






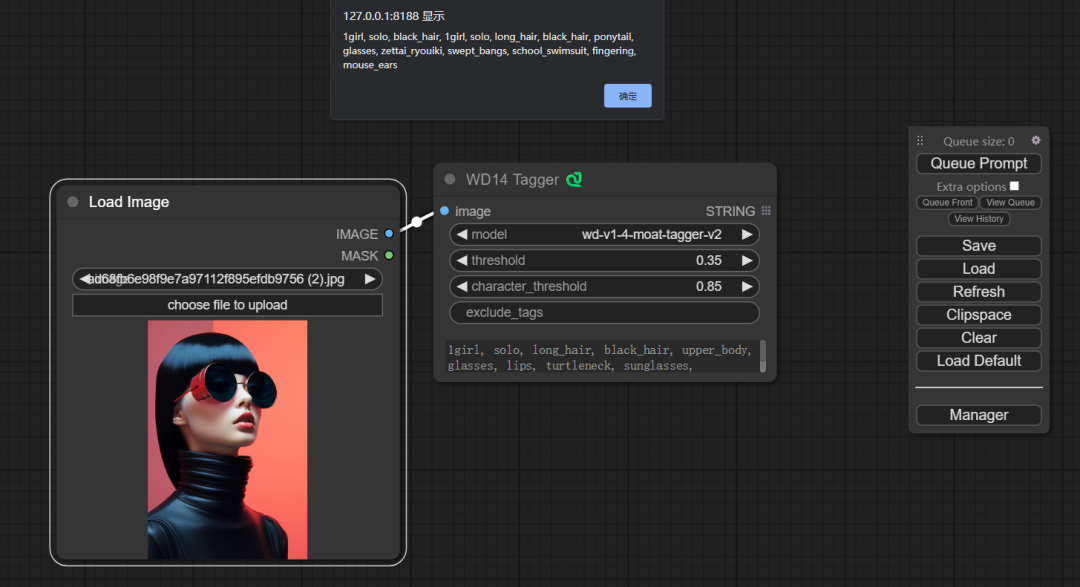
github.com/pythongosssss/ComfyUI-WD14-Tagger
从图片中提取tag,ComfyUI-WD14-Tagger 使用了4种模型:
最新的模型 MOAT
最受欢迎的模型 ConvNextV2
主要任务是进行语义分割 —— 一项计算机视觉任务,其目标是将图像中的每个像素分类为一个类别或对象。其目标是生成一张图像的密集像素级分割地图,其中每个像素被分配给一个特定的类别或对象。
MOAT
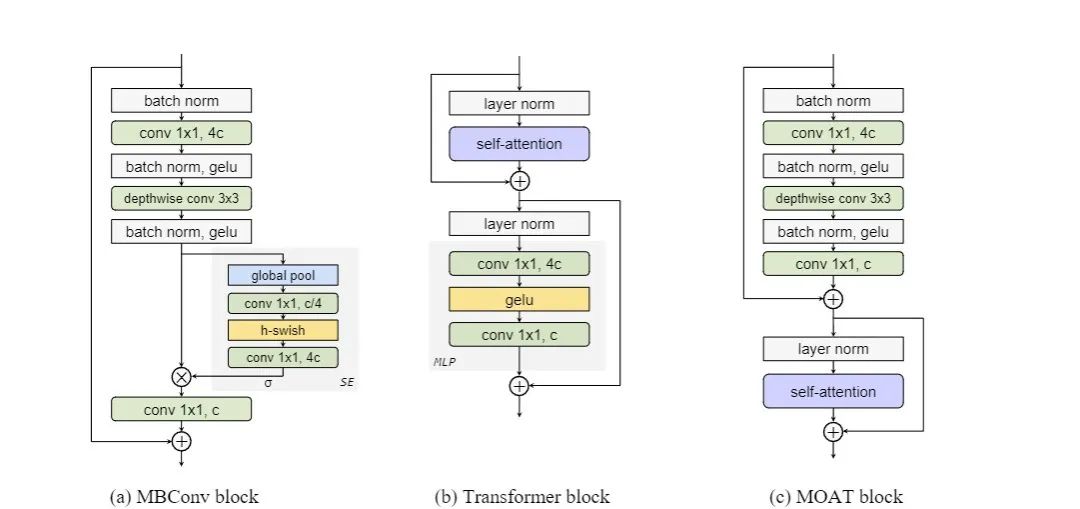
一种名为MOAT的神经网络,它建立在MOBILE CONVOLUTION和ATTENTION的基础上。与当前的工作不同,MOAT将MBConv block (2018) 和Transformer block (2017) 合并为一个MOAT block。
实验结果表明,MOAT网络取得了出色的性能。
主要有以下几种任务:
ImageNet-1K图像分类任务
COCO对象检测任务
实例分割任务
ADE20K语义分割任务
MOAT在这些任务上都取得了令人印象深刻的结果,并展示了其在不同识别任务中的适用性。
谷歌 DeepLab2
A TensorFlow Library for Deep Labeling
MOAT是基于 DeepLab2 代码库开发的,可以直接通过Deeplab使用。DeepLab2是一个用于深度标记的TensorFlow库,旨在为图像像素标记任务提供统一和最先进的TensorFlow代码库,包括语义分割、实例分割、全景分割、深度估计甚至视频全景分割等。
github.com/google-research/deeplab2
更多欢迎关注:

















 845
845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









