







小波矩是FPGA板已有的模块,而深度学习框架下的MNIST的测试准确率可轻松地到99%以上。这里得到的效果不足以超越后者,由于内部影响依然做了该实验。所以,这些时间只够买个教训~ 如下图所示:

1. 单分类器
(1) 自定义 数据集
已有方法的分类是每俩类比较1回,这样的分类器针对的数据不完备,修改后准确率大跌。
| 方法\类别 | 飞机 | 汽车 | 人 | 平均 |
|---|---|---|---|---|
| 已有方法 | 84.55 | 98.37 | 78.86 | 87.26 |
| 未降维 | 86.18 | 98.37 | 84.55 | 89.70 |
| 降维 | 91.87 | 100.00 | 94.31 | 95.39 |
| 降维集成 | 89.43 | 97.56 | 94.31 | 93.77 |
| 提取边缘 | 68.29 | 67.48 | 79.67 | 71.81 |
(2) MNIST 数据集
这里以数字 1,3,6,8 的小波矩特征为例。其中,横轴为特征的索引,纵轴为具体某个特征值。
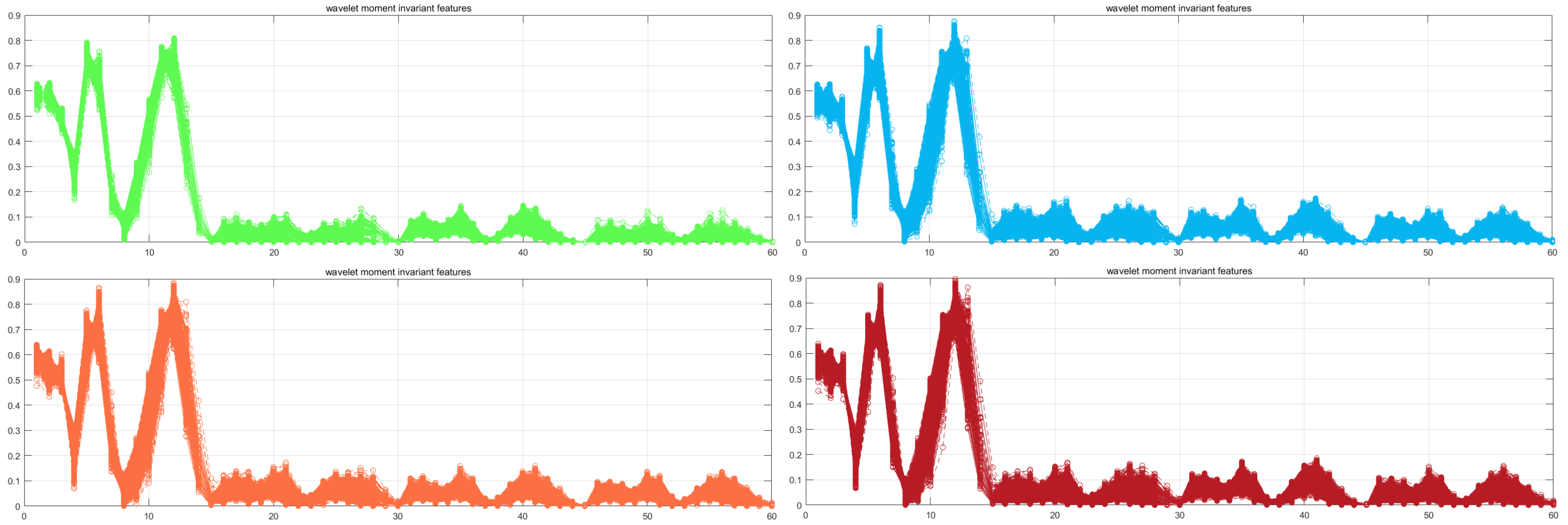
支持向量机用于2分类问题:假设要识别数字
1
,那么训练样本中数字
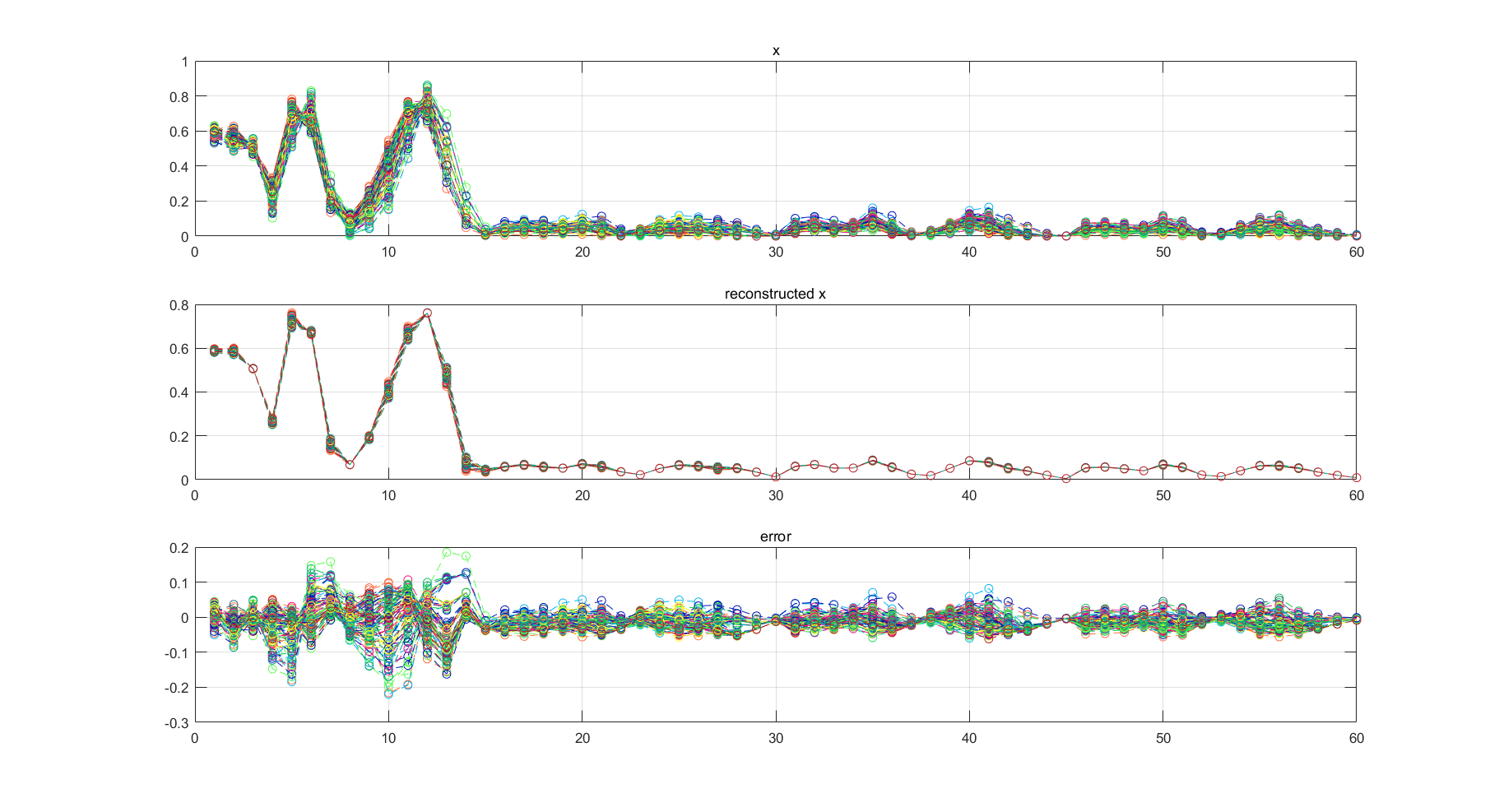
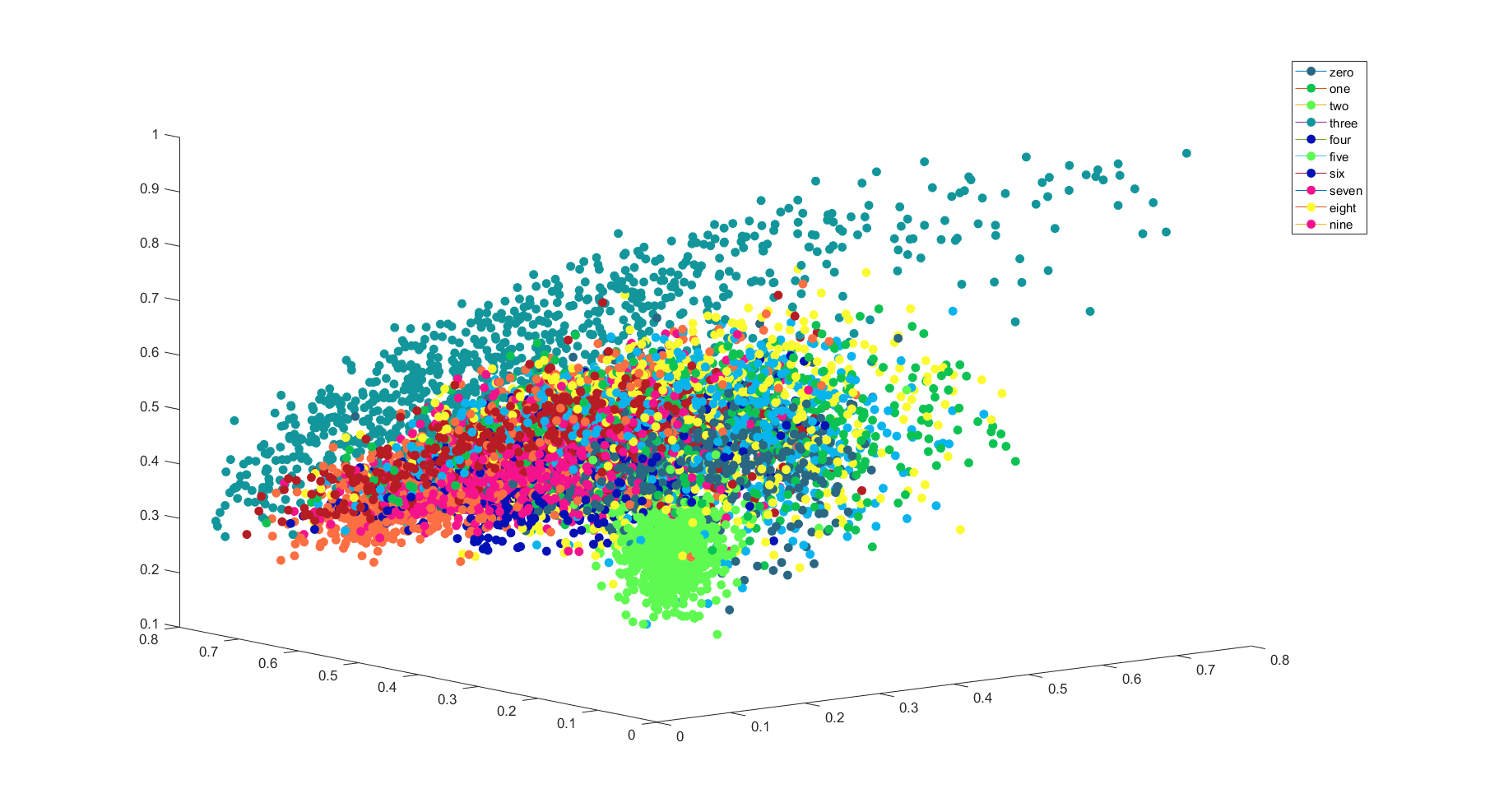
重建后有些特征值波动很小,区分性很小,所以选择方差较大的特征。此处给出归一化后的方差变化较大的3个特征,看起来分类好像有戏的样子(其实重叠的点也不少)~
重建后的样本送入采用RBF核的支持向量机得到每个数字的分类器。每个数字的支持向量机可以对自己的类别作二分类判断。
