







9.1目标检测
场景描述
-
目标检测(Object Detection)任务是计算机视觉中极为重要的基础问题,也是解决实例分割(Instance Segmentation)、场景理解(Scene Understanding)、目标跟踪(ObjectTracking)、图像标注(Image Captioning)等问题的基础。
-
目标检测,顾名思义,就是检测输入图像中是否存在给定类别的物体,如果存在,则输出物体在图像中的位置信息。这里的位置信息通常用矩形边界框(bounding box)的坐标值来表示。
-
物体检测模型大致可以分为单阶段(one-stage)模型和两阶段(two-stage)模型两大类。
-
本节分析和对比了这两类模型在架构、性能和效率上的差异,给出了原理解释,并介绍了其各自的典型模型和发展前沿,以帮助读者对物体检测领域建立一个较为全面的认识。
知识点
物体检测、单步模型、两步模型、R-CNN系列模型、YOLO系列模型
9.1.1 简述目标检测领域中的单阶段模型和两阶段模型的性能差异及其原因
单阶段模型:
-
单阶段模型是指没有独立地、显式地提取候选区域(region proposal),直接由输入图像得到其中存在的物体的类别和位置信息的模型。
-
典型的单阶段模型有
- OverFeat[1]、
- SSD(Single Shotmultibox-Detector)[2]、
- YOLO(You Only Look Once)[3-5]系列模型等。
两阶段模型:
-
两阶段模型有独立的、显式的候选区域提取过程,即先在输入图像上筛选出一些可能存在物体的候选区域,然后针对每个候选区域,判断其是否存在物体,如果存在,就给出物体的类别和位置修正信息。
-
典型的两阶段模型有
- R-CNN [6]
- SPPNet [7]
- Fast R-CNN[8]
- Faster R-CNN[9]
- R-FCN[10]
- Mask R-CNN[11]等
