









之前,分享了一篇关于多任务学习的文章:多任务学习MTL模型:MMoE、PLE,同样的还有关于多任务学习中的多目标loss优化策略。
这篇文章则开始一个与多任务学习有着紧密联系的系列:多场景建模学习。
前言
首先,讲一下多任务学习和多场景建模的区别:
- 多任务学习通常是聚焦于单独一个domain(场景、领域)内的不同任务的处理,即不同任务的label空间是不同的;
- 而多场景建模则是关注于多个domain的同一个任务的建模,比如CTR,即不同场景的label空间是一样的,但数据分布是不同的。
(当然,多任务和多场景也可能是同时存在的,因此这两者的联合建模也是一个热门主题,该系列后面也会涉及)
直接将多任务学习应到多场景中,无法高效地利用场景之间在样本空间的关联,以及忽略了不同场景的数据分布的差异。
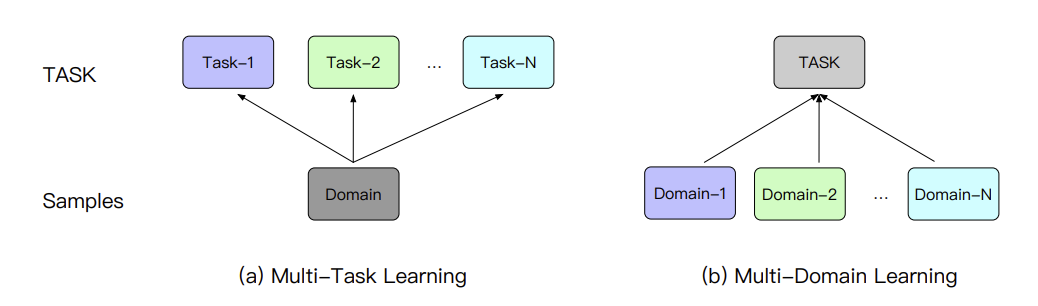
多场景建模
针对这种多场景的业务需求,一般是以下三种解决方案:
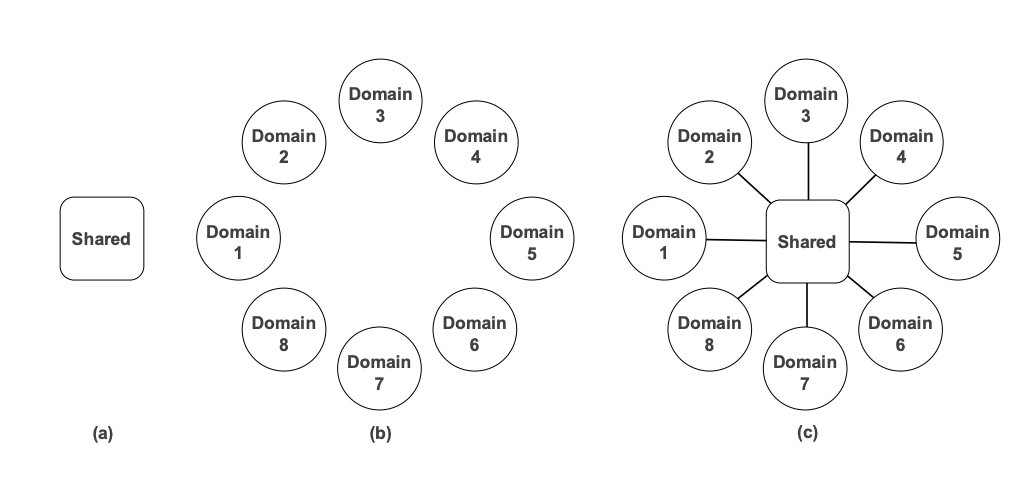
1、所有场景共享一个模型:
不同场景行为数据分布不同,会导致各个场景互相产生负向影响。
2、每一种场景单独建模:
- 这种方案的人力和硬件成本的都比较高,需要同时维护和部署多个模型
- 样本量较少的场景,建模效果较差
- 无法利用所有场景的数据
3、所有场景联合建模:
- 既有每一个场景的独立参数,又有共同的共享参数
- 既可以减少维护成本,同时也能用样本量大的场景去带动小场景。
STAR
CIKM’2021:One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction
https://arxiv.org/abs/2101.11427

如上图,论文列举了淘宝两个不同场景的推荐流。这些业务的用户往往是存在重叠的,因此不同场景会共享部分共同的用户组和商品的,这些场景是存在共性的;但同时不同场景是存在不同的用户组和商品的,甚至即使是同一个用户,在不同场景的行为表现也是不一样的。
针对所有场景共享一个模型难以应对不同的数据分布和捕获不同场景的特定特性,以及每一种场景单独建模无法利用其他场景的数据和共性的弊端,论文提出一种多场景建模方法:Star Topology Adaptive Recommender (STAR) for multi-domain CTR prediction
