










前言
本文将介绍CoppeliaSim与Gym框架结合来构建强化学习环境的基本方法,通过一个强化学习的经典控制例子cartpole来讲述如何在Gym的框架下,构建基于CoppeliaSim的强化学习仿真环境,如何使用visdom来实时查看训练的过程,以及使用一些现有的强化学习方法(基于stable-baselines3)来训练构建好的模型。本文所涉及的代码已开源在github,开源地址:
https://github.com/chauby/CoppeliaSimRL。
本文配有更加详细的视频教程,详见:
CoppeliaSim联合Gym强化学习入门![]() https://class.guyuehome.com/detail/p_614c2a2de4b04518c617021b/6
https://class.guyuehome.com/detail/p_614c2a2de4b04518c617021b/6
先来看一个效果视频:
CoppeliaSim联合Gym构建强化学习环境
本文所构建的强化学习环境已经在Ubuntu 20.04上面测试通过,所需的环境配置为:
-
CoppeliaSim 4.2
-
Python 3.6+ 以及一些常用的包
-
Gym
-
Stable-baselines3
-
Pytorch
-
Visdom
一. Gym环境介绍
Gym(https://gym.openai.com/)是OpenAI公司开源的强化学习框架,内部自带了一些仿真环境,用户安装Gym以后可以直接使用。Gym自带的仿真环境比较简单,我们也可以利用它的框架去结合现有的一些机器人仿真环境来实现我们自己的强化学习环境,本文就以CoppeliaSim为例进行讲解。
想要利用Gym的框架,我们需要实现一个自定义的环境类,在类当中还需要实现以下几个函数:
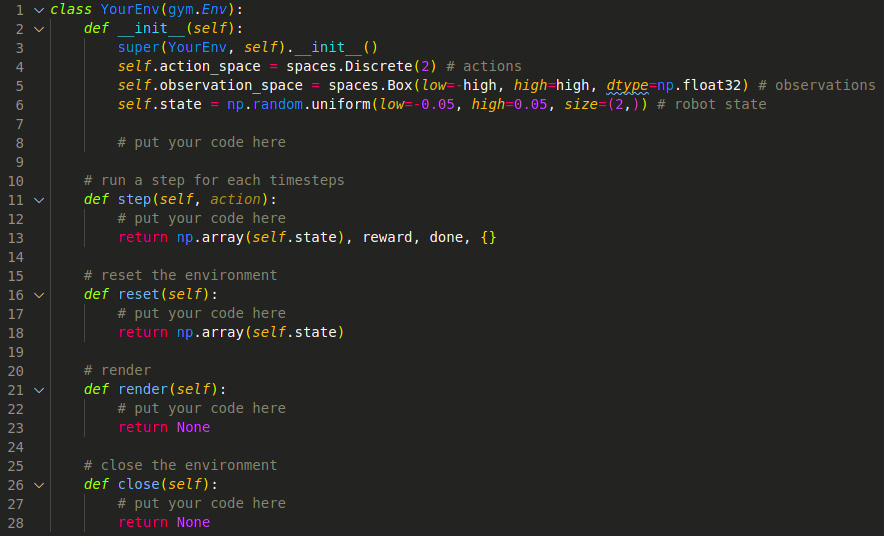
其中,
-
action_space表示机器人的动作空间,可以是离散的,也可以是连续的,比如2就表示机器人在实际运行时一共有2个动作可以选择。