性能差异
图9.1总结了目标检测领域重一些典型模型(包括单阶段和两阶段)的发展历程(截止2017年年底)[12]。
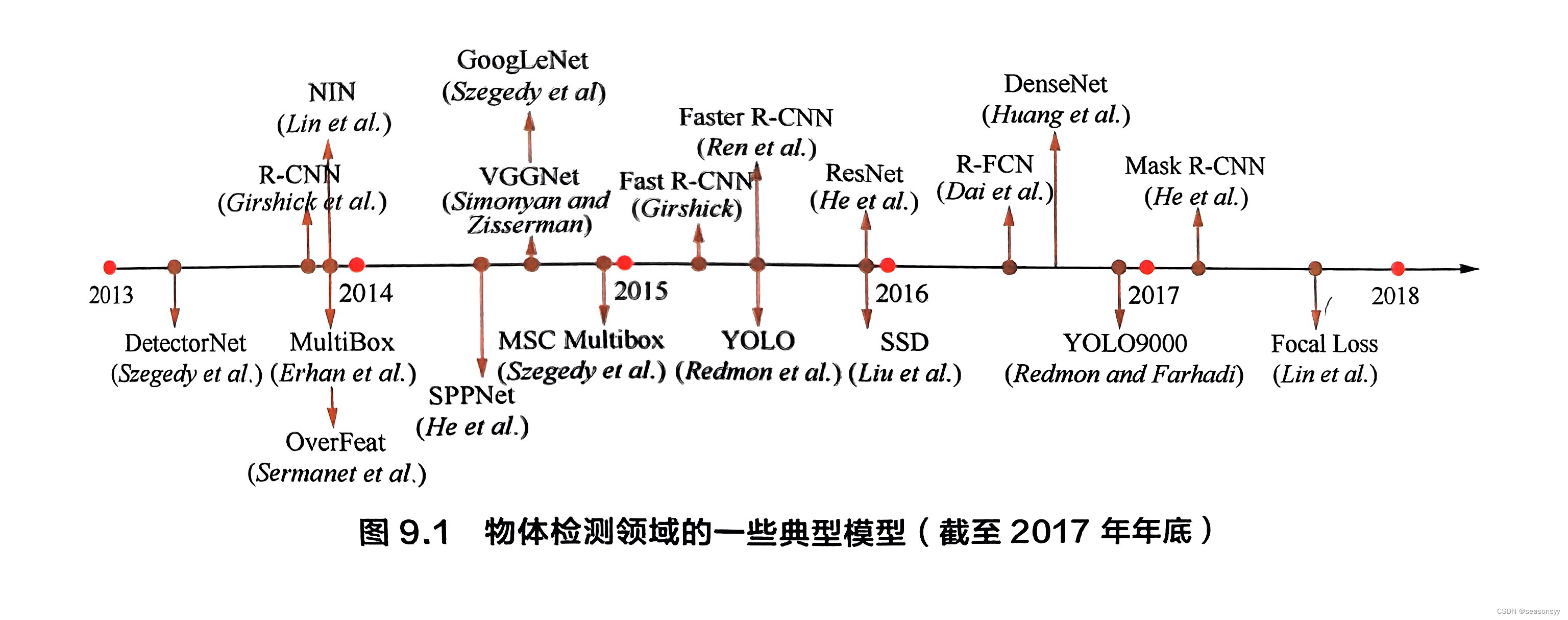
一般来说,单阶段模型在计算效率上有优势,两阶段模型在检测精度上有优势。
参考文献[13]对比了Faster R-CNN和SSD等模型在速度和精度上的差异,如图9.2所示。
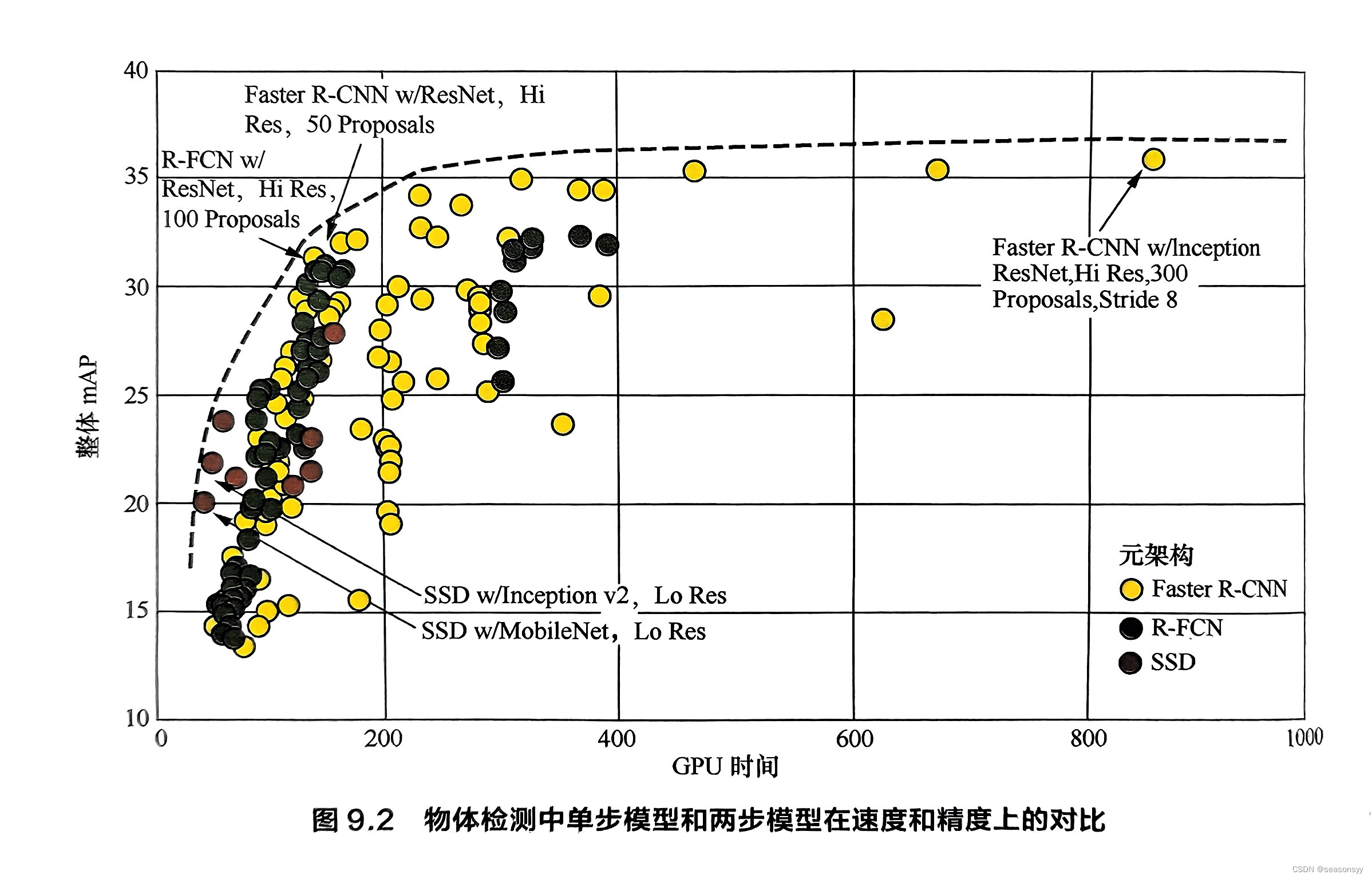
注:图9.2中,SSD的颜色是棕色圆圈。R-FCN是深绿色圆圈。
可以看到:
当检测时间较短时,单阶段模型SSD能取得更高的精度;
而随着检测时间的增加,两阶段模型Faster R-CNN则在精度上取得优势。
在速度和精度上的差异原因
对于单阶段模型与两阶段模型在速度和精度上的差异,学术界一般认为有如下原因。
-
摘要:两阶段模型有独立候选框提取步骤,所以到第二步分类和修正候选框的时候,正负样本比例平衡。
单阶段模型负样本比例较大。
-
单阶段模型:大多数单阶段模型是利用**预设的锚框(Anchor Box)**来捕捉可能存在于图像中各个位置的物体。
因此,单阶段模型会对数量庞大的锚框进行是否含有物体及物体所属类别的密集分类。
由于一幅图像中实际含有的物体数目远小于锚框的数目,因而在训练这个分类器时正负样本数目是极不均衡的,这会导致分类器训练效果不佳。
RetinaNet(14)通过Focal Loss 来抑制负样本对最终损失的贡献以提升网络的整体表现。
-
两阶段模型:在两阶段模型中,由于含有独立的候选区域提取步骤,第一步就可以筛选掉大部分不含有待检测物体的区域(负样本),在传递给第二步进行分类和候选框位置/大小修正时,正负样本的比例已经比较均衡,不存在类似的问题。
-
-
摘要:两阶段模型修正了两次候选框,单阶段模型没有修正,所以单阶段模型质量较差
-