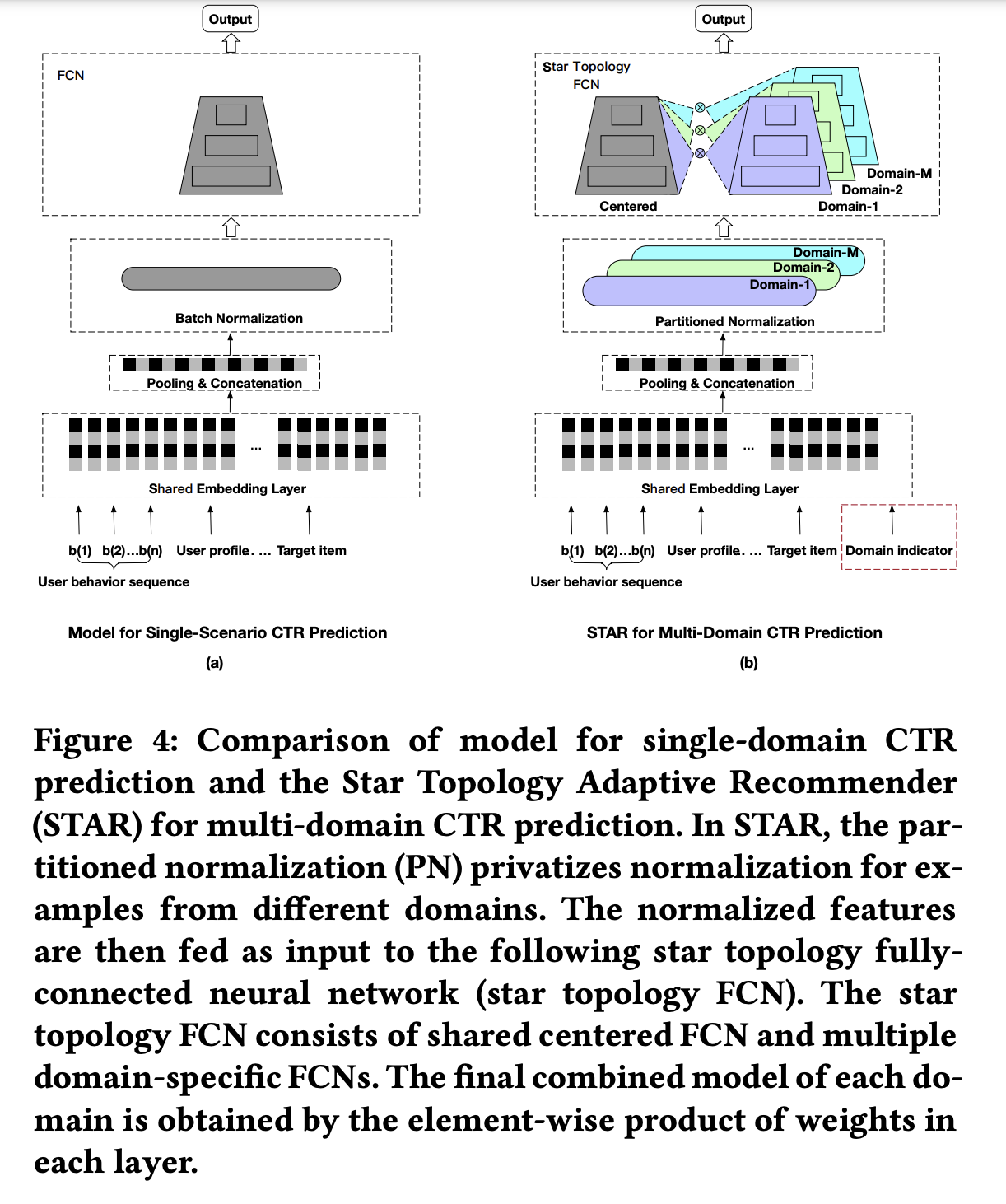
如下图(b)所示,STAR既有共享的中心参数,又有多个场景特定参数的集合,最后模型每个场景的输出是结合共享中心参数和场景特定参数得到的。
- 中心参数是为了学习不同场景的通用行为,这里是为了能够学习和迁移场景之间的共同知识;
- 场景特定参数则是为了捕获不同场景的行为特性,促进更精确的ctr预估。
这使得STAR既促进了场景之间信息高效的转换,学习了场景之间的共性,同时又能捕获不同场景自己的特性。
并且,在每一层网络中都是使用元素位相乘( element-wise product)来作为组合策略。增加的场景特定参数对于embedding层的参数几乎可以忽略不计,因此STAR上线仅仅增加了少量的计算和内存。
符号定义
在序列推荐系统中,模型的输入包括用户的历史行为、用户画像属性、候选物品属性(target item feature)、其他特征比如上下文信息,对用户u在物品m上的预估CTR y ^ \hat{y} y^ 为:
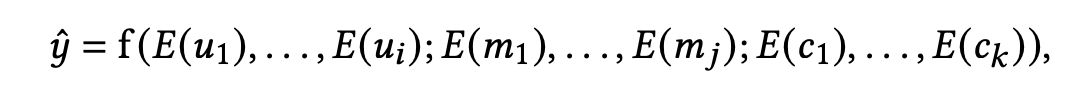
- { u 1 , . . . , u i } \{u_1,...,u_i\} {u1,...,ui} 是用户属性的集合,包括历史行为和其他画像属性
- { m 1 , . . . , m j } \{m_1,...,m_j\} {m1,...,mj} 是target item的属性集合
- { c i , . . . , c k } \{c_i,...,c_k\} {ci,...,ck} 是其他属性的集合
- E ( ⋅ ) ∈ R d E(\cdot) \in \mathbb{R}^d E(⋅)∈Rd 是embedding layer,将离散的IDs映射到密集向量(dense vectors)
多场景建模是构建单个CTR模型同时为M个场景 D 1 , D 2 , . . . , D M D_1,D_2,...,D_M D1,D2,...,DM 输出精准的CTR预估。模型输入也可以简化(x,y,p),x为多个场景的共同输入,比如上述的用户历史行为和画像特征, y ∈ { 0 , 1 } y \in \{0,1\} y∈{0,1} 为是否点击的标签, p ∈ { 1 , 2 , . . . , M } p \in \{1,2,...,M\} p∈{1,2,...,M} 则为当前样本属于哪个场景的指示器。
