







用LSTM进行情感分析原理
深度学习在自然语言处理中的应用
自然语言处理是教会机器如何去处理或者读懂人类语言的系统,主要应用领域:
- 对话系统 - 聊天机器人(小冰)
- 情感分析 - 对一段文本进行情感识别(我们一会要做的)
- 图文映射 - CNN和RNN的融合
- 机器翻译 - 将一种语言翻译成另一种语言,谷歌翻译已经很好
词向量模型
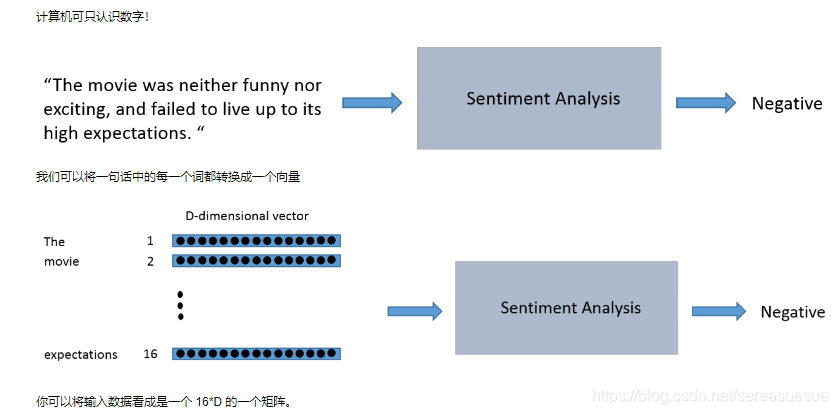
词向量是具有空间意义的并不是简单的映射!例如,我们希望单词 “love” 和 “adore” 这两个词在向量空间中是有一定的相关性的,因为他们有类似的定义,他们都在类似的上下文中使用。单词的向量表示也被称之为词嵌入。
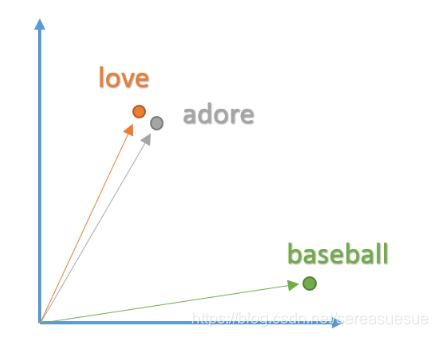
Word2Vec
为了去得到这些词嵌入,我们使用一个非常厉害的模型 “Word2Vec”。简单的说,这个模型根据上下文的语境来推断出每个词的词向量。如果两个个词在上下文的语境中,可以被互相替换,那么这两个词的距离就非常近。在自然语言中,上下文的语境对分析词语的意义是非常重要的。比如,之前我们提到的 “adore” 和 “love” 这两个词,我们观察如下上下文的语境。

