过结果和Map、Reduce端的日志来验证描述的处理流程的正确性。
二、需求描述
1.输入数据
sort1 1
sort2 3
sort2 88
sort2 54
sort1 2
sort6 22
sort6 888
sort6 582.目标输出
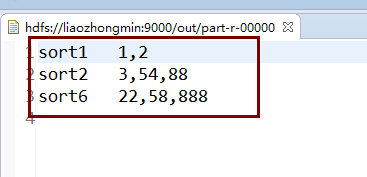
sort1 1,2
sort2 3,54,88
sort6 22,58,888 三、解决思路
1.首先,在思考解决问题思路时,我们应该先深刻的理解MapReduce处理数据的整个流程,这是最基础的,不然的话是不可能找到解决问题的思路的。我描述一下MapReduce处理数据的大概流程:首先,MapReduce框架通过getSplits()方法实现对原始文件的切片之后,每一个切片对应着一个MapTask,InputSplit输入到map()函数进行处理,中间结果经过环形缓冲区的排序,然后分区、自定义二次排序(如果有的话)和合并,再通过Shuffle操作将数据传输到reduce Task端,reduce端也存在着缓冲区,数据也会在缓冲区和磁盘中进行合并排序等操作,然后对数据按照key值进行分组,然后每处理完一个分组之后就会去调用一次reduce()函数,最终输出结果。大概流程 我画了一下,如下图:
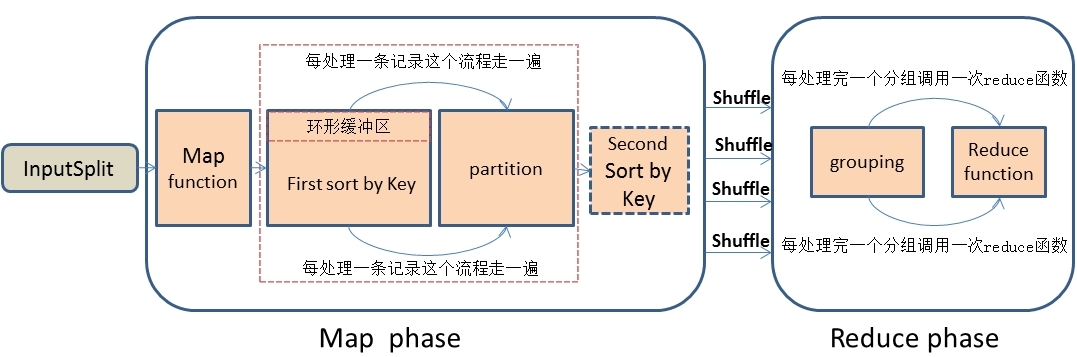
2.具体解决思路
(1):Map端处理
根据上面的需求,我们有一个非常明确的目标就是要对第一列相同的记录,并且对合并后的数字进行排序。我们都知道MapReduce框架不管是默认排序或者是自定义排序都只是对key值进行排序,现在的情况是这些数据不是key值,怎么办?其实我们可以将原始数据的key值和其对应的数据组合成一个新的key值,然后新的key值对应的value还是原始数据中的valu。那么我们就可以将原始数据的map输出变成类似下面的数据结构:
{[sort1,1],1}
{[sort2,3],3}
{[sort2,88],88}
{[sort2,54],54}
{[sort1,2],2}
{[sort6,22],22}
{[sort6,888],888}
{[sort6,58],58} 那么我们只需要对[]里面的心key值进行排序就OK了,然后我们需要自定义一个分区处理器,因为我的目标不是想将新key相同的记录传到一个reduce中,而是想将新key中第一个字段相同的记录放到同一个reduce中进行分组合并,所以我们需要根据新key值的第一个字段来自定义一个分区处理器。通过分区操作后,得到的数据流如下:
Partition1:{[sort1,1],1}、{[sort1,2],2}
Partition2:{[sort2,3],3}、{[sort2,88],88}、{[sort2,54],54}
Partition3:{[sort6,22],22}、{[sort6,888],888}、{[sort6,58],58} {[sort1,1],1}
{[sort1,2],2}
{[sort2,3],3}
{[sort2,54],54}
{[sort2,88],88}
{[sort6,22],22}
{[sort6,58],58}
{[sort6,888],888} (2).Reduce端处理
经过Shuffle处理之后,数据传输到Reducer端了。在Reducer端按照组合键的第一个字段进行分组,并且每处理完一次分组之后就会调用一次reduce函数来对这个分组进行处理和输出。最终各个分组的数据结果变成类似下面的数据结构:
sort1 1,2
sort2 3,54,88
sort6 22,58,888 四、具体实现
1.自定义组合键
public class CombinationKey implements WritableComparable<CombinationKey>{
private Text firstKey;
private IntWritable secondKey;
//无参构造函数
public CombinationKey() {
this.firstKey = new Text();
this.secondKey = new IntWritable();
}
//有参构造函数
public CombinationKey(Text firstKey, IntWritable secondKey) {
this.firstKey = firstKey;
this.secondKey = secondKey;
}
public Text getFirstKey() {
return firstKey;
}
public void setFirstKey(Text firstKey) {
this.firstKey = firstKey;
}
public IntWritable getSecondKey() {
return secondKey;
}
public void setSecondKey(IntWritable secondKey) {
this.secondKey = secondKey;
}
public void write(DataOutput out) throws IOException {
this.firstKey.write(out);
this.secondKey.write(out);
}
public void readFields(DataInput in) throws IOException {
this.firstKey.readFields(in);
this.secondKey.readFields(in);
}
/*public int compareTo(CombinationKey combinationKey) {
int minus = this.getFirstKey().compareTo(combinationKey.getFirstKey());
if (minus != 0){
return minus;
}
return this.getSecondKey().get() - combinationKey.getSecondKey().get();
}*/
/**
* 自定义比较策略
* 注意:该比较策略用于MapReduce的第一次默认排序
* 也就是发生在Map端的sort阶段
* 发生地点为环形缓冲区(可以通过io.sort.mb进行大小调整)
*/
public int compareTo(CombinationKey combinationKey) {
System.out.println("------------------------CombineKey flag-------------------");
return this.firstKey.compareTo(combinationKey.getFirstKey());
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((firstKey == null) ? 0 : firstKey.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
CombinationKey other = (CombinationKey) obj;
if (firstKey == null) {
if (other.firstKey != null)
return false;
} else if (!firstKey.equals(other.firstKey))
return false;
return true;
}