-
observation_space表示机器人的观察空间,用于表示机器人的observation范围,可以是离散值也可以是连续值。
-
state表示机器人的当前状态,可以是机器人的关节角度,也可以是机器人的位置和速度等等,取决于你想采用什么方式来表示机器人当前的状态。某种意义上来说,state是对observation的一次采样,每次step我们就能从observation中得到当前的state。
这几个函数的作用从函数名就能看出来了,Gym框架在运行我们定义的环境的时候会分别依次去调用每个函数,因此,我们只需要把我们自己仿真环境的接口与这几个函数结合就能实现Gym与仿真环境的交互过程,从仿真环境中获取数据,施加action到仿真环境中控制机器人运动。
二. 仿真环境的构建过程
2.1 CoppeliaSim中的模型
在CoppeliaSim中构建仿真模型cart-pole,两个关节,一个横向移动的滑块和一个旋转关节。旋转关节设定为被动运动,通过控制滑块的左右移动来实现杆的平衡。
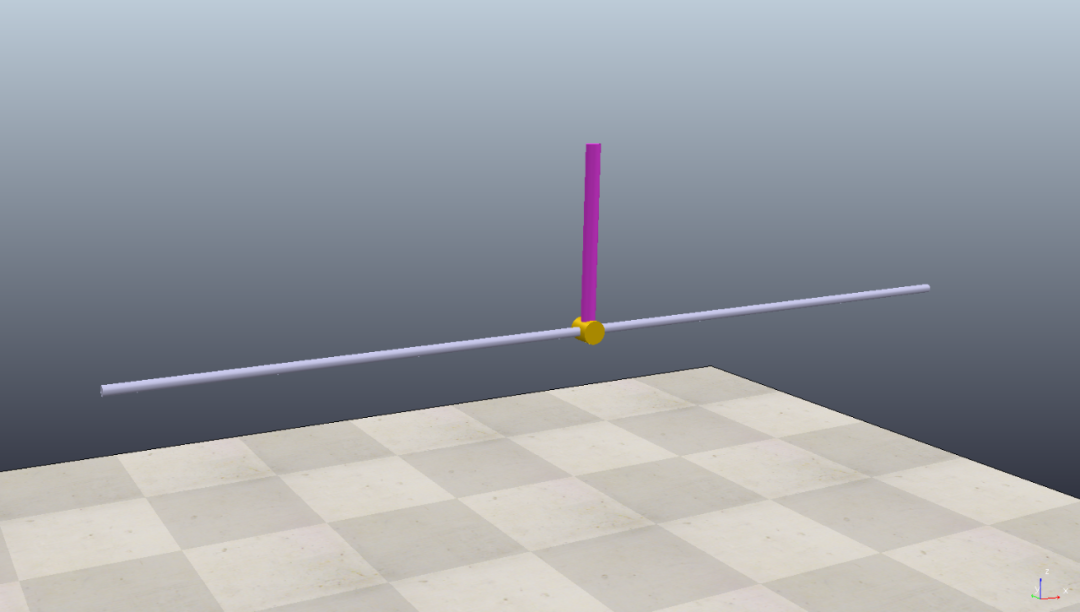
在不给定任何外力控制的情况下,竖着的杆受到重力的影响会倒下,如下图所示:

基于CoppeliaSim官方提供的API接口,我们使用Python代码来远程获取模型的关节角度和位置等,需要构建一个模型类代码,具体实现请看源代码:
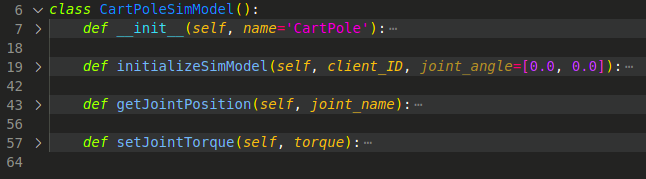
有了这些接口,我们就能远程读取模型的数据,控制仿真的开始、停止和复位等等,就有了实现多次重复学习的基础。在模型的控制上,我们只控制底部滑块的左右滑动,通过给滑块施加左右不同方向的力来实现。
2.2 基于Gym框架的实现
前面我们已经介绍了Gym的基本情况,在这里我们只需要基于上述获取机器人状态的函数接口,在Gym的几个函数里面分别调用接口来实现机器人状态的读取,仿真环境的启停等等。
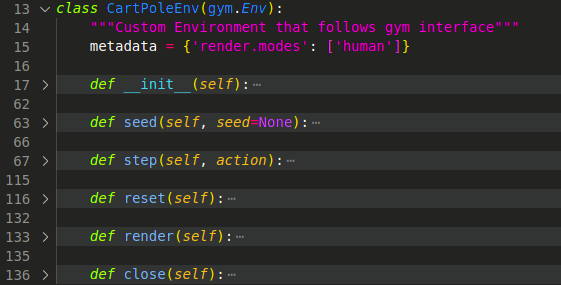
