






【基本信息】
论文标题:Exciting Action: Investigating Efficient Exploration for Learning Musculoskeletal Humanoid Locomotion
发表期刊:ArXiv
发表时间:2024年7月16日
【访问链接】
论文:https://arxiv.org/pdf/2407.11658
代码:https://github.com/henriTUD/musculoco_learning
【科学问题】
人类的肌肉骨骼系统十分复杂,产生一个肢体运动需要多块肌肉在时间和空间上完美协同才能完成。例如,步行作为人类最基本的下肢运动能力,需要双腿和躯干的各种肌群完美配合才能实现。因此,假设我们已经构建了能够模拟人类的完整肌肉骨骼模型,如何协同控制躯干和下肢的各个肌群来控制肌骨模型模仿人类的步行(包括跑步)的功能呢?
现有的研究中,已经有不少的人使用了强化学习方法尝试在肌骨模型的运动仿真中解决这类问题,例如强化学习中的DDPG方法,但这类方法在肌肉数量较多时的效果不佳。
这个问题是一个典型的多控制器协同的规划和控制问题,并且是一个正向回报极其稀疏的问题,导致强化学习方法所必须的回报函数(或损失函数)的设计难度较大。使用过强化学习来控制足式机器人的读者都知道,如果只是通过步行距离或者步行速度等来设计我们的回报函数,在大多数情况下我们得到的都是负向的结果。对于人类肌骨模型这个极其复杂的多控制器协同控制系统来说,这个问题显得更加明显。
【核心思路】
肌肉模型
肌骨模型的控制过程主要是对肌肉模型的控制,所以作者建立了肌肉-肌腱单元(MTU)来作为最基本的控制单元: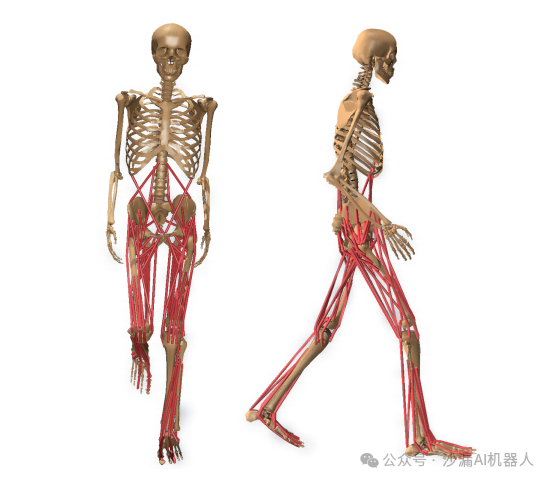 其中,该控制单位输出的力只与该单元是否激活、CE的长度和速度有关,CE(Contractile Element)是一个可以收缩的结构;也与PE(Passive Element,可看作一个被动弹簧结构)所产生的被动力相关。通过控制该单元输出相应的力可以实现对肌骨模型中每一块肌肉的控制,从而产生运动过程。
其中,该控制单位输出的力只与该单元是否激活、CE的长度和速度有关,CE(Contractile Element)是一个可以收缩的结构;也与PE(Passive Element,可看作一个被动弹簧结构)所产生的被动力相关。通过控制该单元输出相应的力可以实现对肌骨模型中每一块肌肉的控制,从而产生运动过程。
本文中包含的下肢运动自由度设定如下表所示,一共16个自由度,需要92个MTU控制单元。
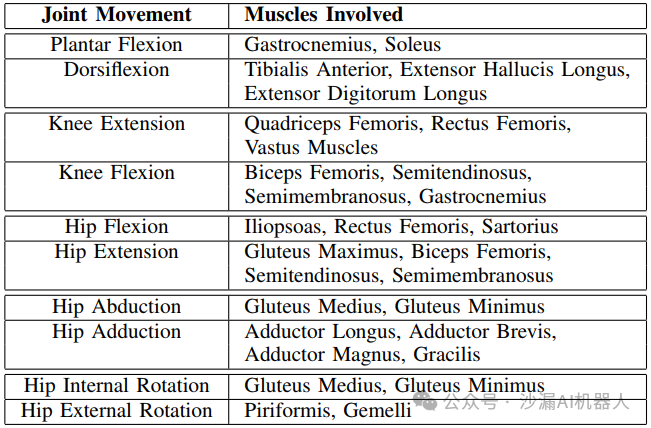
