






 本文探讨了针对部分目标的行人重识别(partial person re-identification, partial reid)问题,提出了一种名为VPM的网络结构。VPM利用自监督学习确定目标的可见区域,解决空间错位和干扰噪声问题。在推理时,它强调共同可见区域的匹配,减少不共存区域的噪声影响。此外,自监督训练为region locator提供标注,并使损失函数更关注可见和共享区域。实验表明,VPM在处理不完整目标时优于传统方法,但其应用受限于训练数据的完整性要求。
本文探讨了针对部分目标的行人重识别(partial person re-identification, partial reid)问题,提出了一种名为VPM的网络结构。VPM利用自监督学习确定目标的可见区域,解决空间错位和干扰噪声问题。在推理时,它强调共同可见区域的匹配,减少不共存区域的噪声影响。此外,自监督训练为region locator提供标注,并使损失函数更关注可见和共享区域。实验表明,VPM在处理不完整目标时优于传统方法,但其应用受限于训练数据的完整性要求。
[阅读心得] 行人重识别经典论文——VPM
写在前面
本工作针对目标不全情况下(Partial obj)的ReID问题,提出了一种感知可见区域的网络VPM,利用自监督的方式学习目标的分区和特征,并且解决了holistic和partial这种不对等region的匹配问题。非常具有借鉴价值。
1. Abstract
本工作主要贡献为:提出了一种基于自监督学习的VPM模块,使其能够确定可见区域。在两张图片对比时,能够提出二者的共存区域,从而抑制来自非共存区域的“空间错位”和“噪声干扰”
2. Introduction
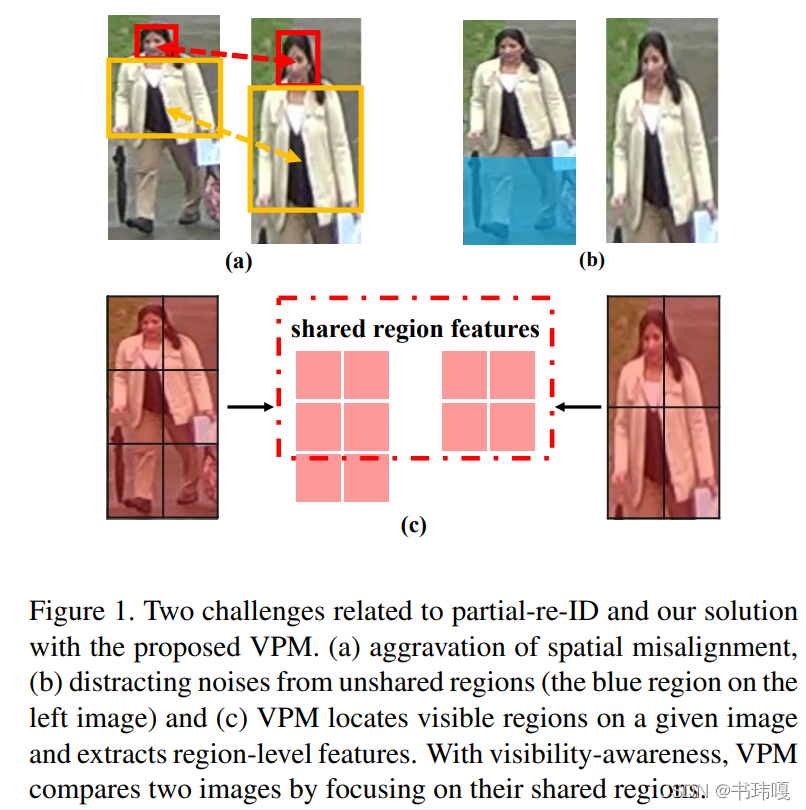
针对partial reid的匹配问题和holistic reid的匹配有一定的区别,而带来更大的挑战:
- 空间错位:holistic reid的错位只发生发动作和视角的变化;而对于partial reid,就算是视角相同,也会带来很大的空间错位,如上图(a)所示;这也是为什么像PCB这样对于holistic的reid方法直接应用在partial上反而会降低性能的原因。
