







对抗的深度卷积生成网络来学习无监督表示
主线为 Alec Radford 与 Luke Metz 等人的论文“Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks”1。
摘要
近年来,计算机视觉应用中使用卷积网络的监督学习被广泛采用。相比之下,无监督学习受到更少关注。本文帮助缩小有监督学习与无监督学习中成功应用 CNNs 的差距。引入一类名为对抗的深度卷积生成网络 (DCGANs) 的卷积网络,该类网络有一定的结构约束,且表明它可很好地用于无监督学习。训练不同的图像数据集证明对抗的深度卷积对可学习到判别器和生成器中从物体局部到场景的分层表示。此外,针对新任务学到的特征表明它们作为通用图像表示的适用性。
1. 简介
从大量未标记数据集学习可重用的特征表示的研究活跃。计算机视觉中,可利用无数未标记图像和视频来学习不错的中间表示,诸如图像分类等不同的有监督学习任务可使用这些表示。训练对抗的生成网络 (GANs),然后利用部分的判别网络和生成网络为有监督任务提取特征。GANs 漂亮地替代了最大似然方法。此外可认为 GANs 的学习过程和缺少启发式损失函数 (像素间相互独立的均方误差) 对表示学习很有吸引力。据知 GANs 训练不稳定,往往使生成器的输出无意义。试图理解和可视化 GANs 所学和多层 GANs 的中间表示的已发表研究有限。
本文,有如下贡献
- 卷积 GANs 的拓扑结构上,提出和评估一系列约束来使大多数设置中的网络训练稳定。 命名该类结构为深度卷积 GANs。
- 为图像分类任务训练判别器,相比其它无监督算法,该判别器的效果很好。
- 可视化 GANs 学到的滤波器,经验表明特定的滤波器已学到绘制特定的物体。
- 生成器有趣的数值属性便于操作很多不同语义的生成样本。
2. 相关工作
2.1 从未标记数据学习表示
一般的计算机视觉和图像上下文中,无监督表示学习问题被研究得很好。一个无监督表示学习的经典方法是对数据聚类 (如用 K-means),并利用所得簇来提高分类分数。图像上下文中,分层聚类图像块来学习有力的图像表示。另一个流行的方法是训练自编码器 (卷积,堆叠),自编码器分离码的含义和位置,将图像编码为简洁的码,且解码来尽可能精确地恢复图像。这些方法可从图像像素学到很好的特征表示。深度置信度网络在学习分层表示中效果不错。
2.2 生成自然图像
图像生成模型的研究分为两类:参数的和非参数的。
从现有图像的数据库中,非参数模型往往匹配图像块来匹配图像,并用于合成纹理,超像素和绘画。
生成图像上参数模型的研究 (如 MNIST 数字或合成纹理) 广泛。然而,直到最近,生成真实世界中的自然图像才有进展。变分采样方法来生成图像取得一定的成功,但采样往往模糊。另一方法是用迭代的前向传播过程来生成图像。对抗的生成网络生成的图像易受噪声影响且生成图像的内容难以理解。该方法的 Laplacian 金字塔扩展版可生成更高质量的图像,但串联多个模型引入的噪声仍使生成图像中的物体看起来不稳定。最近循环网络方法和反卷积方法也在生成自然图像上取得一定的成功。然而,有监督任务上还未用这些方法的生成器。
2.3 可视化 CNNs 内部