} 说明:在自定义组合键的时候,我们需要特别注意,一定要实现WritableComparable接口,并且实现compareTo()方法的比较策略。这个用于MapReduce的第一次默认排序,也就是发生在Map阶段的sort小阶段,发生地点为环形缓冲区(可以通过io.sort.mb进行大小调整),但是其对我们最终的二次排序结果是没有影响的,我们二次排序的最终结果是由我们的自定义比较器决定的。
2.自定义分区器
/**
* 自定义分区
* @author 陈伟
* @version
*/
public class DefinedPartition extends Partitioner<CombinationKey, IntWritable>{
/**
* 数据输入来源:map输出 我们这里根据组合键的第一个值作为分区
* 如果不自定义分区的话,MapReduce会根据默认的Hash分区方法
* 将整个组合键相等的分到一个分区中,这样的话显然不是我们要的效果
* @param key map输出键值
* @param value map输出value值
* @param numPartitions 分区总数,即reduce task个数
*/
public int getPartition(CombinationKey key, IntWritable value, int numPartitions) {
System.out.println("---------------------进入自定义分区---------------------");
System.out.println("---------------------结束自定义分区---------------------");
return (key.getFirstKey().hashCode() & Integer.MAX_VALUE) % numPartitions;
}
} 3.自定义比较器
public class DefinedComparator extends WritableComparator{
protected DefinedComparator() {
super(CombinationKey.class,true);
}
/**
* 第一列按升序排列,第二列也按升序排列
*/
public int compare(WritableComparable a, WritableComparable b) {
System.out.println("------------------进入二次排序-------------------");
CombinationKey c1 = (CombinationKey) a;
CombinationKey c2 = (CombinationKey) b;
int minus = c1.getFirstKey().compareTo(c2.getFirstKey());
if (minus != 0){
System.out.println("------------------结束二次排序-------------------");
return minus;
} else {
System.out.println("------------------结束二次排序-------------------");
return c1.getSecondKey().get() -c2.getSecondKey().get();
}
}
} /**
* 自定义分组有中方式,一种是继承WritableComparator
* 另外一种是实现RawComparator接口
* @author 陈伟
* @version
*/
public class DefinedGroupSort extends WritableComparator{
protected DefinedGroupSort() {
super(CombinationKey.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
System.out.println("---------------------进入自定义分组---------------------");
CombinationKey combinationKey1 = (CombinationKey) a;
CombinationKey combinationKey2 = (CombinationKey) b;
System.out.println("---------------------分组结果:" + combinationKey1.getFirstKey().compareTo(combinationKey2.getFirstKey()));
System.out.println("---------------------结束自定义分组---------------------");
//自定义按原始数据中第一个key分组
return combinationKey1.getFirstKey().compareTo(combinationKey2.getFirstKey());
}
}
public class SecondSortMapReduce {
// 定义输入路径
private static final String INPUT_PATH = "hdfs://liaozhongmin:9000/sort_data";
// 定义输出路径
private static final String OUT_PATH = "hdfs://liaozhongmin:9000/out";
public static void main(String[] args) {
try {
// 创建配置信息
Configuration conf = new Configuration();
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, "\t");
// 创建文件系统
FileSystem fileSystem = FileSystem.get(new URI(OUT_PATH), conf);
// 如果输出目录存在,我们就删除
if (fileSystem.exists(new Path(OUT_PATH))) {
fileSystem.delete(new Path(OUT_PATH), true);
}
// 创建任务
Job job = new Job(conf, SecondSortMapReduce.class.getName());
//1.1 设置输入目录和设置输入数据格式化的类
FileInputFormat.setInputPaths(job, INPUT_PATH);
job.setInputFormatClass(KeyValueTextInputFormat.class);
//1.2 设置自定义Mapper类和设置map函数输出数据的key和value的类型
job.setMapperClass(SecondSortMapper.class);
job.setMapOutputKeyClass(CombinationKey.class);
job.setMapOutputValueClass(IntWritable.class);
//1.3 设置分区和reduce数量(reduce的数量,和分区的数量对应,因为分区为一个,所以reduce的数量也是一个)
job.setPartitionerClass(DefinedPartition.class);
job.setNumReduceTasks(1);
//设置自定义分组策略
job.setGroupingComparatorClass(DefinedGroupSort.class);
//设置自定义比较策略(因为我的CombineKey重写了compareTo方法,所以这个可以省略)
job.setSortComparatorClass(DefinedComparator.class);