- 干扰噪声:对于那些不共存的区域,利用这些进行匹配,反而相当于引入了干扰的噪声,如上图(b)所示;
3. VPM
3.1 Architecture
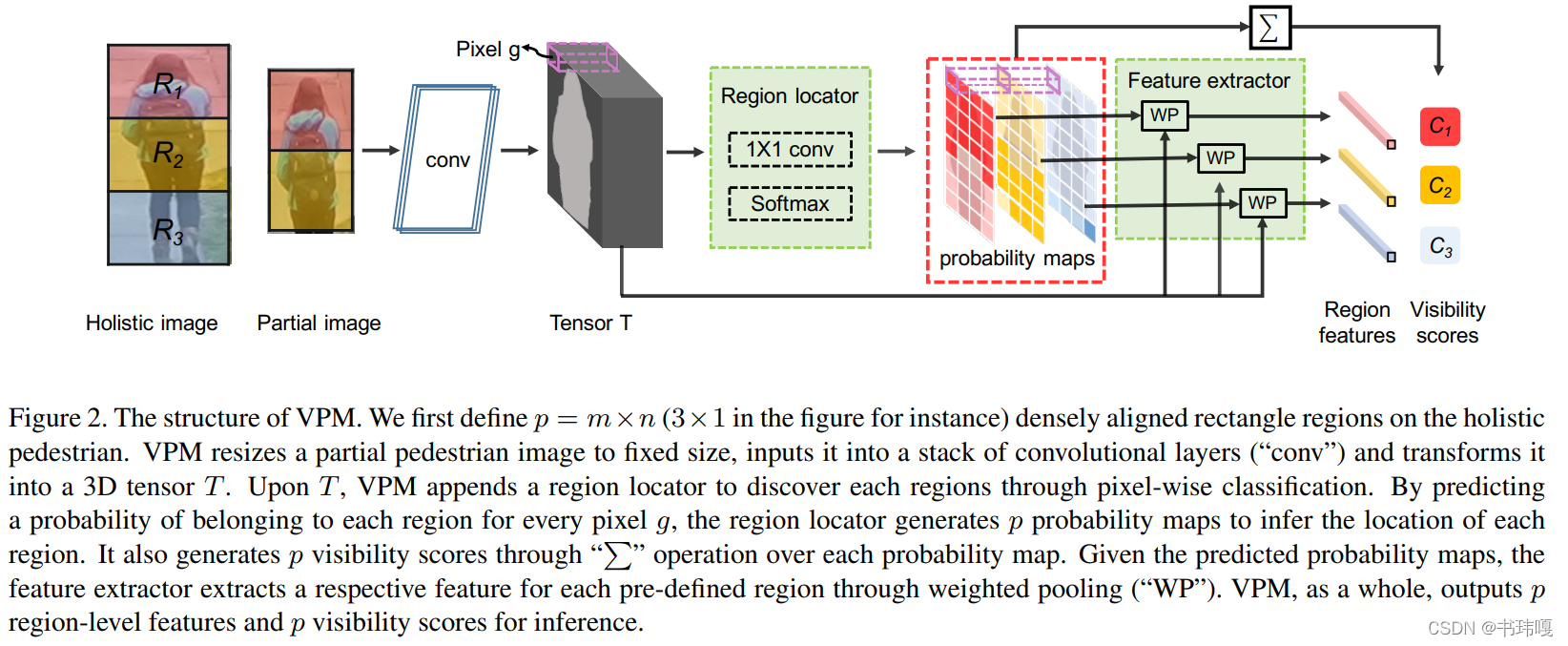
VPM的结构如上图所示,主要流程如下:
1)partial image作为输入,通过backbone得到三维的特征块Tensor T
2)Region locator用于将Tensor T中的像素进行分类,判定其属于各个分区的概率,输出probability maps代表各个像素对应哪个区域的概率
P ( R i ∣ g ) = s o f t m a x ( W T g ) = e x p W i T g ∑ j = 1 p e x p W j T g P(R_i|g) = softmax(W^Tg) = \frac{exp W_i^Tg}{\sum_{j=1}^pexpW_j^Tg} P(Ri∣g)=softmax(WTg)=∑j=1pexpWjTgexpWiTg
3)Feature extractor将maps与Tensor T结合,得到隶属于不同region的embedding和该区域可见程度的评分Visibility Scores
C i = ∑ g ∈ T P ( R i ∣ g ) C_i = \sum_{g\in T} P(R_i|g) Ci=∑g∈TP(Ri∣g)
f i = ∑ g ∈ T P ( R i ∣ g ) g C i f_i = \frac{\sum_{g\in T} P(R_i|g) g}{C_i} fi=Ci∑g∈TP(Ri∣g)g
3.2 Inference
实际推理时,对于两张图片
I
k
,
I
l
I^k, I^l
Ik,Il,分别得到对应的embedding和可见度评分{
f
i
l
,
C
i
l
f_i^l, C_i^l
fil,Cil},{
f
i
k
,
C
i
k
f_i^k, C_i^k
fik,Cik},则两者距离衡量为:
D
k
l
=
∑
i
=
1
p
C
i
k
C
i
l
D
i
k
l
∑
i
=
1
p
C
i
k
C
i
l