神经网络为黑盒方法一直为人所批判,使用时不会以简单的人类处理的形式来理解网络的作用。CNNs 中,用反卷积和最大激活单元滤波可大致了解网络中每个滤波器的作用。类似地,输入用梯度下降,可观察激活了的部分滤波器的目标图像。
3. 方法与模型结构
曾有人尝试用 CNNs 缩放 GANs 来生成图像,结果失败了。这使得 LAPGAN 的作者开发一种可替换缩放的方法,通过迭代上采样低分辨率的生成图像,从而使网络模型更可靠。且我们试图用有监督学习中常用的 CNN 结构来缩放 GANs 时也遇到困难。然而,经过大量模型探索,确定有一类模型在一系列数据集上训练稳定,且可训练更高分辨率和更深的生成模型。
方法的核心是利用和修改最近 CNN 结构的 3 个可见的变化。
第 1 个变化为所有的卷积网络用跨卷积 (strided convolutions) 来替换确定的空间池化函数 (如最大池化),使网络可学到自己的空间下采样。将该方法用于生成网络,使其学习自己的空间上采样,同时用于判别网络。
第 2 个变化为删除卷积特征上的全连接层的趋势。最明显的例子是最新的图像分类模型中用到的全局平均采样。发现全局平均采样更稳定,但收敛变慢。直接将卷积最高层分别连接至输入和输出效果很好。GAN 的第 1 层输入为噪声的均匀分布
Z
,仅用矩阵乘法对输入使用全连接,但结果变形为
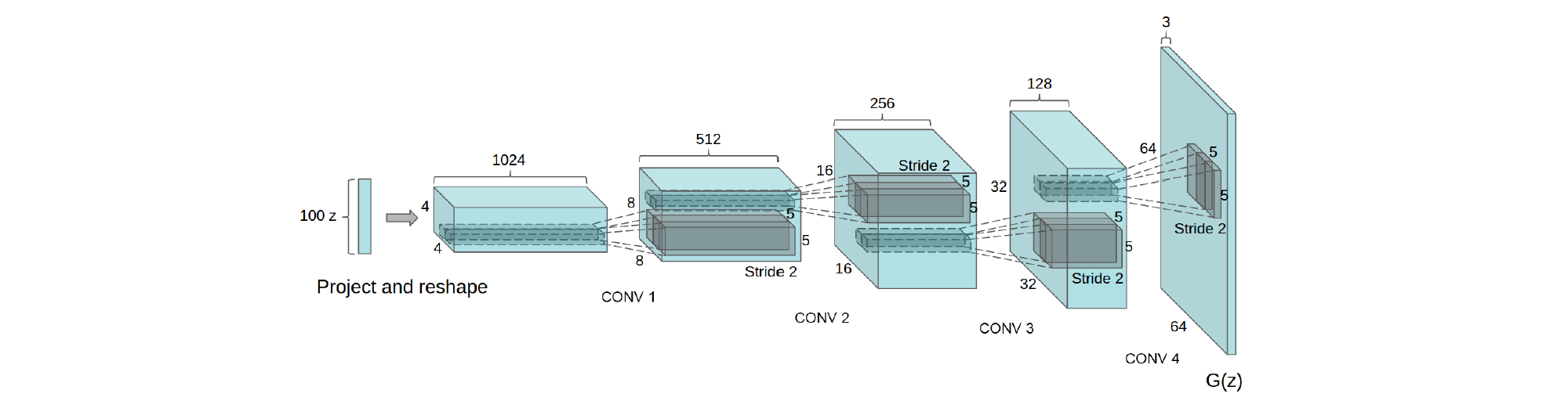
第 3 个变化为 Batch 归一化,通过归一化每个输入使其均值为
0
,方差为
生成网络除了输出层用 Tanh 函数,其它层用 ReLU 激活函数。观察到有界的激活函数可使模型学习更快饱和及覆盖训练分布的颜色空间。发现判别器中的漏 (leaky) ReLU 激活函数尤其在高分辨率模型中的效果不错。与这里相反,原有的 GAN 论文用 maxout 激活函数。
提到的激活函数
tanh(x)=ex−e−xex+e−x1 2
relu(x)=max(0,x)
leaky_relu(x)={x,ax,if1x>0otherwise1 3
maxout(x)=maxj∈[1,k](zj)1 4
稳定的深度卷积 GANs 的结构指南
- 用生成器的跨 (strided) 卷积和判别器的部分跨 (fractional strided) 卷积来替换所有的池化层;
- 判别器和生成器中都用 batchnorm;
- 删除深度结构中的全连接隐含层;
- 生成器中除了输出层用 Tanh,所有其它层用 ReLU 激活函数;
- 判别器中所有层用漏 ReLU 激活函数。
4. 对抗训练的细节
3 个数据集 (Large-scale Scene Understanding (LSUN),Imagenet-1k 和新组合的 Faces) 上训练 DCGANs。每个数据集的使用细节如下。
训练图像仅缩放至 Tanh 函数的范围
[−1,1]
,无预处理。用 mini-batch 大小为
128
的随机梯度下降来训练所有的模型。均值为
0
,标准差为
4.1 LSUN
随着图像生成模型生成的样本质量的提高,会出现过拟合与训练样本的记忆。为演示更多数据和更高分辨率生成时模型如何缩放,用包含超过三百万训练图像的 LSUN 卧室数据集来训练模型。最近的分析显示模型学习的速度与模型泛化性能间有直接的关系。模仿在线学习,下图显示每个训练时期的样本和收敛后的样本来证明模型并未通过简单地过拟合或记忆训练实例来生成高质量样本。

