









Lucene中TF-IDF的计算公式与普通的TF-IDF不一样。学习之后,感觉Lucene的计算方法更加合理,考虑得更加周全。
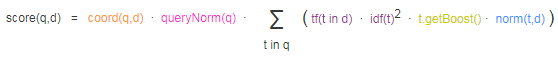
q:query,即搜索内容,例如:github
d:document,即文档内容,例如:i like github
即我们的搜索内容"github"跟文档内容"i like github"的TF-IDF值(相似度)。TF-IDF值越高,搜索的内容与文档的匹配度越高。
t:term,对query进行分词之后的单词
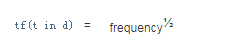
tf:文档中出现单词t的频次
numDocs:总的文档数量
docFreq:含有单词t的文档数量

t.getBoost():单词t的权重,即单词t的重要性
norm(t,d):文档长度加权因子,它的作用就是提高短文档的分数,降低长文档的分数。
f.boost():索引字段f的权重即重要性

coord(q, d):搜索内容query分词之后有n个单词,文档中出现了n个单词中的m个,那么coord(q, d) = m / n
queryNorm:归一化因子,让不同的query的IF-IDF分数可以进行比较。
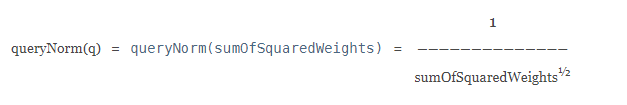

q.getBoost():与上面的同理,当前query的重要性/权重
欢迎关注同名公众号:“我就算饿死也不做程序员”。
交个朋友,一起交流,一起学习,一起进步。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









