







Wav2Lip是一种基于深度学习的人物口型生成技术,它可以将音频信号转化为对应的人物口型动画。 简单来说,就是通过分析音频信号中的语音信息,从而生成出与语音内容相匹配的口型动画。 这一技术的出现,极大地提高了虚拟数字人的逼真程度,使得观众能够获得更加真实的视听体验
选择原视频和原音频
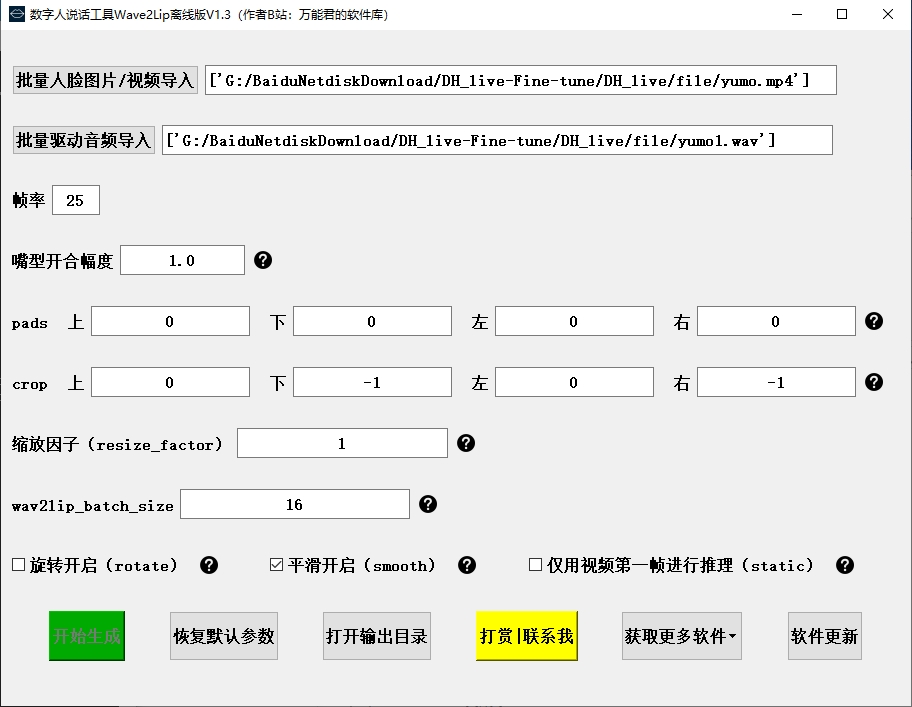
点击“开始生成”
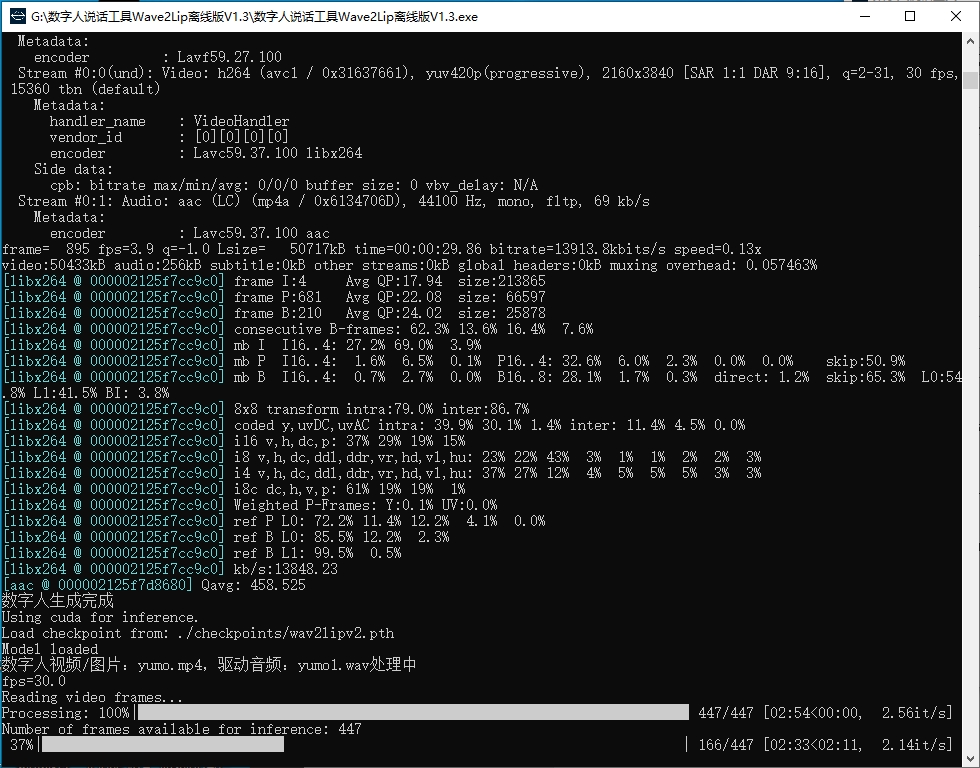
看效果
金双石科技
还是非常优秀的。
生成视频耗时比较长,面部有点模糊,要求视频人物不说话会支持得比较好。
判断音频和唇形在某个共同参数空间下的相似性。
推理过程
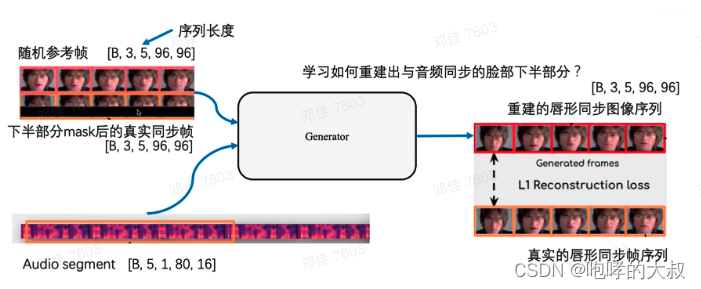
1)对输入语音提取Mel特征,得到语音特征块
2)对全脸+去掉下半张脸(6* 96* 96)两组人脸提取图片特征
3)将上面两种特征输入到wav2lip网络,生成带口型的人脸
4)将带口型的人脸贴回原图,逐帧写成纯图像视频
5)用ffmpeg合成带语音的视频
Wav2Lip是一种深度学习模型,其核心思想是将音频波形直接转换为面部动画。该模型基于生成对抗网络(GAN)设计,包含生成器和判别器两个主要部分。生成器的任务是根据输入的音频波形生成逼真的面部动画,而判别器的目标是区分生成的动画与真实的面部动画。
生成器G GG负责生成目标口型的人脸图像,由三部分组成:身份编码器(Identity Encoder)、语音编码器(Speech Encoder)和人脸解码器(Face Decoder),这三部分均是由堆叠的2D卷积层组成。概括来说,生成器是一个2D卷积的编码器-解码器结构。