1 个训练周期后生成的卧室。理论上,模型可记忆训练样本,但当用小学习率和 minibatch SGD 训练时却不是这样。据我们了解,无任何实验表明 SGD 和小学习率的训练有记忆。

5 个训练周期后生成的卧室。多个样本间的噪声纹理重复表明视觉上欠拟合。
4.1.1 删除重复数据
删除简单的图像重复数据来进一步减少生成器记忆输入实例的可能。训练实例经过 32∗32 中心裁剪后,用其拟合一个 3072−128−3072 去噪的 Dropout 正则的 ReLU 自编码器,阈值化编码层 ReLU 激活函数的输出。该方法可保留有效的信息,并为可线性时间去重复的语义哈希提供简单的形式。
语义哈希 (Semantic Hashing) 是指计算每个对象 (图像或文本) 二进制码。两个对象编码的海明距离度量两者的相似度 5。
哈希碰撞 (Hash Collision) 是指重复数据删除系统用唯一的短编码标识数据块。但不能将任何文件或文件块一对一地映射至短编码。即多个文件可能具有相同的哈希值 6。
4.2 FACES
随机查询人名的网络图像,抓取人脸图像。从 dbpedia 获取人名。数据集来自
10
K人的
3
M张图像。运行 OpenCV 检测人脸,检测到的人脸仍有足够高的分辨率,共约
4.3 IMAGENET-1K
Imagenet-1K为无监督学习的自然图像来源,按图像较小边长缩放,且中心裁剪大小为 32∗32 的图像用于训练,无数据增广。
5. DCGANs 性能的实验验证
5.1 GANs 提取特征来分类 CIFAR-10
为评价无监督表示的学习方法,常应用无监督表示方法为有监督数据集提取特征,其顶层特征送入线性模型,并评估线性模型的表现。
CIFAR-10 数据集上,调整好的 K-means 提取单层特征被证明是很好的基线。当使用大量特征图 (4800) 时达到
80.6%
的准确率。扩展基线方法至无监督多层的特征提取达到
80.2%
的准确率。为评估有监督任务中 DCGANs 学到的表示,训练 Imagenet-1k 且利用判别器所有的卷积层,最大池化每层的表示来得到一个
4∗4
的空间网格。展平这些特征,串联成一个
28672
维的向量,送入 L2 正则的线性 SVM 分类器,达到
82.8%
的准确率。
串联的向量大小为 (1024+512+256)∗(4∗4)=28672 。
与基于 K-means 的技术相比,判别器的特征图少得多 (最顶层有 512 个特征图) ,但多层 4∗4 的空间位置使整个特征向量大小更大。DCGANs 的表现不如典型 CNNs (无监督方式训练常规 CNNs 来区分具体选择,增广和来自源数据集的示例样本)。微调判别器的表示可进一步改善表现。此外,DCGANs 使用 Imagenet-1k (而非 CIFAR-10) 训练,表明学到的特征的区域鲁棒性。

根据上面的描述,典型 CNNs 的向量维度应该是 1024 ; 虽 DCGAN 的判别网络顶层特征图数目为 512 个,但送入 SVM 的却是展平的 28672 维向量,如果 4∗4 的网格为单个特征图,那么特征单元的数目应为 1792 个。Table 2 第 2 列大多数为判别特征送入分类器的最大数目。但是,比较浅层,仅用到的深层顶层和联合多层时的深层顶层的数目,Table 2 似乎对前两者不太公平呢~
5.2 GANs 提取特征来分类 SVHN 数字
为数据标签稀少时的有监督学习,街景门牌号数据集 (SVHN) 上用 DCGAN 判别器的特征。类似 CIFAR-10 实验中准备数据的规则,从源数据集分离出