Embedding Layer
如上一小节提到,embedding layer是将离散的IDs映射到密集向量(dense vectors)。映射到低维的embeddings之后,常规实践是将历史行为embedding进行聚合为固定长度的向量,比如之前介绍的 DIN 或者 DIEN,也是论文使用的方法,然后与其他特征的embeddings进行拼接。如下图:
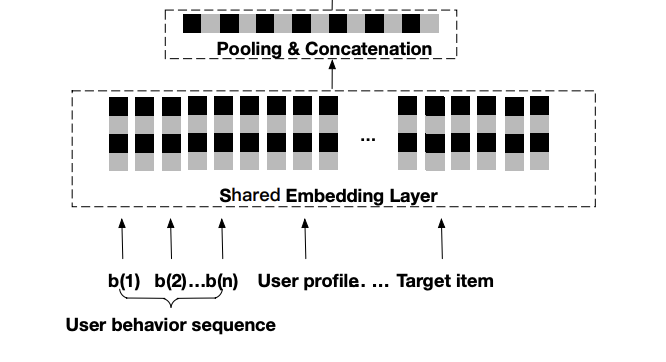
在工业推荐系统,embeddings的参数量是整个CTR模型的绝大部分,远远超出其他参数比如全连接网络,这导致在有限的数据下,是很难学习到场景特定的embeddings,因此应该选择所有场景共享embedding层的参数,即同一个ID特征在不同场景下共享同一个embedding,这也能够非常有效地减少内存和计算。
Partitioned Normalization
上述提到,原始特征转换为低维的embeddings之后会pooling和聚合成固定长度的向量,这个先成为中间表征,记为z。为了更快和更稳定地训练深度网络,将标准化网络应用到z是一个常用做法。
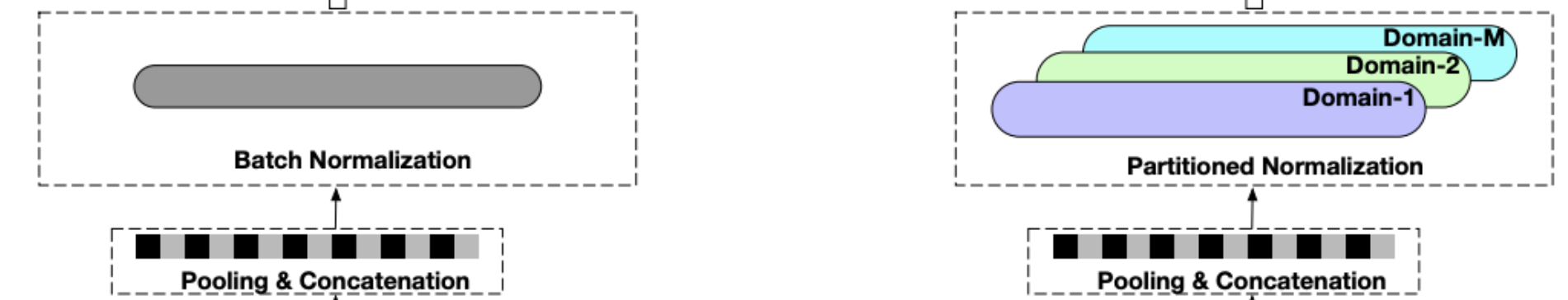
batch normalization (BN)是其中一种高效的代表性方法,起着关键的作用。BN是一种针对所有样本的全局标准化,具体公式如下:
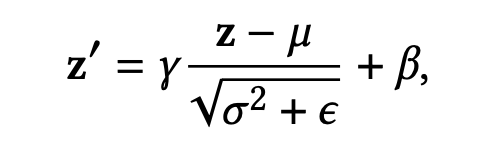
z ′ z^{'} z′是BN的输出, γ \gamma γ 和 β \beta β 是可学习的scale和bias, σ 2 \sigma^2 σ2 和 μ \mu μ 是当前批次样本的方差和均值, ϵ \epsilon ϵ 是防止分母为0的平滑常数。
而在推理阶段, σ 2 \sigma^2 σ2 和 μ \mu μ 则会替换为移动平均的统计方差和均值 E E E 和 V a r Var Var,如下式(不理解BN的可以看看之前的文章batch_normalization的正确使用姿势):
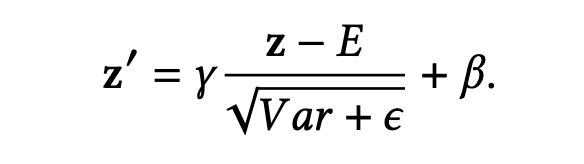
不过 BN需要假定所有样本是 i.i.d.(独立同分布),但论文认为针对多场景数据是局部 i.i.d.的,即属于同一个场景的数据才满足 i.i.d.
