







在前面的文章中,DIN模型 在用户行为序列建模中引入注意力机制来强调加权与target item相关的行为,以实现动态的兴趣表征;而DIEN模型 则在DIN的基础上加入时间性信息,使用注意力机制的GRU来挖掘用户兴趣的演变。
而今天的这篇文章也是继续这个主题,再介绍一个引入将行为序列切分session来对用户兴趣建模的模型:DSIN(Deep Session Interest Network)。
概要
论文:Deep Session Interest Network for Click-Through Rate Prediction
链接:https://arxiv.org/pdf/1905.06482.pdf
这篇论文认为许多研究都忽视了序列的内在结构:序列是由sessions组成,sessions是按照发生时间切分的用户行为。
并且观察到用户的行为在每个session里几乎都是同类(homogeneous)的,而在不同session之间又是混杂(heterogeneous)的,即用户在某一时间内的行为会集中在某一个“类别/主题”上,而在另一个时间段内则集中在另外一个“类别/主题”上。
如下图所示,是一个从真实场景下收集到的数据,下面的数字代表了当前点击商品与第一次点击商品的时间gap(单位为秒),session按照是否超过30min进行切分。

基础观察到这种规律,论文提出了DSIN(Deep Session Interest Network)来通过利用多个历史sessions来建模用户的行为序列。DSIN包含三个关键的组件:
- 将用户的行为序列切分多个sessions,然后使用带着偏置编码(bias encoding)的自注意力网络来建模多个sessions。自注意力可以捕获session之间的内在交互/相关关系,然后提取每个session的用户兴趣,因为这些不同的sessions可能会彼此相互关联,遵循一种序列化的模式;
- 接着,使用双向LSTM(Bi-LSTM) 来捕获这些不同的历史session兴趣的交互和演变;
- 最后,考虑不同的session兴趣对target item有着不一样的影响,设计了一个**局部激活单元(local activation uint)**去聚合它们,去建模行为序列的最终表征
这里的自注意力类似于transformer,将每个session类比token,可以前往这篇文章BERT模型系列大全解读回顾下transformer和自注意力。
基础模型