两阶段模型:在候选区域提取的过程会对候选框的位置和大小进行修正,因此在进入第二步前,候选区域的特征已被对齐,这样有利于为第二步的分类提供质量更高的特征。
另外,两阶段模型在第二步中候选框会被再次修正,因此一共修正了两次候选框,这带来了更高的定位精度,但同时也增加了模型复杂度。
-
单阶段模型:没有候选区域提取过程,自然也没有特征对齐步骤,各锚框的预测基于该层上每个特征点的感受野,其输入特征未被对齐,质量较差,因而定位和分类精度容易受到影响。
-
-
摘要:两阶段模型在第二部对候选框进行分类和回归时,受累于大量候选框,所以两阶段模型存在计算量大、速度慢的问题。
-
两阶段模型:以Faster R-CNN为代表的两阶段模型在第二步对候选区域进行分类和位置回归时,是针对每个候选区域独立进行的,因此该部分的算法复杂度线性正比于预设的候选区域数目,这往往十分巨大,导致两阶段模型的头重脚轻(heavy head)问题。
解决:近年来虽然有部分模型(如Light-Head R-CNN[15])试图精简两阶段模型中第二步的计算量,但较为常用的两阶段模型仍受累于大量候选区域,相比于单阶段模型仍存在计算量大、速度慢的问题。
-
最新的一些基于
-
单阶段模型的物体检测方法有CornerNet[16]、RefineDet[17]、ExtremeNet[18]等
-
两阶段模型的物体检测方法有PANet[19]、Cascade R-CNN[20]、Mask Score R-CNN[21]等
下集预告:9.1.2 简单介绍两阶段模型R-CNN、SPPNet、Fast R-CNN、Faster R-CNN的发展过程
参考文献:
[1]SERMANET P, EIGEN D, ZHANG X, et al. OverFeat: Integrated recognition,localization and detection using convolutional networks[J]. arXiv preprintarXiv:1312.6229,2013.