因此,使用全局的BN会模糊场景之间的差异,给模型带来负向影响。为了能够捕获每一个场景的特定数据特征,提出了一种分区标准化 partitioned normalization (PN) :私有化场景自己的标准化统计和参数,如下式:
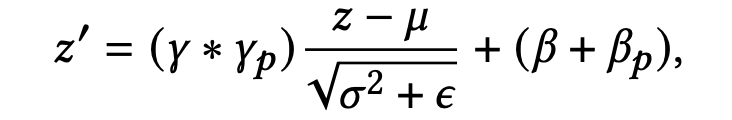
-
需要假定当前样本批次全是从场景p采样而来
-
γ \gamma γ 和 β \beta β 是全局的scale和bias,而 γ p \gamma_p γp 和 β p \beta_p βp 便是场景p特定的scale和bias。
-
对于每一个样本批次,PN使用共享的 γ \gamma γ与场景特定的 γ p \gamma_p γp相乘作为最后的scale,来实现根据场景指示器来自适应的scale中间表征z。 β p \beta_p βp也是同理。
由于每一个样本批次都是来自同一个场景,那么PN累积的移动平均的统计方差和均值便也是场景特定,那么推理阶段,对于场景p,PN则为下式:
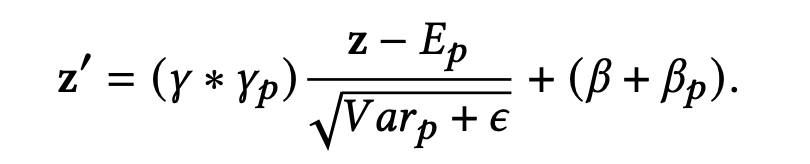
Star Topology FCN
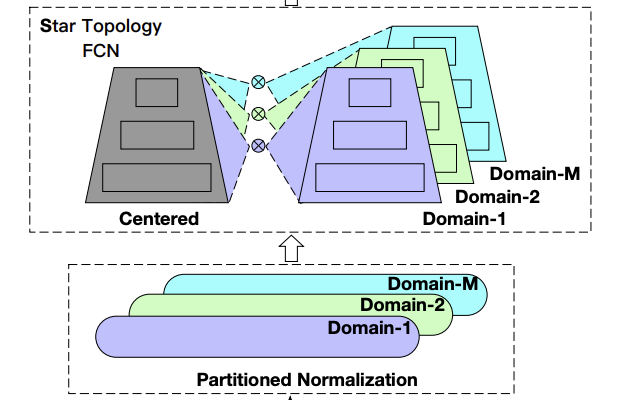
如上图,经过FN层之后,表征 z ′ z^{'} z′会进入到一种星形拓扑结构的多层全连接神经网络,称为star topology multi-layer fully-connected neural network (star topology FCN)。
star topology FCN包括共享的中心FCN和多个独立的场景FCN,因此总的FCN数量为M+1。第p个场景的输出是由共享的中心FCN和场景特定FCN组合而成的,共享的中心FCN参数可以学习场景之间的共同行为,而场景特定FCN参数可以捕获不同场景的特定行为,促进更精确的CTR预估。