在这里,我们参考了Gym官方的模型,获取模型中滑块的位置、速度,旋转关节的角度和角速度四个数值作为机器人的状态,而动作空间我们设置了三个动作:不动、向左推滑块、向右推滑块。三个动作分别对应action_space里面的三个数值(0, 1, 2),三个动作分别给模型中的底部滑块施加0N,-1N,1N的力使其能够采取不动的动作。通过训练模型,我们获取得到在不同的状态下模型应该采取的动作,从而控制滑块实现杆的平衡。
2.3 算法的可视化
通常,强化学习的算法训练时间比较长,如果我们想要直观地的查看算法训练过程中的Loss以及Reward变化,有两种方式可以选择,使用tensorboard或使用visdom。在本文中,我们使用Visdom来实现,通过在代码中使用回调函数来获取在模型训练过程中的各种数据,然后发送到visdom的服务器端就可以实现数据的可视化了。这里我们使用stable-baselines3提供的回调函数接口,关于回调函数更多的细节,可以在这里找到:https://stable-baselines3.readthedocs.io/en/master/guide/callbacks.html。
本文中我们使用了两个回调函数,一个回调函数用于Visdom的数据可视化,另一个用于保存在训练过程中获得最佳reward的模型,这样在训练完成以后,我们就可以直接加载在训练过程中表现最佳的那个模型用于预测。
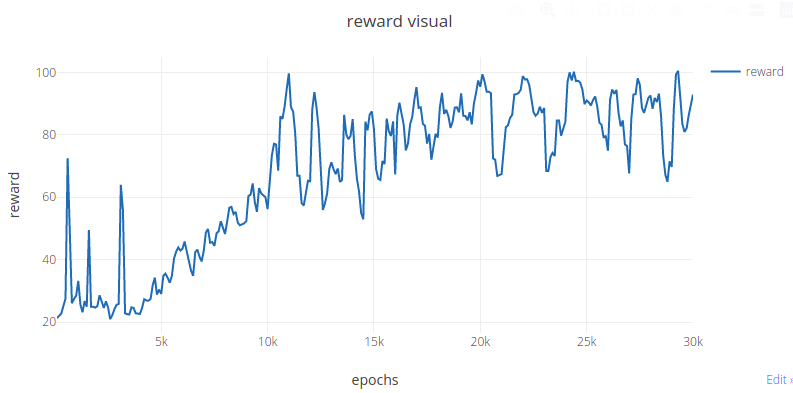
使用Visdom可视化Reward的结果,可以一边训练模型,一边查看Reward的变化:
三. 使用现有的强化学习算法
现有的强化学习算法已经有很多开源的代码实现,我们可以直接使用,只要搞明白了算法的接口,可以很容易跟我们自己的仿真环境做结合。在本文中,我们采用了德国航空航天中心机器人与一体化研究所(DLR-RM)开发的强化学习开源算法库Stable-baselines3(https://github.com/DLR-RM/stable