在前面的两篇相关文章 CTR之行为序列建模用户兴趣:DIN和CTR之行为序列建模用户兴趣:DIEN中都详细地介绍了Base Model,其主要包括四部分:特征表征(Feature Representation)、Embedding、Multiple Layer Perceptron (MLP)和损失函数。
具体的内容在这里就不再赘述了,但记住几个后面涉及的符号:
- 用户行为embeddings: S = [ b 1 ; . . . ; b i ; . . . ; b N ] ∈ R N × d m o d e l S=[b_1;...;b_i;...;b_N] \in \mathbb{R}^{N \times d_{model}} S=[b1;...;bi;...;bN]∈RN×dmodel
- target item属性(Item Profile)表征embeddings: X I ∈ R N i × d m o d e l X^I \in \mathbb{R}^{N_i \times d_{model}} XI∈RNi×dmodel
#DSIN结构
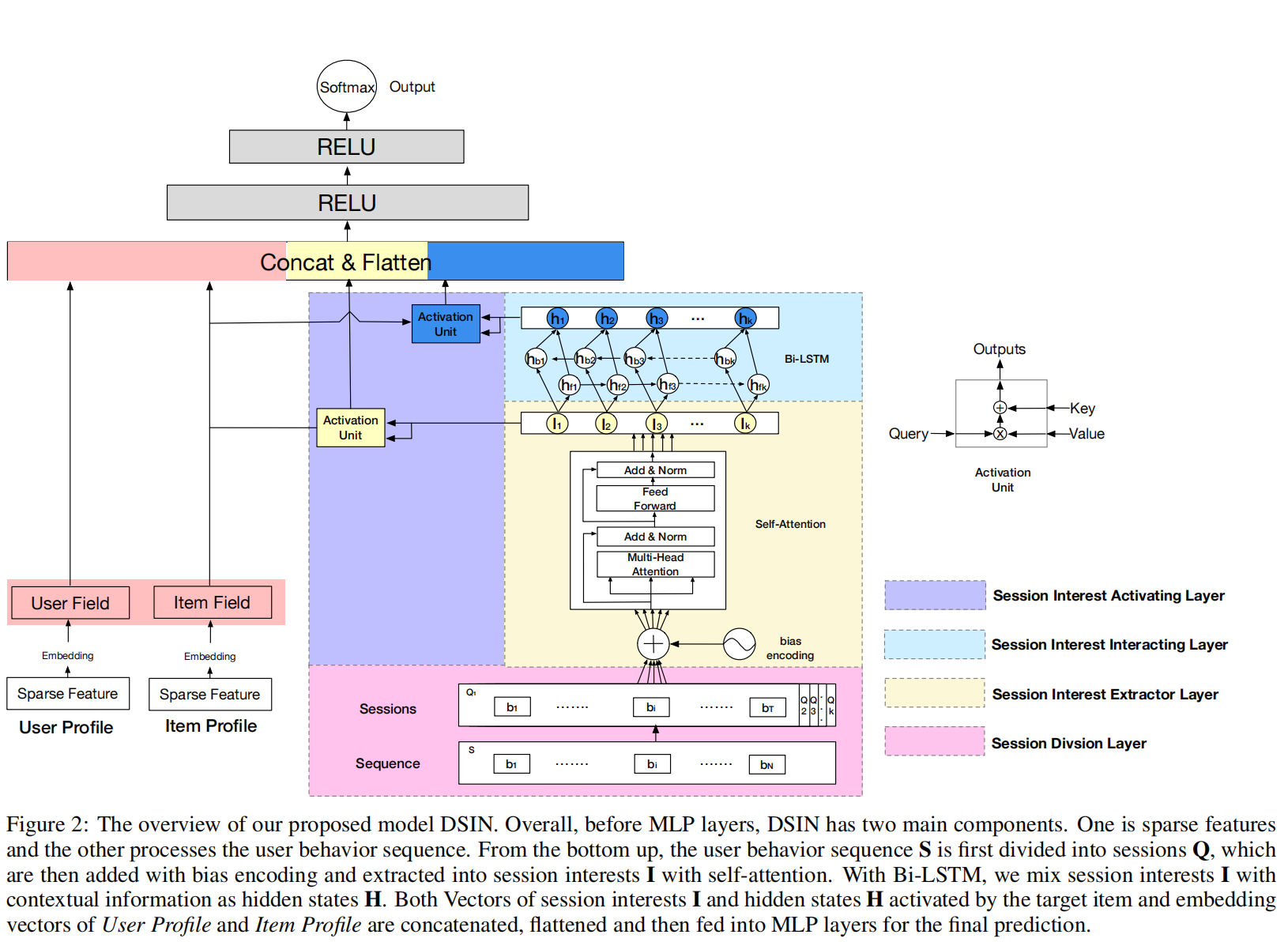
如上图所示,DSIN在底层的特征表征和Embedding的后面,MLP的前面,即中间部分加入了四个特殊的网络层:
- session划分层,将行为序列分割成不同的sessions;
- session兴趣提取层,提取用户的session兴趣;
- session兴趣交互层,捕获session兴趣之间的序列关系;
- session兴趣激活层,考虑(w.r.t) target item,对用户session兴趣应用局部激活单元。这与DIN中attention和DIEN中的GRU with attention一样的思想,来激活与target item更为相关的行为序列或兴趣序列。
session划分层
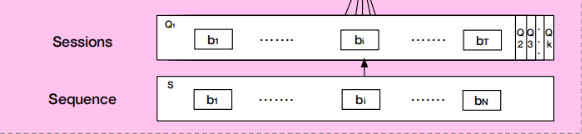
为了提取用户更为准确的session兴趣,论文将用户行为序列S划分成sessions集合Q,第k个session表示为:
Q k = [ b 1 ; . . . ; b i ; . . . ; b T ] ∈ R T × d m o d e l Q_k=[b_1;...;b_i;...;b_T] \in \mathbb{R}^{T \times d_{model}} Qk=[b1;...;bi;...;bT]∈RT×dmodel
- T是session保留的行为数量, b i b_i bi是session里的第i个行为。
