







目录
3.1 Part-Aligned Representation
主要思路贡献
在进行行人重识别中关注行人身体部分特征的风格和提取,尽量避免背景等多余特征信息表示。
摘要
作者提出了一种简单而有效的人体部分对齐 (part-aligned )表示,用于处理身体局部匹配错位问题。我们的方法将人体分解为不同的区域(部分),从而计算区域上的表示,并将probe和gallery的对应区域之间计算的相似度总和作为总体匹配分数。 我们方法受到深层神经网络注意力机制的启发,学习最小化三重损失函数,函数的学习不需要身体部位标记信息。与大多数学习基于全局或空间分区的局部表示的现有深度学习算法不同,我们的方法针对行人的身体部分进行分割,因此比姿势变化和行人 bounding box 中各种行人空间分布 更加健壮。并在 Market-1501, CUHK03, CUHK01 and VIPeR.数据集上进行了测试。
1.Introduction
行人重识别问题解决中很多研究者提出各种线索的解决方案, 本文采用的是外表特征。
现有的方法有很多的问题。

本文的解决方法主要为:
(1)检测行人有区别的人体区域;
(2)然后汇总相应部分之间的相似度;
(3)受注意力机制的影响,本文提出的深度学习模型网络模拟身体部位的提取和计算。并且学习的模型参数通过最大化端到端机制的重识别的质量而不需要行人的标签信息。
主要就是基于人体部位进行划分而不是基于空间进行划分。
2. Related Work
行人重识别的研究历程
Our approach :
1. focus on the feature extraction part and introduce a human body part-aligned rep-resentation.
2. does not require those labeling information,but only uses the similarity information (a pair of person images are about the same person or different persons), to learn the part model for person matching.
3. Our human body part estimation scheme is inspired by the attention model
3.Our Approach
行人重识别的目的是从gallery images找到 与probe image相同身份的行人。
训练数据集: ![]() ,将训练集分为三类:
,将训练集分为三类:![]() ,
,![]() 表示同一行人,是一个 positive pair of images,
表示同一行人,是一个 positive pair of images,![]() 表示不痛行人,是 a negative pair of images。
表示不痛行人,是 a negative pair of images。
损失函数:triplet loss function
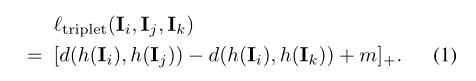
m表示 negative pair 图像之间的距离比 positive pair图像对之间距离多出的那部分的余量。在论文实验中将m设置为0.2
![]() 表示欧式距离
表示欧式距离 ![]() 表示铰链损失(Hinge Loss)。
表示铰链损失(Hinge Loss)。![]() 是提取图像 I 的表示的特征提取网络。
是提取图像 I 的表示的特征提取网络。
整个的损失函数为:
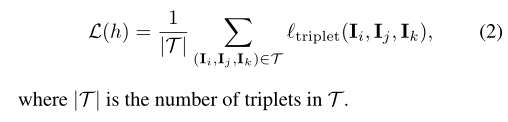
Hinge Loss
Hinge Loss 是机器学习领域中的一种损失函数,可用于“最大间隔(max-margin)”分类,其最著名的应用是作为SVM的目标函数。
在二分类情况下,公式如下:
L(y) = max(0 , 1 – t⋅y)
其中,y是预测值(-1到1之间),t为目标值(1或 -1)。其含义为,y的值在 -1到1之间即可,并不鼓励 |y|>1,即让某个样本能够正确分类就可以了,不鼓励分类器过度自信,当样本与分割线的距离超过1时并不会有任何奖励。目的在于使分类器更专注于整体的分类误差。
变种
在实际应用中,一方面,预测值y并不总是属于[-1,1],也可能属于其他的取值范围;另一方面,很多时候我们希望训练的是两个元素之间的相似关系,而非样本的类别得分。所以下面的公式可能会更加常用:
L( y, y′) = max( 0, margin – (y–y′) )
= max( 0, margin + (y′–y) )
= max( 0, margin + y′ – y)
其中,y是正确预测的得分,y′是错误预测的得分,两者的差值可用来表示两种预测结果的相似关系,margin是一个由自己指定的安全系数。我们希望正确预测的得分高于错误预测的得分,且高出一个边界值 margin,换句话说,y越高越好,y′ 越低越好,(y–y′)越大越好,(y′–y)越小越好,但二者得分之差最多为margin就足够了,差距更大并不会有任何奖励。这样设计的目的在于,对单个样本正确分类只要有margin的把握就足够了,更大的把握则不必要,过分注重单个样本的分类效果反而有可能使整体的分类效果变坏。分类器应该更加专注于整体的分类误差。
有多种 hinge loss 的变化形式,比如,Crammerand Singer提出的一种针对线性分类器的损失函数:
Weston and Watkins提出了一种相似定义,只不过用相加取代了求最大值:
优化
hinge loss 函数是凸函数,因此机器学习中很多的凸优化方法同样适用于 hinge loss。
然而,因为 hinge loss 在t⋅y=1的时候导数是不确定的,所以一个平滑版的 hinge loss 函数会更加有助于优化,它由Rennie and Srebro提出:
除此之外,还有二次方平滑:
上图为 hinge loss 函数关于z=t⋅y的三种版本,蓝色的线是原始版,绿色线为二次方平滑,红色的线为分段平滑,也就是Rennie and Srebro提出的那一版。