star topology FCN结构如下图所示:
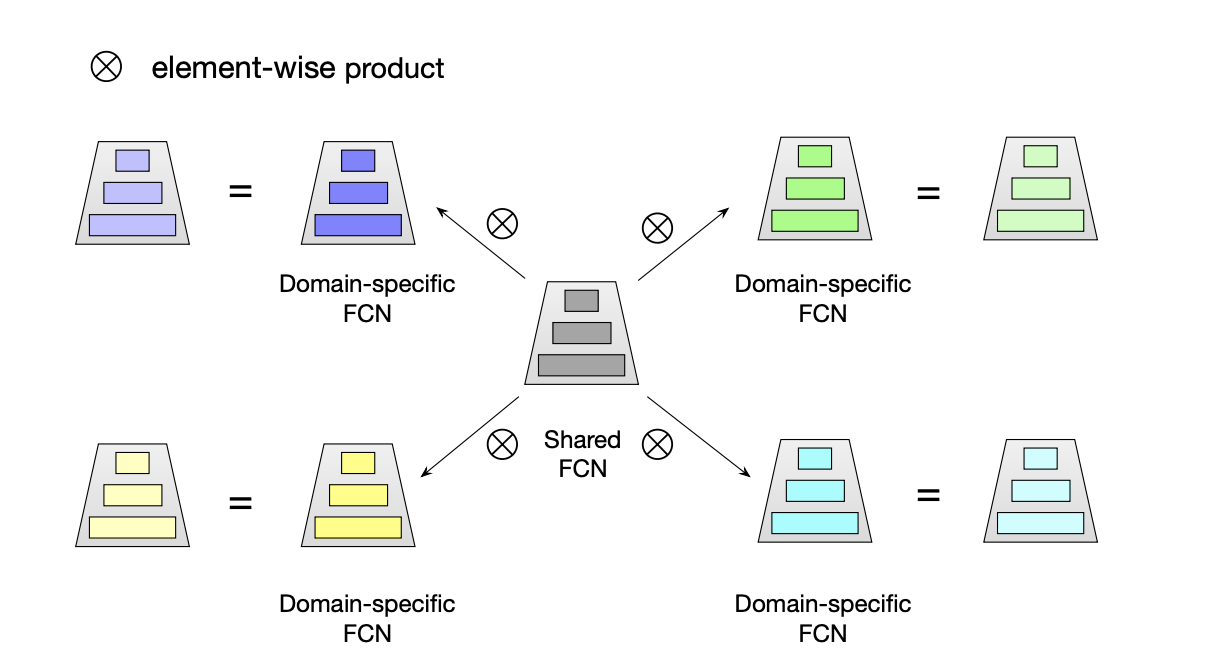
具体地,W和b为共享FCN的权重和偏置。对于第p个场景, W p W_p Wp 和 b p b_p bp 则是对应该场景FCN的权重和偏置。那么, 最后场景p的权重 W p ⋆ W_p^{\star} Wp⋆ 是由前面两者进行element-wise product而来,而偏置 b p ⋆ b_p^{\star} bp⋆ 则是两者相加,如下式, W , W p ⋆ ∈ R c × d W,W_p^{\star} \in \mathbb{R}^{c \times d} W,Wp⋆∈Rc×d:
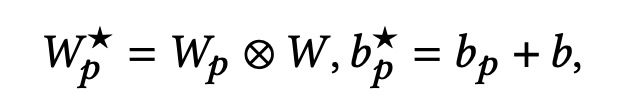
得到Star Topology FCN的权重 W p ⋆ W_p^{\star} Wp⋆和偏置 b p ⋆ b_p^{\star} bp⋆,那么场景p的最终输出则为:

- 其中 i n p ∈ R c × 1 in_p \in \mathbb{R}^{c \times 1} inp∈Rc×1, o u t p ∈ R d × 1 out_p \in \mathbb{R}^{d \times 1} outp∈Rd×1, ϕ \phi ϕ 是激活函数。
除了计算表达式之外,STAR还一个比较关键的参数更新机制:
- 共享参数是由所有样本来贡献梯度去更新的,而场景特定参数只靠对应场景的样本来更新
- 这样有助于捕获场景之间的差异来得到更精准的CTR预估,同时又可以学习到场景之间的共性
