







group by 子句的细节
GROUP BY子句主要用于对WHERE中得到的结果进行分组,也就是说它是在WHERE子句之后执行,对经过WHERE筛选后的结果按照某些列进行分组,之后进行相应的处理工作。
普通用法:
例如:显示部门平均工资的最大值
select max(avg(sal)) “部门平均工资的最大值”
from emp
group by deptno;
在select子句中出现的非多行函数的所有列,【必须】出现在group by子句中
例如:
select avg(sal) “部门平均工资的最大值”,deptno “部门编号”, mgr “领导”
from emp
group by deptno, mgr; deptno、mgr 就必须出现在group子句中
结果:
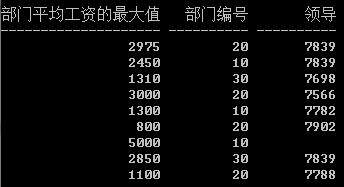
是不是笛卡尔集的知识在里面呢???
在group by子句中出现的所有列,【可出现可不现】在select子句中
还是上面的那个,avg(sal)就没有出现在group by子句中
聚集函数使用
当使用聚集函数的时候,除非对整个语句的查询结果集进行聚集运算,否则都要通过指定GROUP BY子句来确定是对某类结果集进行聚集运算
例如:
select owner,status,count(object_name) num from t; 错误
为什么错呢?
这是因为查询结果表中owner和status列下都有多条数据, 而count(object_name) 就是一条数据, 这样在形成结果表时, 就不对称了!!! 所以错误。
因此我们可以分完组后再进行聚集,即指定GROUP BY子句来确定是对某类结果集进行聚集运算
上面那条语句可以改成这样:
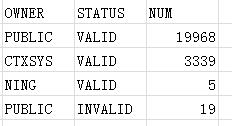
select owner,status,count(object_name) num from t group by owner,status; //也印证了前面两条细节
查询结果:
group by子句的限制
1)你不能在子句中使用LOB/VARRAYS/NESTED TABLE。
2)子句中的表达式不能是子查询语句
3)如果GROUP BY中引用了对象类型列,则这个查询就不能使用并行。
having
having也是对数据进行筛选的,不过他和where是有区别的。
where和having的区别:
where:
1)行过滤器
2)针对原始的记录
3)跟在from后面
4)where可省
5)先执行
having:
1)组过滤器
2)针对分组后的记录
3)跟在group by后面
4)having可省
5)后执行















 1546
1546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