//1.4 排序
//1.5 归约
//2.1 Shuffle把数据从Map端拷贝到Reduce端。
//2.2 指定Reducer类和输出key和value的类型
job.setReducerClass(SecondSortReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//2.3 指定输出的路径和设置输出的格式化类
FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
job.setOutputFormatClass(TextOutputFormat.class);
// 提交作业 退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
public static class SecondSortMapper extends Mapper<Text, Text, CombinationKey, IntWritable>{
/**
* 这里要特殊说明一下,为什么要将这些变量写在map函数外边
* 对于分布式的程序,我们一定要注意到内存的使用情况,对于MapReduce框架
* 每一行的原始记录的处理都要调用一次map()函数,假设,这个map()函数要处理1一亿
* 条输入记录,如果将这些变量都定义在map函数里面则会导致这4个变量的对象句柄
* 非常的多(极端情况下将产生4*1亿个句柄,当然java也是有自动的GC机制的,一定不会达到这么多)
* 导致栈内存被浪费掉,我们将其写在map函数外面,顶多就只有4个对象句柄
*/
private CombinationKey combinationKey = new CombinationKey();
Text sortName = new Text();
IntWritable score = new IntWritable();
String[] splits = null;
protected void map(Text key, Text value, Mapper<Text, Text, CombinationKey, IntWritable>.Context context) throws IOException, InterruptedException {
System.out.println("---------------------进入map()函数---------------------");
//过滤非法记录(这里用计数器比较好)
if (key == null || value == null || key.toString().equals("")){
return;
}
//构造相关属性
sortName.set(key.toString());
score.set(Integer.parseInt(value.toString()));
//设置联合key
combinationKey.setFirstKey(sortName);
combinationKey.setSecondKey(score);
//通过context把map处理后的结果输出
context.write(combinationKey, score);
System.out.println("---------------------结束map()函数---------------------");
}
}
public static class SecondSortReducer extends Reducer<CombinationKey, IntWritable, Text, Text>{
StringBuffer sb = new StringBuffer();
Text score = new Text();
/**
* 这里要注意一下reduce的调用时机和次数:
* reduce每次处理一个分组的时候会调用一次reduce函数。
* 所谓的分组就是将相同的key对应的value放在一个集合中
* 例如:<sort1,1> <sort1,2>
* 分组后的结果就是
* <sort1,{1,2}>这个分组会调用一次reduce函数
*/
protected void reduce(CombinationKey key, Iterable<IntWritable> values, Reducer<CombinationKey, IntWritable, Text, Text>.Context context)
throws IOException, InterruptedException {
//先清除上一个组的数据
sb.delete(0, sb.length());
for (IntWritable val : values){
sb.append(val.get() + ",");
}
//取出最后一个逗号
if (sb.length() > 0){
sb.deleteCharAt(sb.length() - 1);
}
//设置写出去的value
score.set(sb.toString());
//将联合Key的第一个元素作为新的key,将score作为value写出去
context.write(key.getFirstKey(), score);
System.out.println("---------------------进入reduce()函数---------------------");
System.out.println("---------------------{[" + key.getFirstKey()+"," + key.getSecondKey() + "],[" +score +"]}");
System.out.println("---------------------结束reduce()函数---------------------");
}
}
}
程序运行的结果:
五、处理流程
看到前面的代码,都知道我在各个组件上已经设置好了相应的标志,用于追踪整个MapReduce处理二次排序的处理流程。现在让我们分别看看Map端和Reduce端的日志情况。
(1)Map端日志分析
15/01/19 15:32:29 INFO input.FileInputFormat: Total input paths to process : 1
15/01/19 15:32:29 WARN snappy.LoadSnappy: Snappy native library not loaded
15/01/19 15:32:30 INFO mapred.JobClient: Running job: job_local_0001
15/01/19 15:32:30 INFO mapred.Task: Using ResourceCalculatorPlugin : null
15/01/19 15:32:30 INFO mapred.MapTask: io.sort.mb = 100
15/01/19 15:32:30 INFO mapred.MapTask: data buffer = 79691776/99614720
15/01/19 15:32:30 INFO mapred.MapTask: record buffer = 262144/327680
---------------------进入map()函数---------------------
---------------------进入自定义分区---------------------
---------------------结束自定义分区---------------------
---------------------结束map()函数---------------------