| 准确率\类别 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 错误 | 90.20 | 88.65 | 89.68 | 89.90 | 90.18 | 91.08 | 90.42 | 89.72 | 90.26 | 89.91 | 90.00 |
| 正确 | 99.16 | 99.34 | 92.01 | 93.89 | 95.23 | 93.86 | 95.52 | 95.89 | 96.13 | 95.25 | 95.63 |
如果不随机采样,训练时负样本太多会导致支持向量机测试时分类结果全为-1,如同上面错误行的结果。单分类器的正确率一般,与往年1的效果相比,手动设计特征的劣势就体现出来了~
2. 多分类器
假设数字
0
~
这就是不同目标的分类器间的集成问题。理想的解决方法应该与集成学习不太一样,因为集成学习主要指多个分类器针对同一目标共同决策的方法。
按照集成学习的思路往下走,每个数字的支持向量机的输出为概率形式,但它并不能够直接使用,需计算其后验概率。已知每个训练样本的后验概率和类别标签(0~9),用多元线性回归拟合。
(1) 自定义 数据集
标签为1对应飞机,说明飞机的训练数据和测试数据的差异较大,或者训练和测试数据的分布差不多,但小波矩提取飞机的特征不明显。


(2) MNIST 数据集
直接用多元线性回归把后验概率的多类分类问题转换为回归问题。实际上,后验概率的准确度取决于每个分类器的性能。若多分类问题中每个二分类问题划分的难度有差异,也可能影响子分类器的性能,比如测试集中的标签0和1的分类效果明显比其它数字好,但0和1数字分类器会削弱其它数字分类器的影响,而它俩与其它数字的分类一点关系没有。
换句话说,假设这个世界上只有3种职业:厨子,医生和警察。平时厨子烧得一手好菜;警察爱岗敬业功绩满满;但医生比较惨,医闹不断。他们的社会影响力由同1套规则度量。突然有1天新型病毒爆发,领导召集这3个职业的代表开会。最后,医生提出的方案由于社会影响力太小被否决。