- 用户sessions的分割是以时间间隔超过30min的相邻行为。即当两个相邻的行为时间超过30min的话,会以它们为界限,前面一个行为保留在当前session,后面一个行为会开启一个新的session。该做法出自《Framewise phoneme classification with bidirectional LSTM networks》的做法。
session兴趣提取层
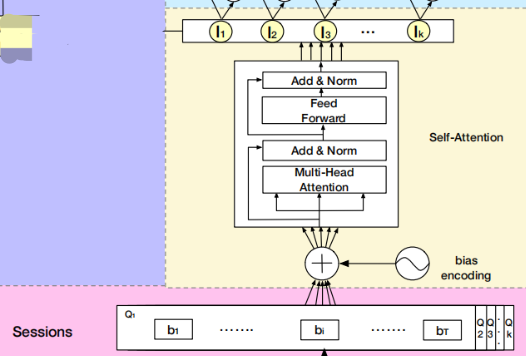
在同一个session里的行为之间是强相关的。另外,在一个session里,用户那些随意的行为会让session兴趣偏离它原本的表现。
为了捕获同一个session的行为之间的内在关系,降低那些不相关的行为的影响,论文使用了多头自注意力,并且进行了一些优化工作。
偏置编码
为了利用序列的顺序相关信息,自注意力机制给输入embeddings加入了位置编码。
而sessions的顺序相关信息和不同表征子空间的偏置同样需要被捕获,论文在位置编码的bias加入了bias encoding BE ∈ R K × T × d m o d e l \in \mathbb{R}^{K \times T \times d_{model}} ∈RK×T×dmodel,具体如下式:
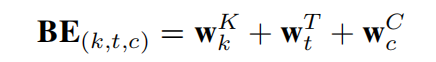
- w K ∈ R K w^K \in \mathbb{R}^K wK∈RK 是session的偏置向量,k是session的索引
- w T ∈ R T w^T \in \mathbb{R}^T wT∈RT 是session中的位置的偏置向量,t是行为在session里的索引
- w C ∈ R d m o d e l w^C \in \mathbb{R}^{d_{model}} wC∈Rdmodel 是行为embedding中的单位(unit)位置的偏置向量,c是unit在embedding中的索引
加入偏置编码之后,用户的行为sessions Q 则更新为:
Q = Q + B E Q=Q+BE Q=Q+BE
多头自注意力
在推荐系统中,用户的点击行为是被许多多样的因素影响的,比如颜色、风格和价格等。多头自注意力可以捕获不同表征子空间的相关性。论文中使用的多头自注意力跟标准的Transformer其实是一样的结构。