---------------------进入map()函数---------------------
---------------------进入自定义分区---------------------
---------------------结束自定义分区---------------------
---------------------结束map()函数---------------------
---------------------进入map()函数---------------------
---------------------进入自定义分区---------------------
---------------------结束自定义分区---------------------
---------------------结束map()函数---------------------
---------------------进入map()函数---------------------
---------------------进入自定义分区---------------------
---------------------结束自定义分区---------------------
---------------------结束map()函数---------------------
---------------------进入map()函数---------------------
---------------------进入自定义分区---------------------
---------------------结束自定义分区---------------------
---------------------结束map()函数---------------------
---------------------进入map()函数---------------------
---------------------进入自定义分区---------------------
---------------------结束自定义分区---------------------
---------------------结束map()函数---------------------
---------------------进入map()函数---------------------
---------------------进入自定义分区---------------------
---------------------结束自定义分区---------------------
---------------------结束map()函数---------------------
---------------------进入map()函数---------------------
---------------------进入自定义分区---------------------
---------------------结束自定义分区---------------------
---------------------结束map()函数---------------------
15/01/19 15:32:30 INFO mapred.MapTask: Starting flush of map output
------------------进入二次排序-------------------
------------------结束二次排序-------------------
------------------进入二次排序-------------------
------------------结束二次排序-------------------
------------------进入二次排序-------------------
------------------结束二次排序-------------------
------------------进入二次排序-------------------
------------------结束二次排序-------------------
------------------进入二次排序-------------------
------------------结束二次排序-------------------
------------------进入二次排序-------------------
------------------结束二次排序-------------------
------------------进入二次排序-------------------
------------------结束二次排序-------------------
------------------进入二次排序-------------------
------------------结束二次排序-------------------
------------------进入二次排序-------------------
------------------结束二次排序-------------------
------------------进入二次排序-------------------
------------------结束二次排序-------------------
------------------进入二次排序-------------------
------------------结束二次排序-------------------
------------------进入二次排序-------------------
------------------结束二次排序-------------------
15/01/19 15:32:30 INFO mapred.MapTask: Finished spill 0
15/01/19 15:32:30 INFO mapred.Task: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
15/01/19 15:32:30 INFO mapred.LocalJobRunner:
15/01/19 15:32:30 INFO mapred.Task: Task 'attempt_local_0001_m_000000_0' done.
15/01/19 15:32:30 INFO mapred.Task: Using ResourceCalculatorPlugin : null
15/01/19 15:32:30 INFO mapred.LocalJobRunner: (2)Reduce端日志分析
六、总结
本文主要从MapReduce框架执行的流程,去分析了如何去实现二次排序,通过代码进行了实现,并且对整个流程进行了验证。另外,要吐槽一下,网络上有很多文章都记录了MapReudce处理二次排序问题,但是对MapReduce框架整个处理流程的描述错漏很多,而且他们最终的流程描述也没有证据可以支撑。所以,对于网络上的学习资源不能够完全依赖,要融入自己的思想,并且要重要的观点进行代码或者实践的验证。另外,今天在一个Hadoop交流群上听到少部分人在讨论,有了Hive我们就不用学习些MapReduce程序?对这这个问题我是这么认为:我不相信写不好MapReduce程序的程序员会写好hive语句,最起码的他们对整个执行流程是一无所知的,更不用说性能问题了,有可能连最常见的数据倾斜问题的弄不清楚。















 2527
2527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