D^{kl} = \frac{\sum_{i=1}^p C_i^k C_i^l D_i^{kl}}{\sum _{i=1}^p C_i^k C_i^l}
Dkl=∑i=1pCikCil∑i=1pCikCilDikl
其中,
p
p
p表示设定的分区总数,
D
i
k
l
D_i^{kl}
Dikl表示统一区域对应embedding 的距离,使用欧氏距离计算;
由此可见,依照此方法,二者共同可见的区域权重占比大,二者均不可见的区域权重占比小,由此一定程度上的使距离衡量更加倾向于两图片共同出现的部分。
3.3 Self-supervision
自监督训练可以说是VPM最重要的环节,具体的方法是:对完整的holistic pedestrians图片,进行随机的crop,并按照实现预设的region为Tensor T进行分配:
we assign every pixel g g g on T with a region label L( L ∈ 1 , 2 , . . . p L \in 1,2,...p L∈1,2,...p) to indecate which region g belongs to.
self-supervision对VPM的作用主要有三:
- 为region locator模块提供了训练用的ground truth
- 使classification loss更加关注可见的区域(visible regions)
- 使triplet loss更加关注共享区域(shared regions)
3.4 Training
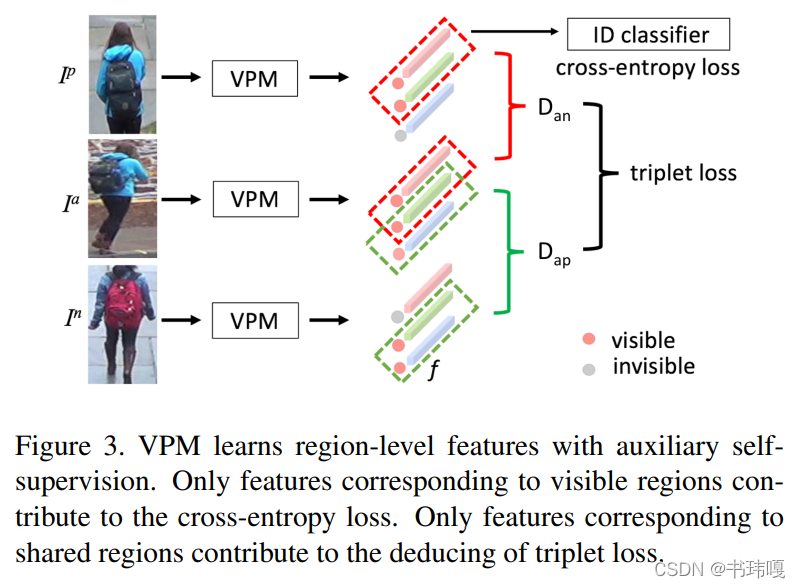
1) Region Locator
利用自监督生成的label L,通过cross-entropy loss进行训练
L
R
=
−
∑
g
∈
T
1
i
=
L
l
o
g
(
P
(
R
i
∣
g
)
)
L_R= -\sum_{g \in T} 1_{i=L} log(P(R_i|g))
LR=−∑g∈T1i=Llog(P(Ri∣g))
2)Region feature extractor
采用cross-entropy和triplet loss
L
I
D
=
−
∑
i
∈
V
1
k
=
y
l