让 Q k = [ Q k 1 ; . . . ; Q k h ; . . . ; Q k H ] Q_k=[Q_{k1};...;Q_{kh};...;Q_{kH}] Qk=[Qk1;...;Qkh;...;QkH],其中 Q k h ∈ R T × d h Q_{kh} \in \mathbb{R}^{T \times d_h} Qkh∈RT×dh是 Q k Q_k Qk的第h个head,H是heads的数量, d h = 1 h d m o d e l d_h=\frac{1}{h}d_{model} dh=h1dmodel
那么,第h个head的计算如下式:
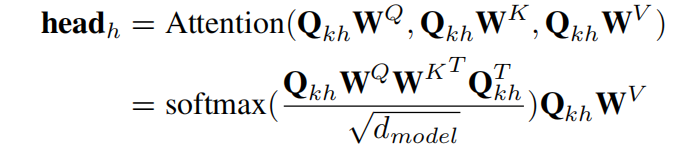
其中, W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV 是线性矩阵。
接着,所有heads的向量进行拼接,喂给前馈网络层(feed-forward network,FFN):
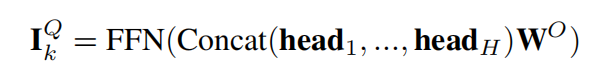
其中, W O W^O WO是线性矩阵,并且同样保留残差连接和layer normalization。
那么,用户的第k个session兴趣 I k I_k Ik 如下式:
I k = A v g ( I k Q ) I_k=Avg(I_k^Q) Ik=Avg(IkQ)
需要注意的是,自注意力的参数在不同的sessions中是共享的。
session兴趣交互层
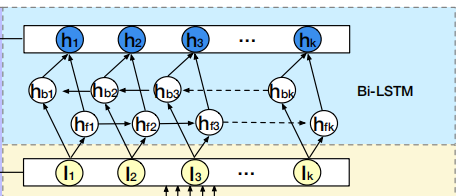
用户的session兴趣与上下文的其他sessions是有着顺序相关性的,对动态的变化进行建模可以丰富session兴趣之间的相关性信息。
而LSTM则是善于捕获这种顺序相关性,能够建模session兴趣之间的交互。
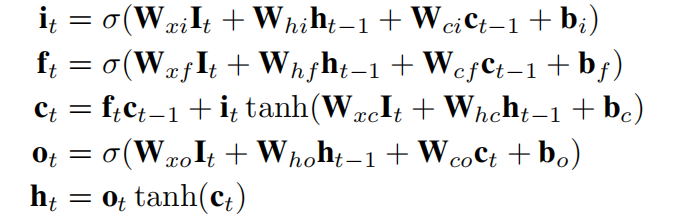
其中, σ ( ⋅ ) \sigma(\cdot) σ(⋅)是sigmoid函数,i,f,o,和 c 分别是输入门控,遗忘门控,输出门控和cell向量,与 I t I_t It有着相同的size。
双向则意味着存在一个前向的RNN和后向的RNN,那么,其隐状态 H 计算如下式:
H t = h f t → ⊕ h b t ← H_t=\overrightarrow{h_{ft}} \oplus \overleftarrow{h_{bt}} Ht=hft⊕hbt
其中, h f t → \overrightarrow{h_{ft}} hft是前向LSTM的隐状态, h b t ← \overleftarrow{h_{bt}} hbt是后向LSTM的隐状态。