[2]LIU W,ANGUELOV D, ERHAN D, et al. SSD: Single shot multibox detector[C]//European Conference on Computer Vision. Springer, 2016: 21-37.
[3]REDMON J,DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition, 2016: 779-788.
[4] REDMON J, FARHADI A. YOLO9000: Better, faster, stronger[C]//Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition, 2017:7263-7271.
[5]REDMON J, FARHADI A. YOLOv3: An incremental improvement[J]. arXivpreprint arXiv:1804.02767,2018.
GIRSHICK R, DONAHU J,DARRELL T, et al. Rich feature hierarchies for[9]accurate object detection and semantic segmentation[C]//Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition, 2014:580-587.
[7] HE K,ZHANG X, REN S,et al. Spatial pyramid pooling in deep convolutionalnetworks for visual recognition[J]. IEEE Transactions on Pattern Analysisand Machine Intelligence, IEEE, 2015,37(9):1904-1916.
[8]GIRSHICK R. Fast R-CNN[C]//Proceedings of the IEEE International Conferenceon Computer Vision, 2015: 1440-1448.
[9]REN S,HE K,GIRSHICK R, et al. Faster R-CNN: Towards real-time objectdetection with region proposal networks[C]//Advances in Neural InformationProcessing Systems, 2015:91-99.
[10] DAI J, LI Y, HE K, et al. R-FCN: Object detection via region-based fully convolutional networks[C]//Advances in Neural Information Processing Systems, 2016: 379-387.[11] HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision, 2017: 2961-2969.
[12] LIU L, OUYANG W, WANG X, et al. Deep learning for generic object detection:A survey[J]. arXiv preprint arXiv:1809.02165,2018.
[13] HUANG J, RATHOD V, SUN C, et al. Speed/accuracy trade-offs for modernconvolutional object detectors[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition, 2017: 7310-7311.
[14] LIN T-Y,GOYAL P,GIRSHICK R, et al. Focal loss for dense object detection[C]//Proceedings of the IEEE International Conference on Computer Vision,2017:2980-2988.
[15] LI Z, PENG C, YU G, et al. Light-head R-CNN: In defense of two-stage objectdetector[J].arXiv preprint arXiv:1711.07264,2017.
[16] LAW H, DENG J. CornerNet: Detecting objects as paired keypoints[C]//Proceedings of the European Conference on Computer Vision, 2018:734-750.
[17] ZHANG S, WEN L, BIAN X, et al. Single-shot refinement neural network forobject detection[C]//Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition, 2018: 4203-4212.
[18] ZHOU X, ZHUO J,KRÄHENBÜHL P. Bottom-up object detection by groupingextreme and center points[J]. arXiv preprnt arXiv:1901.08043,2019.
[19] LIU S, QI L,QIN H,et al. Path aggregation network for instance segmentation [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2018:8759-8768.
[20] CAI Z, VASCONCELOS N. Cascade R-CNN: Delving into high qualityobject detection[C]//Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition, 2018:6154-6162.
[21] HUANG Z,HUANG L, GONG Y,et al. Mask scoring R-CNN[C]//Proceedings ofthe IEEE Conference on Computer Vision and Pattern Recognition,2019:6409-6418.
参考文献:
《百面深度学习》 诸葛越 江云胜主编
出版社:人民邮电出版社(北京)
ISBN:978-7-115-53097-4
2020年7月第1版(2020年7月北京第二次印刷)
推荐阅读:
//好用小工具↓
// 深度学习经典网络↓















 658
658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