- 这其实很符合直觉,场景自己对自己的私有参数负责,不应由其他场景来干扰
辅助网络
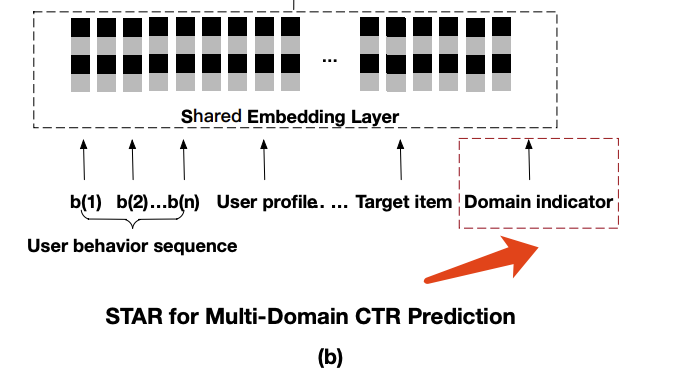
注意到,在Embedding Layer之前还有一个标注了红框的Domain Indicator(场景指示器),这个便是用于辅助网络的。
论文认为,传统的方法即直接将所有特征平等地喂给复杂的模型,在多场景CTR预估任务中,是很难自动学到场景之间的区别/特点的。因此,提出一个好的多场景CTR预估模型应具备以下两个特性:
- 有关于场景特性的丰富特征
- 让这些特征可以更容易和直接地影响最终的CTR预估
这个直觉的背后是描绘场景信息的特征是非常重要,因为它降低了模型去捕获场景之间的区别的难度。
那么,基于以上论文提出的两个特性,额外引入了:
- 场景embeddings:即把场景指示器当做特征ID,映射为对应场景的embedding向量;
- 还有一个简单的辅助网络:2层的全连接网络层
为了更直接地影响最后的CTR预估,辅助网络的输出会与star topology FCN的输出相加:
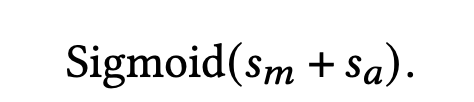
- s m s_m sm 是star topology FCN的一维输出,即star topology FCN的最后输出
- s a s_a sa 便是辅助网络的最后输出,辅助网络的输入是场景指示器embedding拼接其他的特征
最后,所有场景的交叉熵loss如下式:
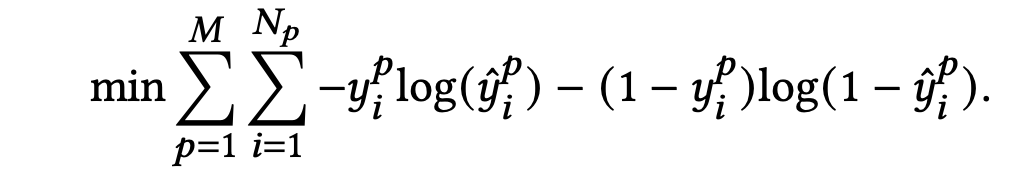
实验结果
评估指标
论文使用的是常用的指标:Area under the ROC curve (AUC),并加上用户加权的AUC:
