







最近上网络服务系统的课,对于一个只具备基本的TCP/IP知识的开发人员来说,算是新知识了。只是老师上课照本宣科,真心没听明白前因后果。于是面对下面这道复习题,只好自己到网上找资料了。
先贴题目吧:
画出m=4的带弦Chord环的示意图,图中实际存在的节点NodeID分别为0、3、11、14,试:
(1) 给出每个节点的finger table;
(2) 描述NodeID为5的新节点从节点11发起加入网络的过程;
网上有一篇极好的资料,摘录如下:
P2P的一个常见问题是如何高效的定位节点,也就是说,一个节点怎样高效的知道在网络中的哪个节点包含它所寻找的数据,如下图:
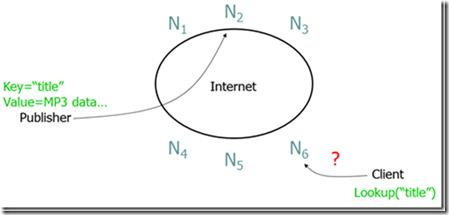
对此,有三种比较典型的来解决这个问题。
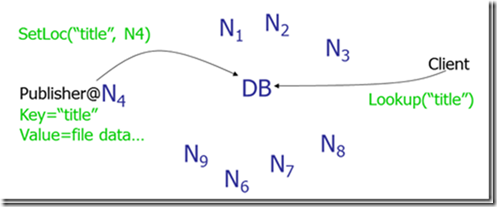
Napster:使用一个中心服务器接收所有的查询,服务器告知去哪下载其所需要的数据。存在的问题是中心服务器单点失效导致整个网络瘫痪。
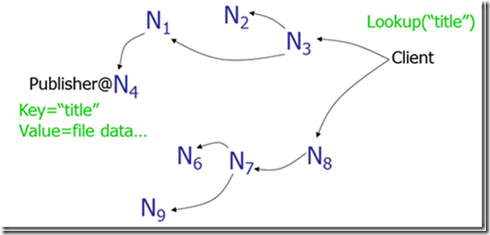
Gnutella:使用消息洪泛(message flooding)来定位数据。一个消息被发到系统内每一个节点,直到找到其需要的数据为止。当然,使用生存时间(TTL)来限制网络内转发消息的数量。存在的问题是消息数与节点数成线性关系,导致网络负载较重。
SN型:现在大多数采用所谓超级节点(Super Node),SN保存网络中节点的索引信息,这一点和中心服务器类型一样,但是网内有多个SN,其索引信息会在这些SN中进行传播,所以整个系统的崩溃几率就会小很多。尽管如此,网络还是有崩溃的可能。
现在的研究结果中,Chord、Pastry、CAN和Tapestry等常用于构建结构化P2P的分布式哈希表系统(Distributed Hash Table,DHT)。
DHT的主要思想是:首先,每条文件索引被表示成一个(K, V)对,K称为关键字,可以是文件名(或文件的其他描述信息)的哈希值,V是实际存储文件的节点的IP地址(或节点的其他描述信息)。所有的文件索引条目(即所有的(K, V)对)组成一张大的文件索引哈希表,只要输入目标文件的K值,就可以从这张表中查出所有存储该文件的节点地址。然后,再将上面的大文件哈希表分割成很多局部小块,按照特定的规则把这些小块的局部哈希表分布到系统中的所有参与节点上,使得每个节点负责维护其中的一块。这样,节点查询文件时,只要把查询报文路由到相应的节点即可(该节点维护的哈希表分块中含有要查找的(K,V)对)。
这里介绍的Ch
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