3.1 Part-Aligned Representation
The part-aligned 表示提取器是一个深度神经网络,由全链接卷积神经网络(FCN)组成,其输出是图像f的eature map,接着是 part net,它检测 part maps 并输出提取的 part features 。 我们的方法不是将图像框在空间上划分为网格单元格或水平条纹,而是旨在将人体划分为aligned parts.。

The part net 有几个分支组成,每个分支的输入都是由FCN网络提取的image feature map (用一个3维的张量 T 表示)作为输入,因此t(x,y,c)表示位置(x,y)上的第c个响应。检测区别区域(一般是指身体区域),并提取检测区域上的特征作为输出,用2维特征![]() 表示,
表示,![]() 表示位置(x,y)位于第k个区域的degree。从图片 feature map T:
表示位置(x,y)位于第k个区域的degree。从图片 feature map T:
![]()
![]() 是一种实现为卷积网络的区域图检测器。
是一种实现为卷积网络的区域图检测器。
通过加权方案计算第k个区域的部分特征图![]()
![]()
接下来是以平均池化层,
![]()
![]()
然后是线性降维层,通过全连接层实现,以将![]() 降低到d维特征向量
降低到d维特征向量![]() 。 最后,我们连接所有局部特征:
。 最后,我们连接所有局部特征:
![]()
并且执行L2归一化,最终得到行人表示![]() 。
。
3.2. Optimization
学习参数用 θ表示,公式2的梯度计算表示可用下式表示:
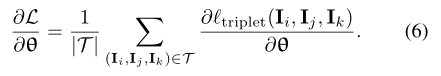
其中,
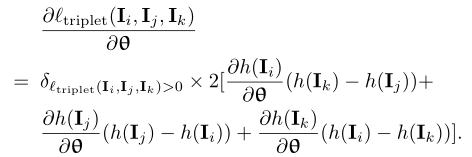
最终得到以下形式:
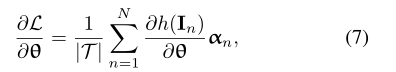
这里的![]() 是一个权重向量,有现有的网络参数所决定。计算方式如下:
是一个权重向量,有现有的网络参数所决定。计算方式如下:
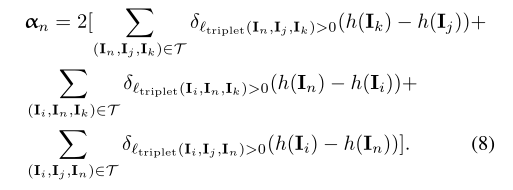
等式7表明 triplet loss的梯度计算与一元分类损失的梯度一样。 因此,在SGD(随机梯度下降)的每次迭代中,我们可以绘制 mini-batch样本(M)而不是对三元组的子集进行采样:前向传播的一次通过以计算每个样本的表示![]() , 计算 mini-batch的权重αn,计算梯度
, 计算 mini-batch的权重αn,计算梯度![]() ,最后聚集 mini-batch样本的梯度。 直接绘制一组三元组通常会导致过多(超过M个)样本,增大计算难度。
,最后聚集 mini-batch样本的梯度。 直接绘制一组三元组通常会导致过多(超过M个)样本,增大计算难度。
随机梯度下降法SGD
称为批处理梯度下降算法,这种更新算法所需要的运算成本很高,尤其是数据量较大时。考虑下面的更新算法:
该算法又叫做随机梯度下降法,这种算法不停的更新weights,每次使用一个样本数据进行更新。当数据量较大时,一般使用后者算法进行更新。
由于批梯度下降每跟新一个参数的时候,要用到所有的样本数,所以训练速度会随着样本数量的增加而变得非常缓慢。随机梯度下降正是为了解决这个办法而提出的。它是利用每个样本的损失函数对θ求偏导得到对应的梯度,来更新θ:
更新过程如下:
随机梯度下降是通过每个样本来迭代更新一次,对比上面的批量梯度下降,迭代一次需要用到所有训练样本(往往如今真实问题训练数据都是非常巨大),一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。