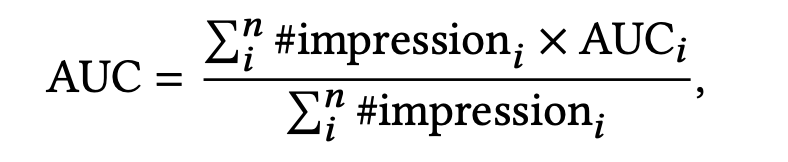
其中,n是用户的数量, i m p r e s s i o n i impression_i impressioni 和 A U C i AUC_i AUCi 是第i个用户的曝光数和AUC。
参数配置
整体参数:
- 优化器:Adam
- 学习率:0.001
- batch_size:2000
具体模型:
- Base模型:embedding layer+pooling&concatenation layer+batch normalization+7-layer fully-connected network,其中pooling&concatenation layer使用的是 DIEN
- Shared Bottom模型:共享embedding layer+7-layer fully-connected network
- MulANN:Multi-Domain Adversarial Learning
- MMoE:可以看之前的介绍文章,多任务学习MTL模型:MMoE、PLE。专家的数量等于场景的数量,每一个专家网络是7-layer fully-connected network
- Cross-Stitch:Cross-Stitch Networks for Multi-task Learning
模型效果对比
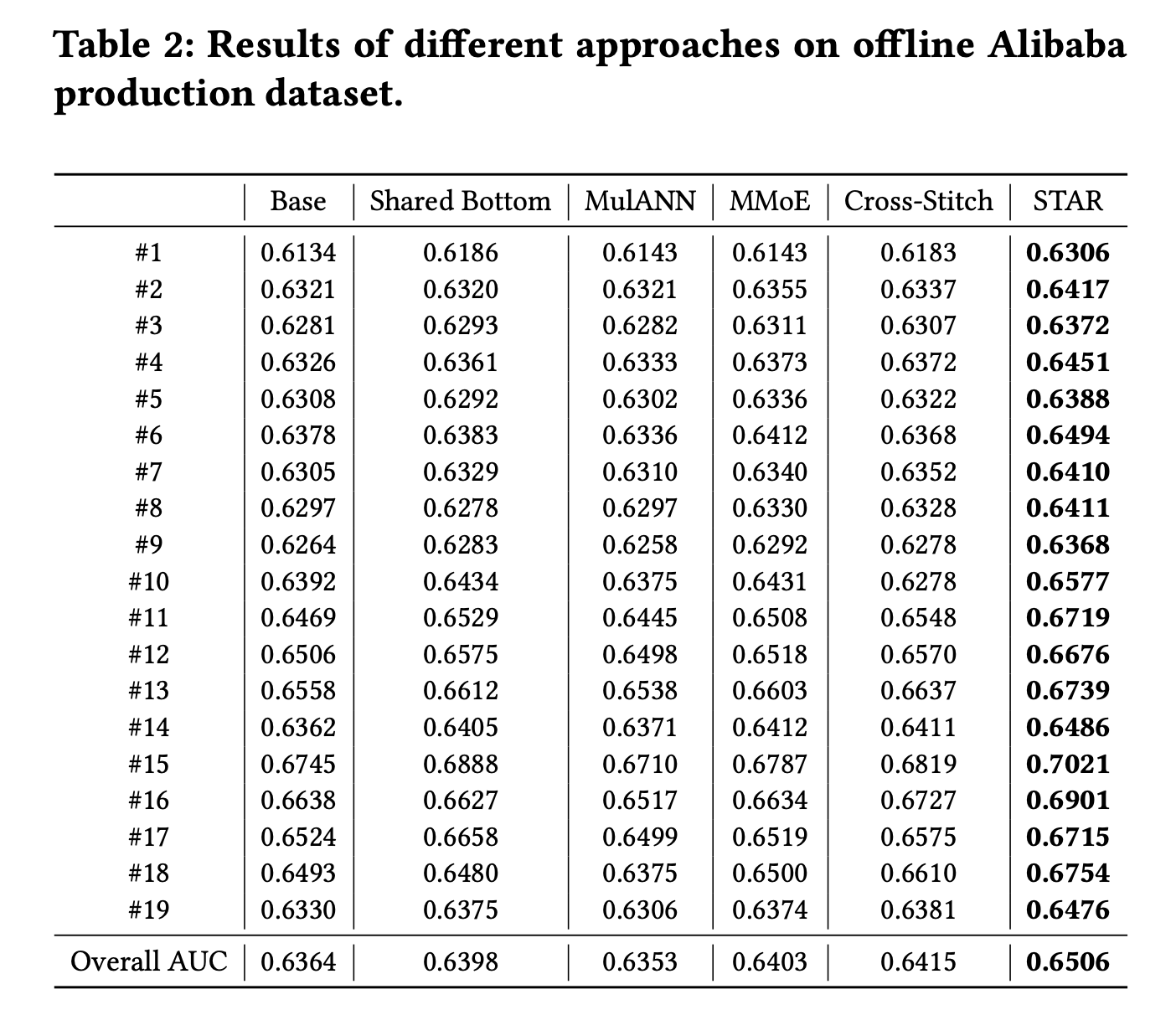
- Shared Bottom, MMoE, Cross-Stitch和STAR都比Base取得了更好的效果,这也证明了探索场景之间的关联和捕获不同场景的区别/特性能够提升预估效果