session兴趣激活层
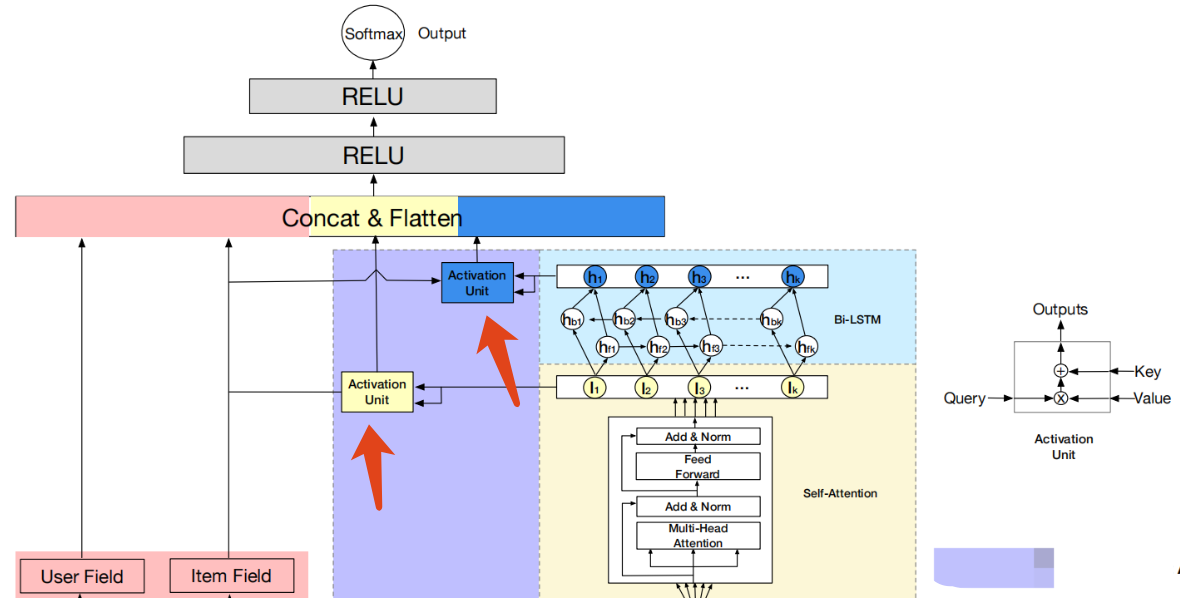
与target item更相关的用户的session兴趣会对用户是否点击起着更为重要的影响。那么,用户session兴趣对于target item的权重计算问题便随之而来。
注意力机制 使用source和target的软对齐已经被证明是一种有效的权重分配方法,论文也使用该方法,考虑target item,session兴趣的自适应表征计算如下式:
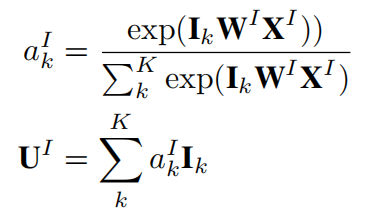
同理,融合了上下文信息的session兴趣表征计算如下式:
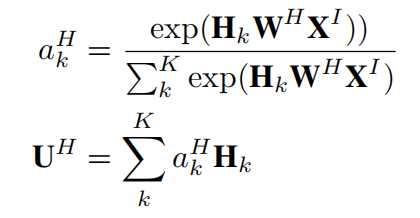
最后,用户属性(User Profile)和item属性(Item profile)的embedding向量,与 U I , U H U^I,U^H UI,UH进行拼接和压平(flatten),输入到最后的MLP层。
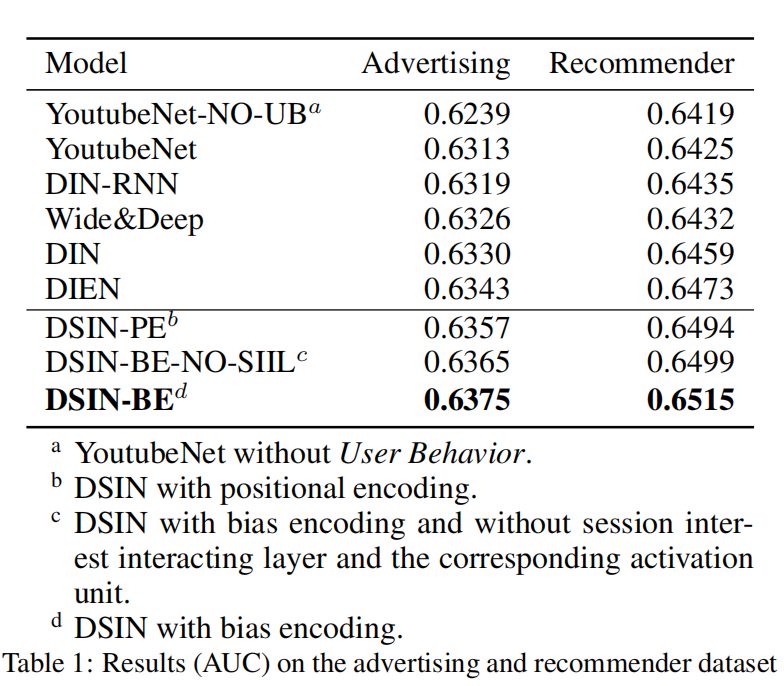
实验结果

总结
- 论文认为在推荐系统中,用户的行为序列是由多个历史sessions构成,在不同的session中展现了不同的兴趣;
- 然后,使用多头注意力来捕获session行为的内存相关性,并且提取每一个session兴趣
- 另外,用户的session兴趣是序列化的,并且彼此相关联,因此用适合序列结构的双向LSTM来捕获session之间的交互和session兴趣的变化;
- 最后再使用注意力机制来激活那些与target item更为相关的session兴趣;
- 不过对于某些场景,比如新闻推荐类似的信息流场景,用户大部分并不是主动行为,那么点击的序列可能就不具备很强的连续性了,因此不满足一个session内的点击都是同类(homogeneous)的,这种场景下DSIN就并不一定适用了。
推荐系统CTR建模系列文章:
CTR特征重要性建模:FiBiNet&FiBiNet++模型
CTR预估之FMs系列模型:FM/FFM/FwFM/FEFM
CTR预估之DNN系列模型:FNN/PNN/DeepCrossing
CTR预估之Wide&Deep系列模型:DeepFM/DCN

















 2668
2668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