身份编码器的把随机参考帧R RR与先验姿势P PP(下半部分被mask的目标脸)按通道维度拼接作为输入,编码身份特征。先验姿势帧的下半部分被mask,但是提供了目标人脸的姿态信息;参考帧则包含目标人脸的完整外观,用于唇部形状和运动的合成。
语音编码器用于编码输入的语音片段
人脸解码器以编码后的音频特征与身份特征的拼接为输入,通过反卷积进行上采样,重建人脸图像。
生成器通过最小化生成帧L g L_{g}L
g
与真实帧L G L_{G}L
G
之间的L1重构损失来进行训练。
Easy-Wav2Lip是Wav2Lip的改进版本,在设计上更为简洁,执行速度更快,同时生成的视频效果更加逼真。Wav2Lip技术可以让视频中的人物根据输入的音频生成匹配的唇形动作,从而实现口型与语音同步的效果。这项技术不仅适用于静态图像,还能够对动态视频进行处理,生成与目标语音同步的视频输出。
项目源码下载地址:GitHub - nghiakvnvsd/wav2lip384
参考:
Wav2Lip原理以及训练-CSDN博客
【AI数字人-论文】Wav2lip论文解读_ai数字人论文-CSDN博客
wav2lip-384x384 训练
https://www.jinshuangshi.com/forum.php?mod=viewthread&tid=883
(出处: 金双石科技)


















 4183
4183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