从句子中我们可以看到,这两个词通常在句子中是表现积极的,而且一般比名词或者名词组合要好。这也说明了,这两个词可以被互相替换,他们的意思是非常相近的。对于句子的语法结构分析,上下文语境也是非常重要的。所有,这个模型的作用就是从一大堆句子(以 Wikipedia 为例)中为每个独一无二的单词进行建模,并且输出一个唯一的向量。Word2Vec 模型的输出被称为一个嵌入矩阵。
Word2Vec 模型根据数据集中的每个句子进行训练,并且以一个固定窗口在句子上进行滑动,根据句子的上下文来预测固定窗口中间那个词的向量。然后根据一个损失函数和优化方法,来对这个模型进行训练
Recurrent Neural Networks (RNNs)
现在,我们已经得到了神经网络的输入数据 —— 词向量,接下来让我们看看需要构建的神经网络。NLP 数据的一个独特之处是它是时间序列数据。每个单词的出现都依赖于它的前一个单词和后一个单词。由于这种依赖的存在,我们使用循环神经网络来处理这种时间序列数据。
循环神经网络的结构和你之前看到的那些前馈神经网络的结构可能有一些不一样。前馈神经网络由三部分组成,输入层,隐藏层和输出层。
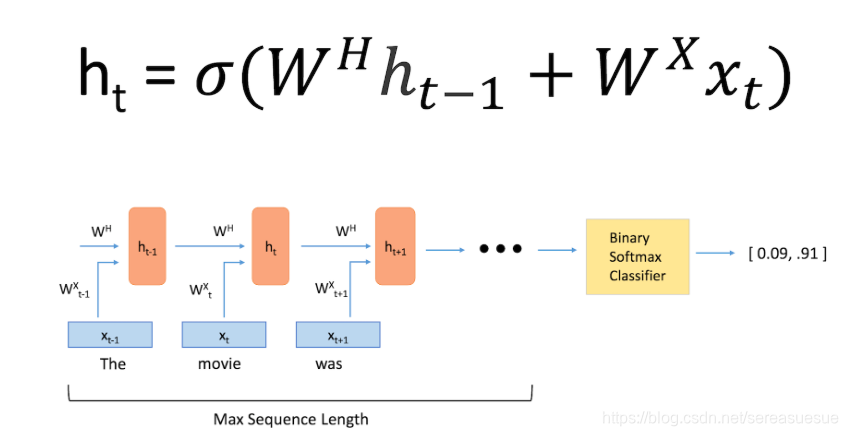
前馈神经网络和 RNN 之前的主要区别就是 RNN 考虑了时间的信息。在 RNN 中,句子中的每个单词都被考虑上了时间步骤。实际上,时间步长的数量将等于最大序列长度
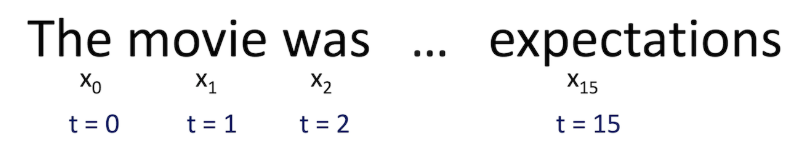
与每个时间步骤相关联的中间状态也被作为一个新的组件,称为隐藏状态向量 h(t) 。从抽象的角度来看,这个向量是用来封装和汇总前面时间步骤中所看到的所有信息。就像 x(t) 表示一个向量,它封装了一个特定单词的所有信息。
隐藏状态是当前单词向量和前一步的隐藏状态向量的函数。并且这两项之和需要通过激活函数来进行激活。
Long Short Term Memory Units (LSTMs)
长短期记忆网络单元,是另一个 RNN 中的模块。从抽象的角度看,LSTM 保存了文本中长期的依赖信息。正如我们前面所看到的,H 在传统的RNN网络中是非常简单的,这种简单结构不能有效的将历史信息链接在一起。举个例子,在问答领域中,假设我们得到如下一段文本,那么 LSTM 就可以很好的将历史信息进行记录学习。
在这里,我们看到中间的句子对被问的问题没有影响。然而,第一句和第三句之间有很强的联系。对于一个典型的RNN网络,隐藏状态向量对于第二句的存储信息量可能比第一句的信息量会大很多。但是LSTM,基本上就会判断哪些信息是有用的,哪些是没用的,并且把有用的信息在 LSTM 中进行保存。

我们从更加技术的角度来谈谈 LSTM 单元,该单元根据输入数据 x(t) ,隐藏层输出 h(t) 。在这些单元中,h(t) 的表达形式比经典的 RNN 网络会复杂很多。这些复杂组件分为四个部分:输入门,输出门,遗忘门和一个记忆控制器。
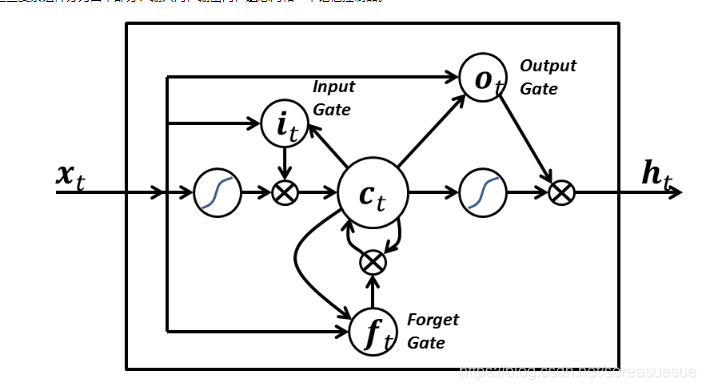
每个门都将 x(t) 和 h(t-1) 作为输入(没有在图中显示出来),并且利用这些输入来计算一些中间状态。每个中间状态都会被送入不同的管道,并且这些信息最终会汇集到 h(t) 。为简单起见,我们不会去关心每一个门的具体推导。这些门可以被认为是不同的模块,各有不同的功能。输入门决定在每个输入上施加多少强调,遗忘门决定我们将丢弃什么信息,输出门根据中间状态来决定最终的 h(t) 。
文档好多博主都有发见https://blog.csdn.net/duanlianvip/article/details/103584543
代码见https://blog.csdn.net/sereasuesue/article/details/108693854

















 9687
9687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