这是一个典型的过度驱动的系统,即驱动单元远多于所控制的自由度,这是为了对每一块肌肉进行更加精细的控制而设计的,也符合人类肌肉的运动控制规律,在肌骨模型的仿真中比较常见。
骨骼模型
肌肉模型是弹性变化的,骨骼模型是刚性的,该论文引入了从OpenSim导出的人体骨骼模型OpenSimModel 。
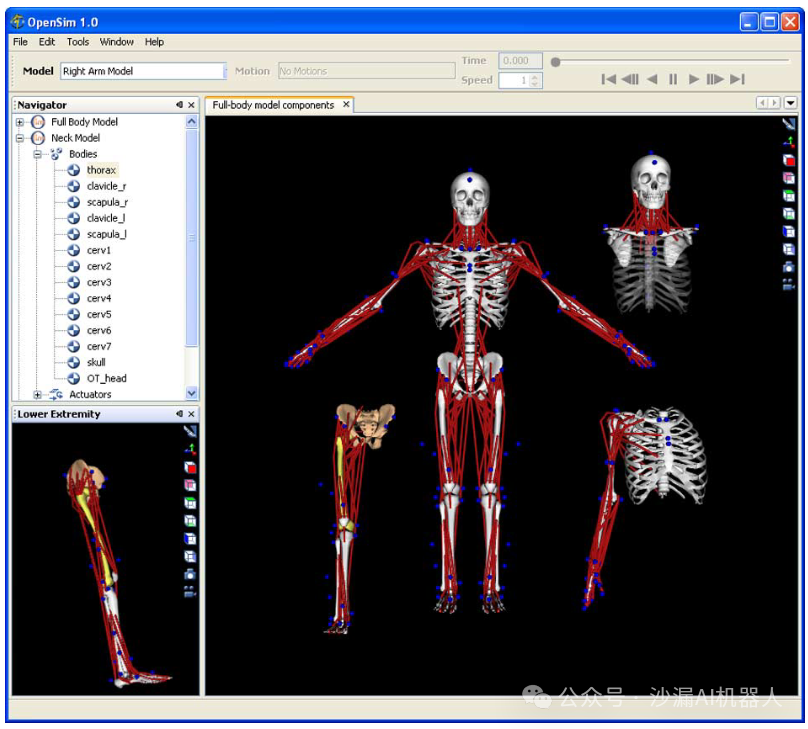
在此基础上,作者结合强化学习引入了生成式对抗模仿学习算法来构建上述肌骨模型的运动控制策略,引入了Trust Region Policy Optimization (TRPO) 算法来构建强化学习内部循环的优化过程。
创新部分
作者在这里引入了生成式对抗模仿学习算法来解决多肌肉群协同学习和控制的问题,
其中,典型的传统强化学习算法容易忽略本文中肌骨模型驱动系统的特性,将其当成一个普通的强化学习问题解决,因此作者定义了两个关键问题来提升这个系统的控制表现。
由于环境比较简单,只是平地场景,回报很稀疏,容易引起算法的梯度消失从而导致学习过程发散而不能收敛到一个确定的策略。因此,论文引入了包括“有限支撑”和“增量目标直接引入策略”的方式来解决熵无序增长导致梯度消失的问题;
由于肌肉模型只能在一个方向上产生力矩,导致在一个步态周期中大部分肌肉其实处于非激活状态,对于各个肌肉群的协同控制学习十分不利,甚至无法学习肌肉的协同过程。因此,作者引入了特殊的协同关系预测算法来解决肌肉协同控制的学习问题。
【实验和结果】
论文的实验平台为机器人领域较为常见的仿真平台Mujoco,引入了一个包括16自由度、92块肌肉-肌腱单元的人类肌骨模型用于实验。所使用的运动数据(主要是步态数据)来自LocoMujoco,包括人类肌骨模型和各类双足机器人在平地上的步行和跑步的运动数据,步行速度为1.25m/s,跑步速度为2.5m/s。

LocoMuJoCo is an imitation learning benchmark specifically targeted towards locomotion. It encompasses a diverse set of environments, including quadrupeds, bipeds, and musculoskeletal human models.
其中,强化学习所需的策略网络、评价网络等使用多层感知机(MLP)来构建。实验结果展示:
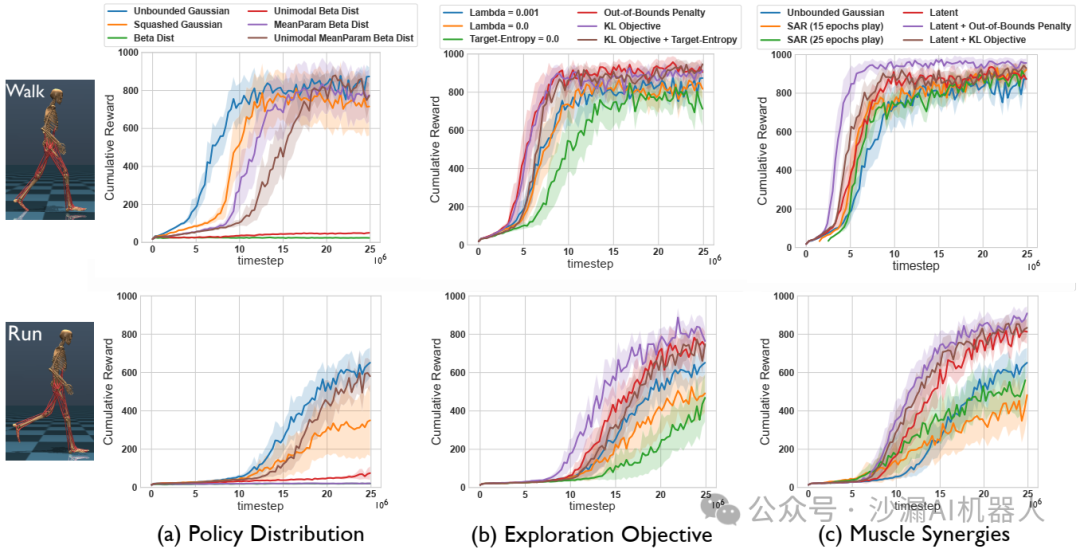
该论文提出的方法最终可以实现所构建的人类肌骨模型的步行和跑步过程中92块肌肉模型的控制学习,相比于其他方法,能够处理的肌肉模型数量更多。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