- 但是有些场景下,除了STAR,都有其他模型比Base效果反而更差的情况,比如#5,#6,#16,可能是不同场景的学习存在冲突;而STAR便是使用star topology来避免这个问题,只使用对应场景来更新场景特定参数
- STAR可以比Shared Bottom取得更好的效果,这证明顶层网络共享场景信息对于多场景学习的重要性,STAR是所有场景共享了同一个label空间
- STAR比MMoE, Cross-Stitch都取得更好的效果,这证明显式建模场景的关联相比隐式建模(如门控网络)的优越性。
消融实验
下面是对每个组件的消融实验:
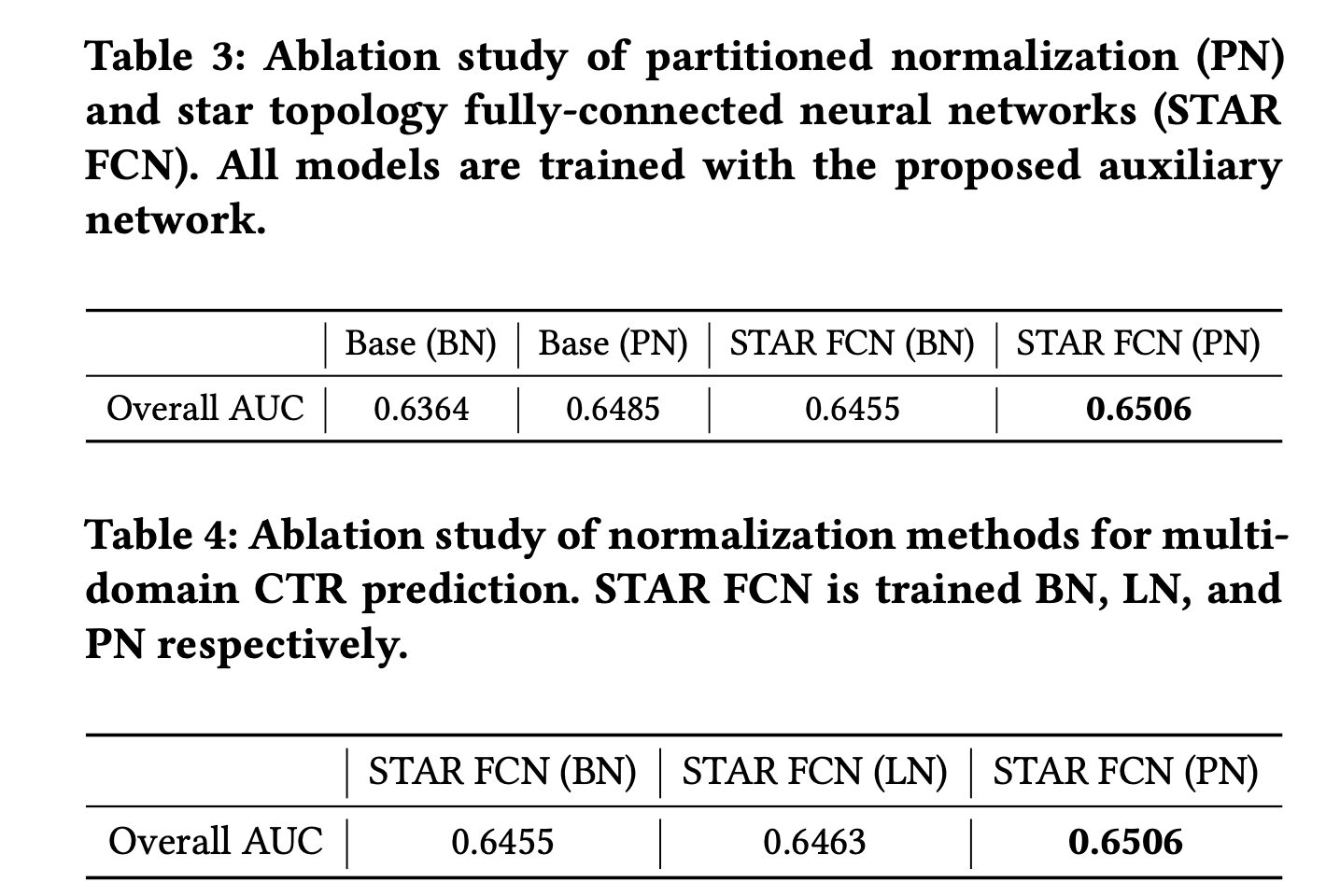
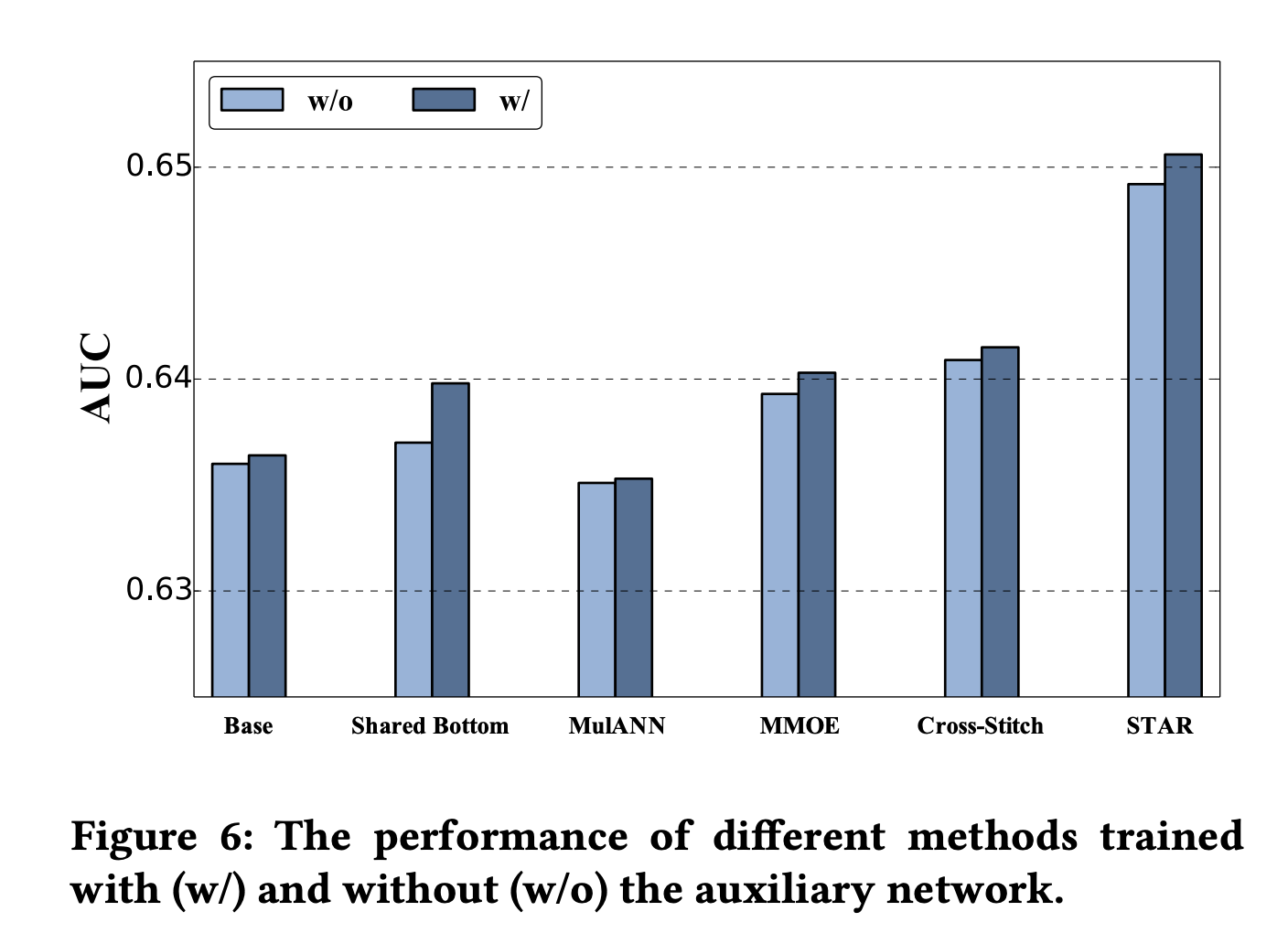
总结
针对多场景任务建模,STAR提出了几个有效的组件来探索场景之间的关联和捕获不同场景的区别/特性:
- Partitioned Normalization:基于场景分区的标准化
- Star Topology FCN:组合共享中心参数和场景特定参数,对应场景样本更新场景特定参数
- 辅助网络:场景特征更直接地去影响最后的预估
代码实现
虽然论文中 Partitioned Normalization 假定了一个批次的样本都来自同一个场景,但下面仓库的实现已经支持了一个批次的样本可以接收多个不同的场景数据。
tensorflow 2.x:github
tensorflow 1.x:github

















 2201
2201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