1000 类的 SVHN 数字分类。
虽 CIFAR-10 数据集上没赢过相同结构的有监督 CNN,但 SVHN 数据集上超过 6.37% 。但个人觉得有监督 CNNs 实验为何要用相同的数据呢?数据增广的有监督 CNNs 的实验结果并未给出。总的来说,与有监督学习相比,该方法有竞争力。
6. 网络内的研究与可视化
研究用不同的方式训练生成器和判别器。训练集上不使用最近邻搜索。小的图像变换一般会欺骗像素的最近邻域或特征空间。对数似然是个差的指标,所以不用它来定量评价模型。
6.1 潜在 (latent) 空间中游走
第 1 个实验为理解潜在空间的流形。游走在学好的流形上可了解记忆的指示 (如有急剧的过渡) 和空间分层折叠的方式。如果潜在空间中游走导致生成图像的语义变化 (增加或删除的物体) ,则模型学到与物体相关的有趣表示,如下图。

Z
中用一系列的
6.2 可视化判别特征
大量图像数据集上有监督 CNNs 可学到很强大的特征。此外,场景分类时训练得到的有监督 CNNs 学习物体检测器。大量图像数据集训练得到的无监督 DCGAN 也可学到有趣的分层特征。
引导的 (guided) 反向传播训练,判别器学到的特征在卧室典型的部分 (如床或窗户) 激活。为比较,相同图像上用随机初始化的特征来作为基线。

右侧为判别器最后一个卷积层的前 6 个学到的卷积特征,可视化引导反向传播中最大轴对齐响应 (axis-aligned responses)。注意到很少的特征反应为床— LSUN 卧室数据集的中间物体。左侧为随机滤波器的基线,与前面的响应相比,无判别性和随机结构。
6.3 操作生成表示
6.3.1 遗忘绘制特定物体
除了判别器学到的表示,还不清楚生成器学到的表示。生成的样本表明生成器学到主要场景组成 (如床,窗户,门和各种家具) 的表示。为研究生成表示的形式,实验试图从生成器中完全删除窗户。

上一行:未删除窗户的生成样本。下一行:经过删除窗户滤波的生成样本。一些窗户被移除,一些窗户被替换为视觉表面相似的物体 (如门和镜子)。尽管图像质量下降,场景的整体组成依然相似,表明生成器可很好地从物体表示来抽出场景表示。也可从图像中删除其它物体,并修改生成器绘制的物体。
6.3.2 向量操作人脸样本
评价学到的词表示时,表明简单的算术运算可在词表示空间中显示丰富的线性结构。典型的例子有

视觉概念的向量运算。每列平均
此外,物体的运算证明脸部姿态在 Z 空间中呈线性。

从
7. 总结与未来工作
为训练对抗的生成网络,提出一系列稳定的结构。证明对抗的网络可为有监督学习和生成模型学到很好的图像表示。仍有一些形式的模型不稳定—注意到当模型训练时间越长时,模型有时会从滤波器子集崩溃至单一的振荡模式。
今后需要解决它的不稳定。将该框架扩展至视频 (帧预测) 或语音 (语音合成的预训练特征) 将会很有趣。研究学到的潜在空间的特点也会很有趣。
小结
“方法与模型结构”中针对稳定的生成模型得出一系列结论。且与比较数字指标的实验不同,“网络内的研究与可视化”部分的实验内容非常有趣。
此外,Soumith Chintala 7 提到,对生成器来最大化判别器犯错的对数似然;网络有 Batch 归一化时,定义所有真实样本的 minibatch 为 AR,且所有伪样本的 minibatch 为 AF,一半真实样本和一半伪样本为 AH。训练网络时,AR 和 AF 交替训练 GAN 可行。但用 AH 训练却玩不起 GAN 的最大最小双人游戏,此时 AH 用到的损失函数为
log(1−D(G(z)))
。
与前文一样,未经校正。如有疑问,错误或原文可脑补之处,欢迎分享~ ˋ( ° ▽、° )















 1986
1986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