o
g
(
s
o
f
t
m
a
x
(
I
P
i
(
f
i
)
)
)
L_{ID} = -\sum _{i \in V} 1_{k=y} log (softmax( IP_i(f_i)))
LID=−∑i∈V1k=ylog(softmax(IPi(fi)))
L
t
r
i
=
[
D
a
p
−
D
a
n
+
α
]
L_{tri} = [D^{ap} - D^{an} + \alpha]
Ltri=[Dap−Dan+α]
3) Total loss
L
=
L
R
+
L
I
D
+
L
t
r
i
L = L_R + L_{ID} + L_{tri}
L=LR+LID+Ltri
4. Experiment
4.1 Large scale dataset
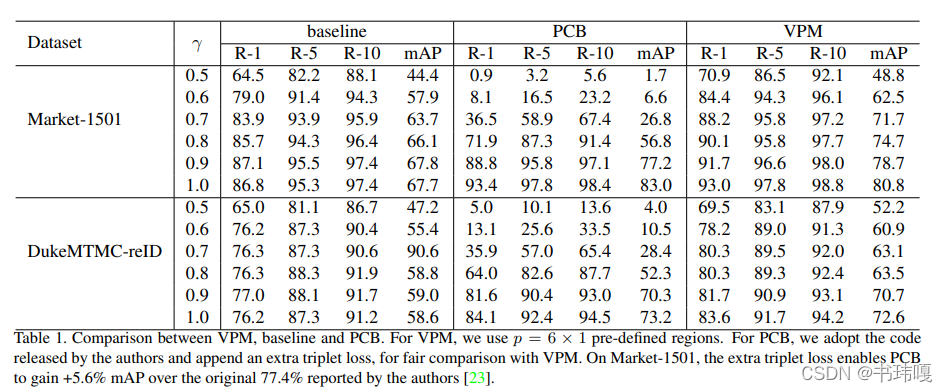
通过比较发现,PCB对于残缺的目标reid效果非常差,说明PCB这种part-level方法对目标残缺的鲁棒性很差
4.2 Crop Stretegy
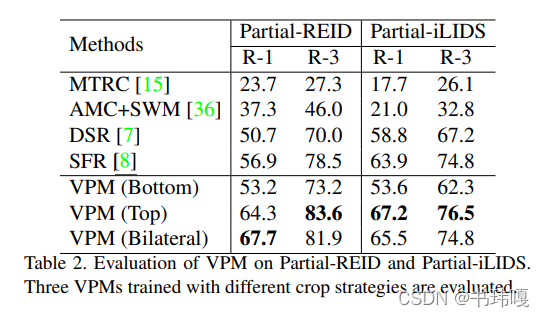
这里对crop的策略进行不同的尝试,由于测试的数据集的残缺形式于Top剪裁最为相近,所以Top/Bilateral的策略表现最好。这里作者提醒,如果对于不同的数据集,要根据实际情况选择crop stretegy
4.3 Visualization

5. Analysis
VPM把partial reid需要匹配的embedding数目统一成了固定数目,方便后面的匹配环节进行,这是很值得借鉴的。但是本工作使用有两个前提条件:训练集中全为完整的holistic目标、且bounding box必须紧密贴合目标。
但是对于自动驾驶的MOT工作,上述两个条件均不满足,目标是否完整是未知的,目标bbox的精确性依赖于检测环节。在这种情况下可能没法使用VPM中设计的自监督结构。由于不知道目标是否完整,所以要重新设计partial reid的结构。

















 799
799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