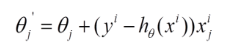

3.3. Implementation details
Network architecture:使用了GoogLeNet子网络,从图像输入到 inception_4e输出,然后是1x1的卷积层输出为512通道的图像feature map。其中输入图像resized to 160 × 80,feature map 设置为 10×5x512。对于数据预处理,使用调整大小的图像的标准水平翻转。在part net中, part estimator(![]() )是通过1x1的卷积层以及一个非线性的sigmoid层。有K个部分探测器 part detectors,其中K由交叉验证确定。
)是通过1x1的卷积层以及一个非线性的sigmoid层。有K个部分探测器 part detectors,其中K由交叉验证确定。
Network Training: 基于 Caffe进行的训练。使用GoogLeNet模型初始化图像特征图提取部分,该模型通过ImageNet进行预训练。 在每次迭代中,我们对400个图像的小批量进行采样,例如,平均有40个身份,每个身份在Market-1501和CUHK03上包含10个图像。 总的来说,每次迭代大约有140万个三元组。 从等式8,我们看到只有三元组的子集,其预测的相似性顺序与 ground-truth 顺序不一致,即![]() ,这是由于权重 (θ)不断的更新。因此我们 在等式7中使用计数三元组的数量来代替| T |。
,这是由于权重 (θ)不断的更新。因此我们 在等式7中使用计数三元组的数量来代替| T |。
我们采用初始学习率0.01,并且每20K迭代除以5。 权重衰减为0.0002,梯度更新的动量为0.9。 在K40 GPU上,每个模型在大约12小时内训练50K次迭代。 对于测试,在一个GPU上平均需要0.005秒来提取部分对齐的表示。
3.4. Discussions

4. Experiments
省略
5. Conclusions
本文提出了一种新的部分对齐表示方法来处理身体错位问题。本文借鉴注意力模型的思想,采用一种深层神经网络形式,这种形式只能从人的相似性中学习而没有关于 人体部位。旨在将人体而不是人类图像框划分为网格或条带,因此在人类图像框中构造变化和不同的人类空间分布更加稳健,因此匹配更可靠。 与单独的身体部位检测相比,我们的方法为人员重新识别学习更有用的身体部位。















 456
456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