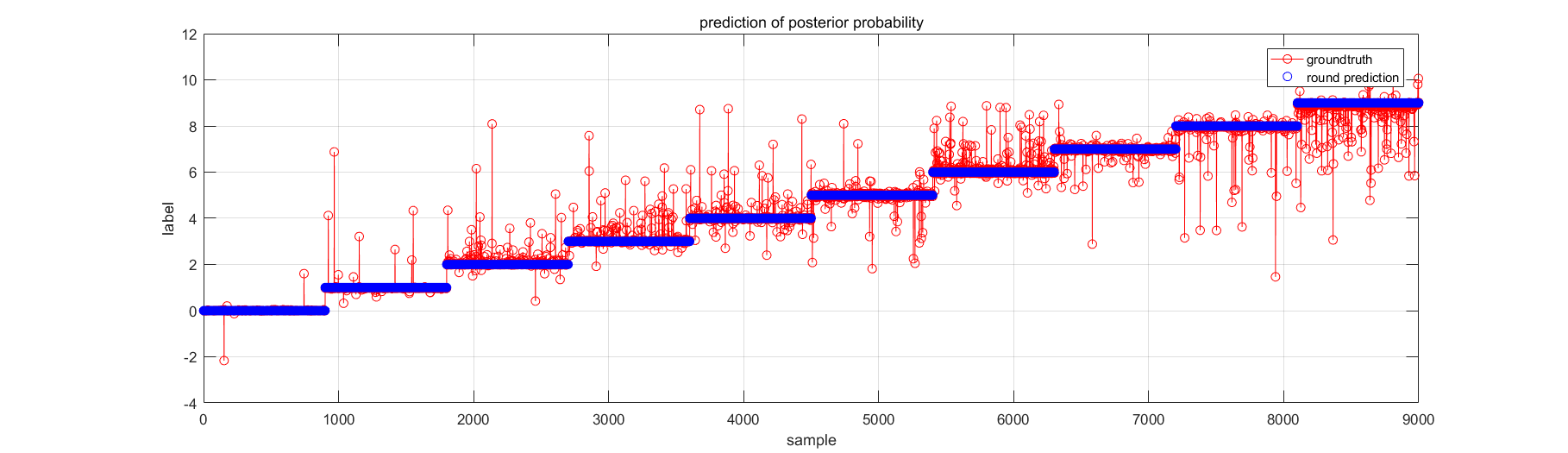
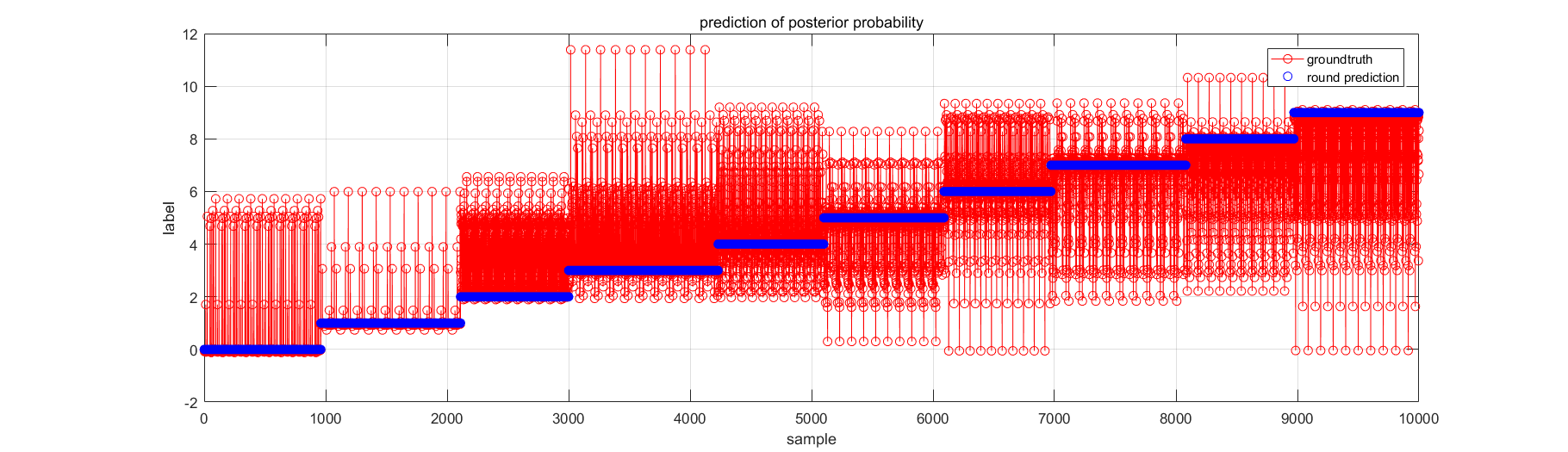
MNIST和自己的训练数据的集成效果一般;MNIST测试数据的集成效果不好(准确率仅64.6%),但自己的数据却可以接受。说明自己的训练和测试数据的区分度没有MNIST大,换句话说,自己数据的模型允许一些过拟合。所以,当幸运地碰到了简单的实际问题,且什么方法都浪得飞起时,还是要经过benchmark的考验来说服自己~ (╬ ̄皿 ̄)凸
另外,不同目标的分类器集成还是要看实际情况。这里的MNIST,若非要用比较弱的小波矩表示特征的话,暂且选择各分类器的后验概率的最大值吧~















 1700
1700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