-baselines3),该算法库是基于Pytorch开发的,在Gym的框架下实现了许多现有的强化学习算法模型,包括DQN、DDPG、SAC、A2C、TD3、HER等经典模型。在本文中,我们使用的是A2C(Advantage Actor-Critic)算法来训练我们的模型。
只需要上面几步,就可以直接使用现有的强化学习算法。当然,我们可以很容易的替换为其他模型,只需要在创建Model的时候使用不同的算法名字即可。除了使用现有的算法,用户也可以自定义算法,只需要按照一定的规则自定义模型即可,这里暂不讨论。
四. 模型的学习过程
通过前面三步,我们已经在CoppeliaSim中构建了cart-pole仿真模型,构建了基于Python的模型控制代码,构建了基于Gym和Stable-baselines3的强化学习环境,接下来我们可以直接开始训练模型了。
在训练刚开始的时候,模型的控制表现:
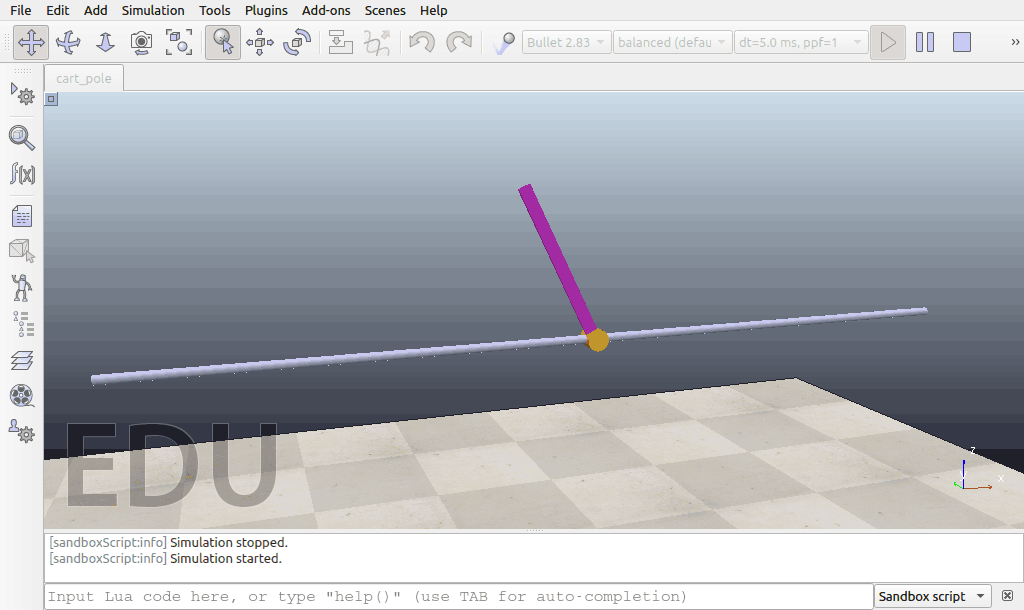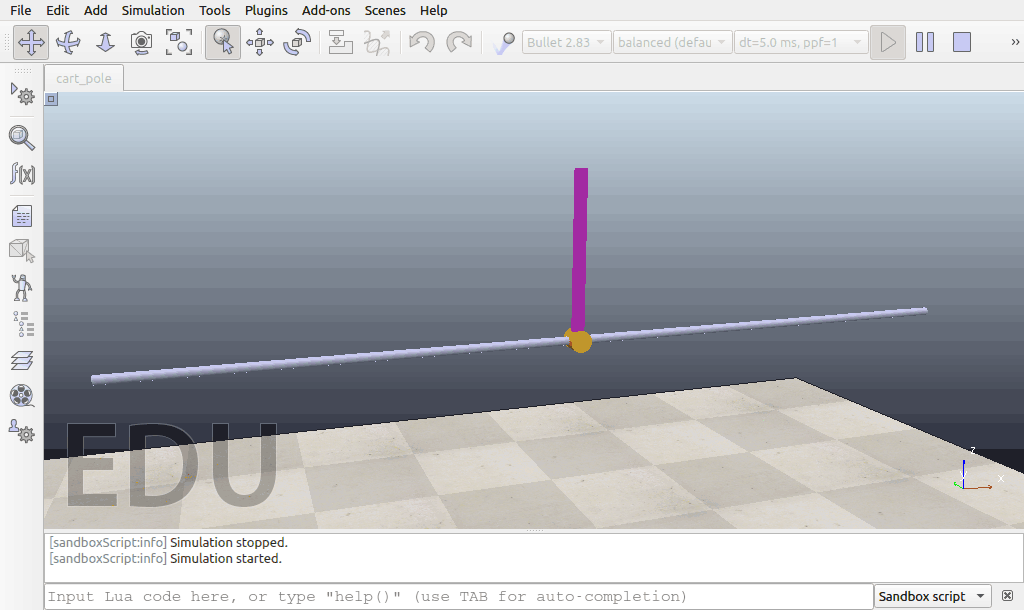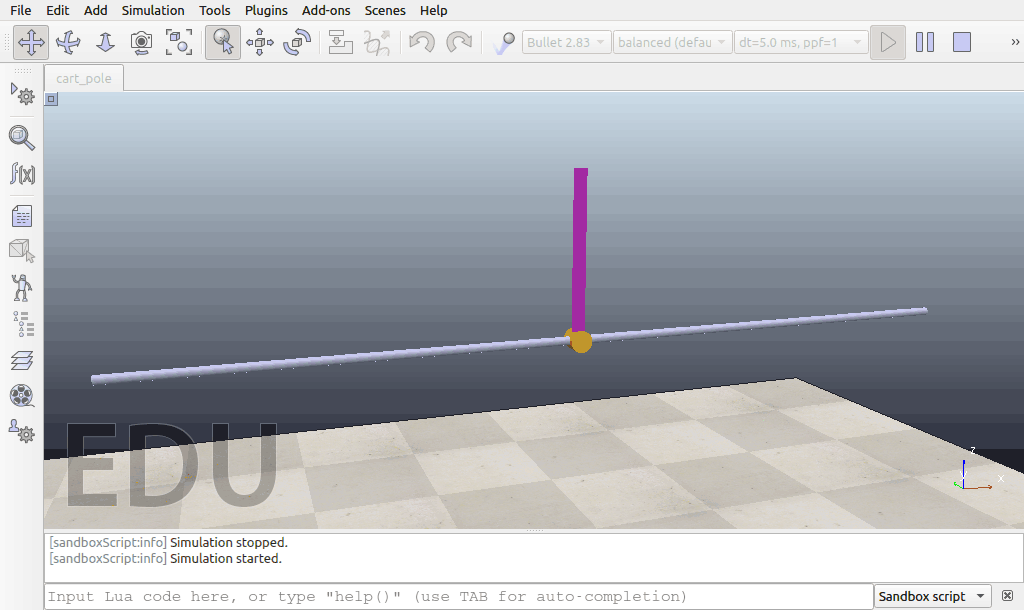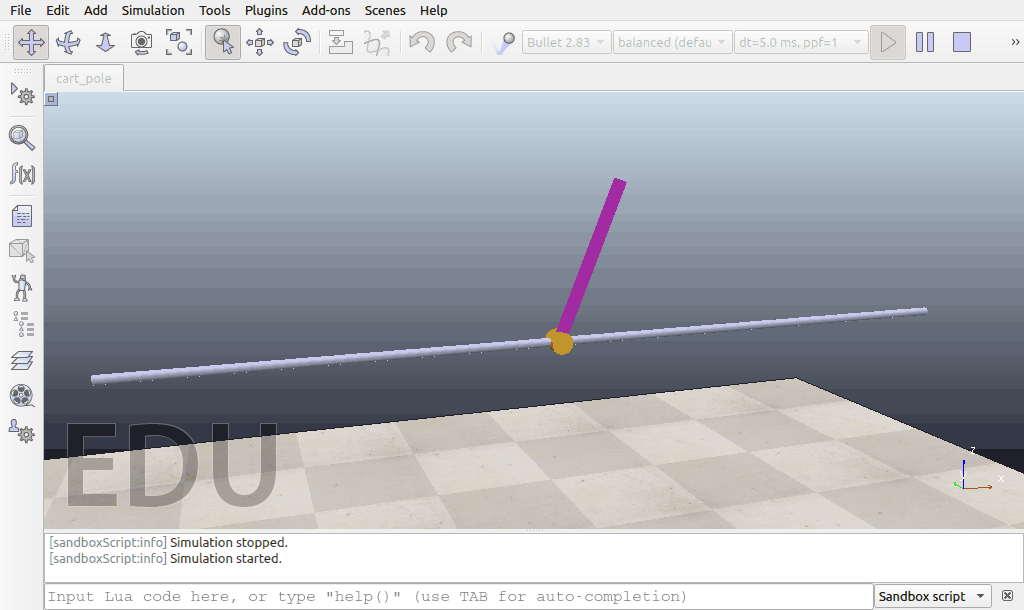
经过了5万个timesteps的训练以后:
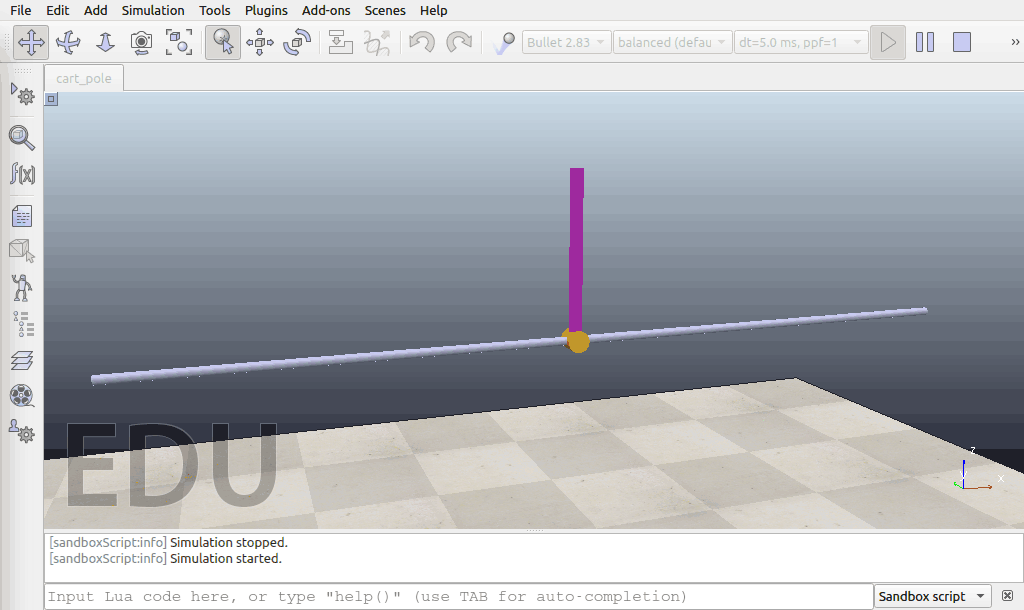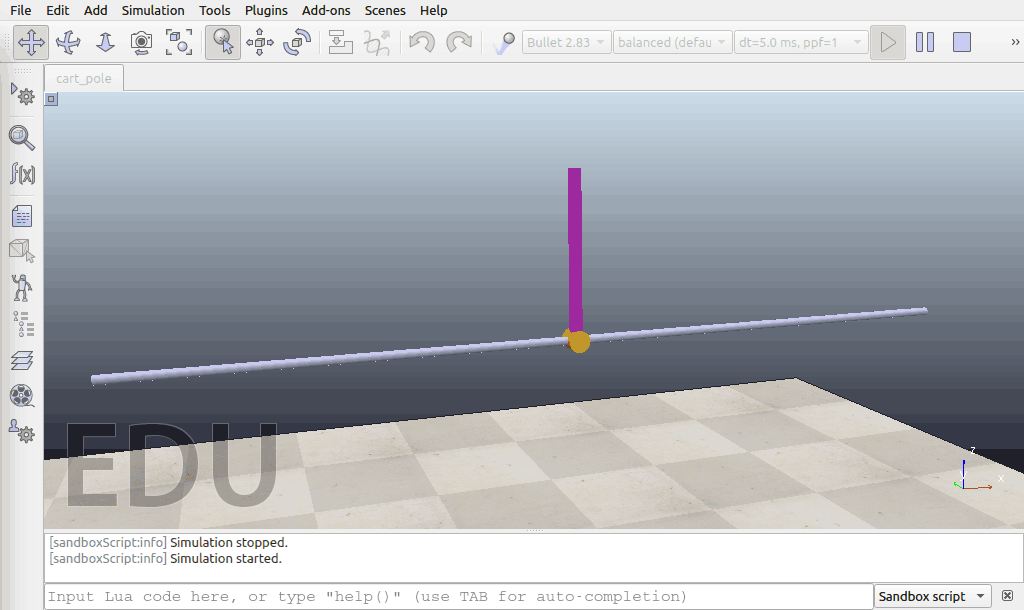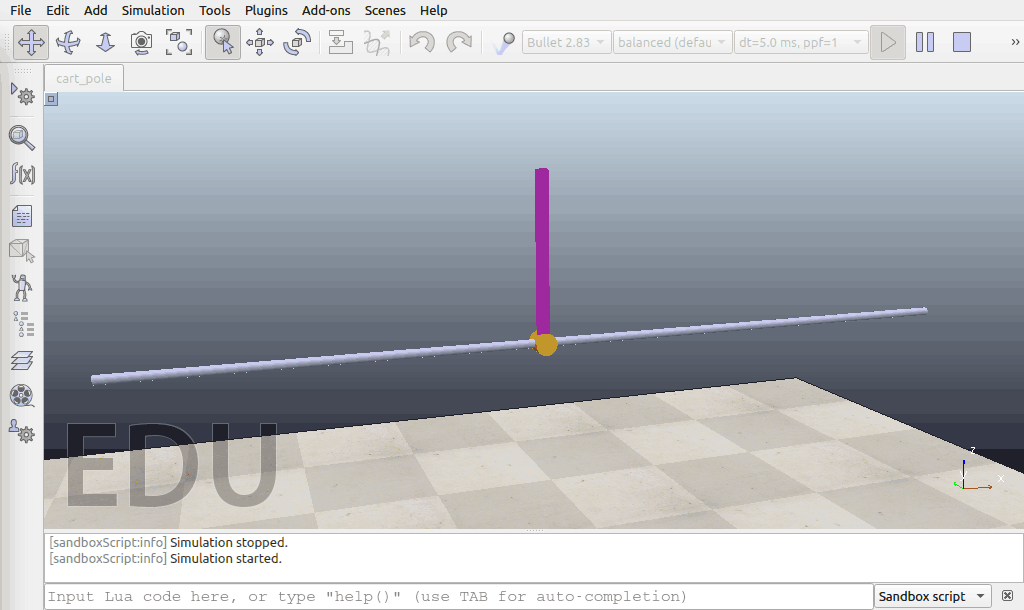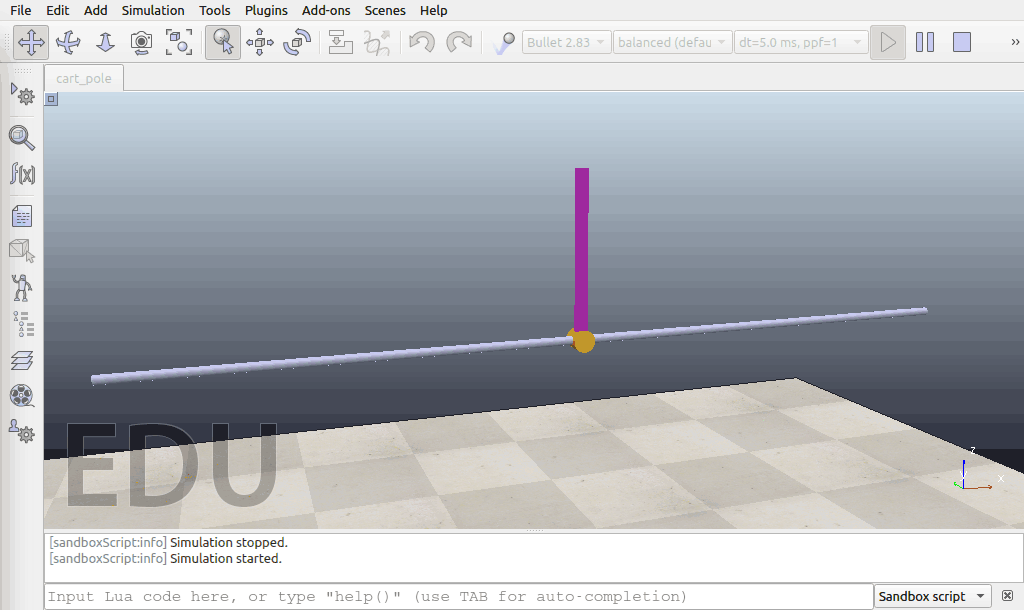
经过10万个timesteps的训练以后:
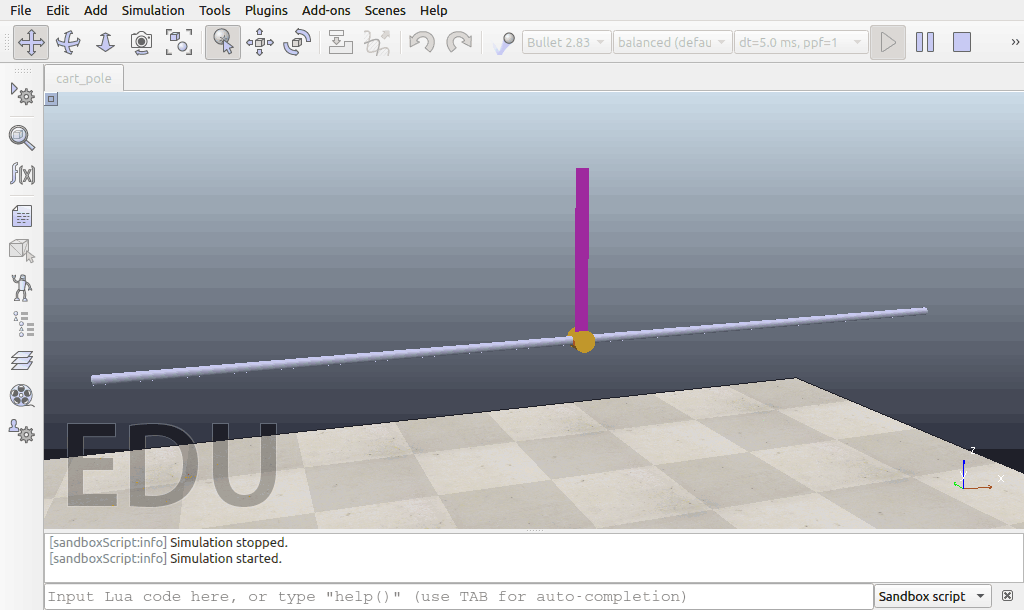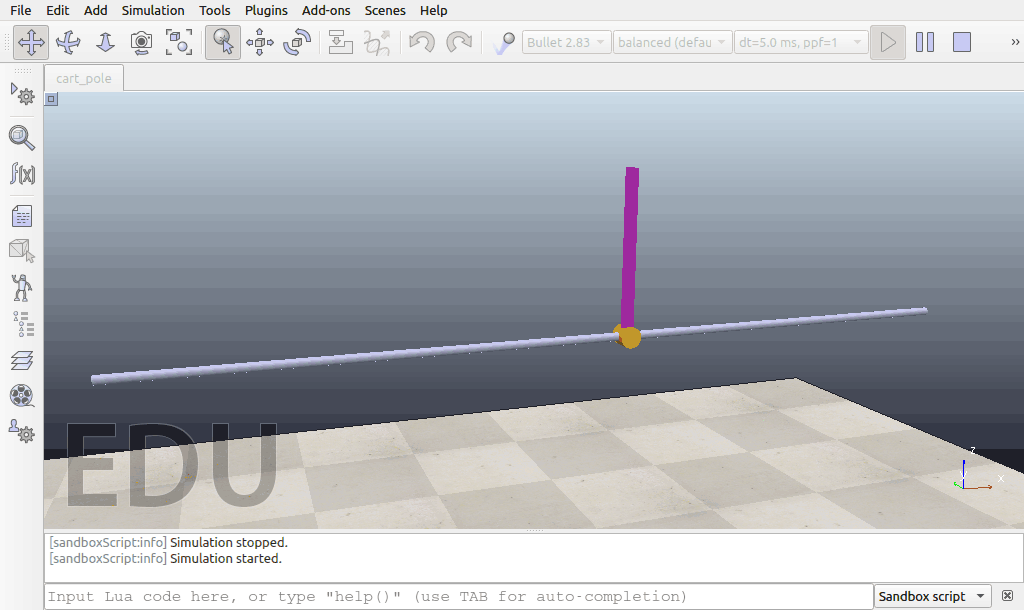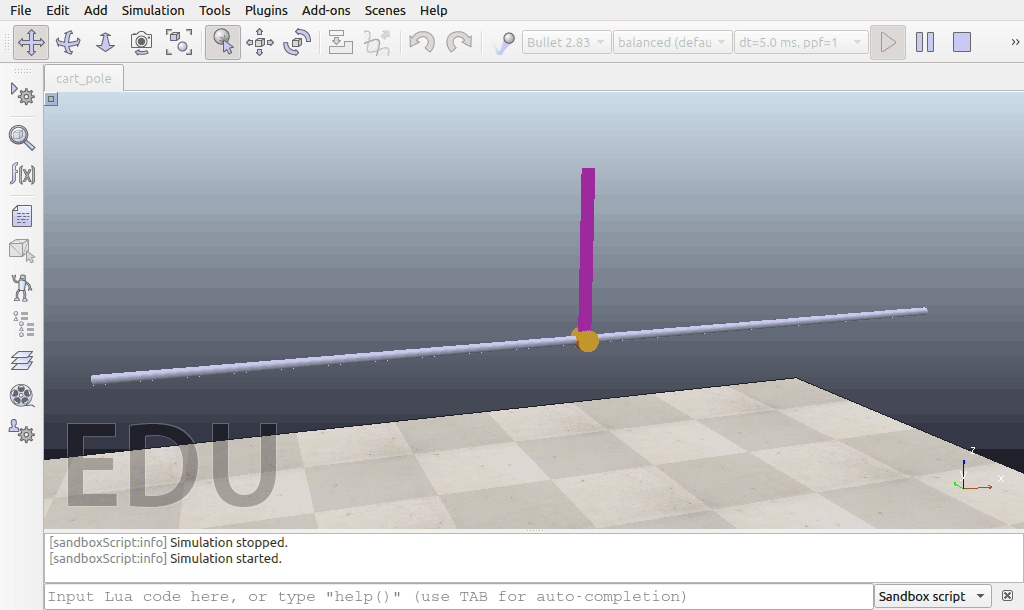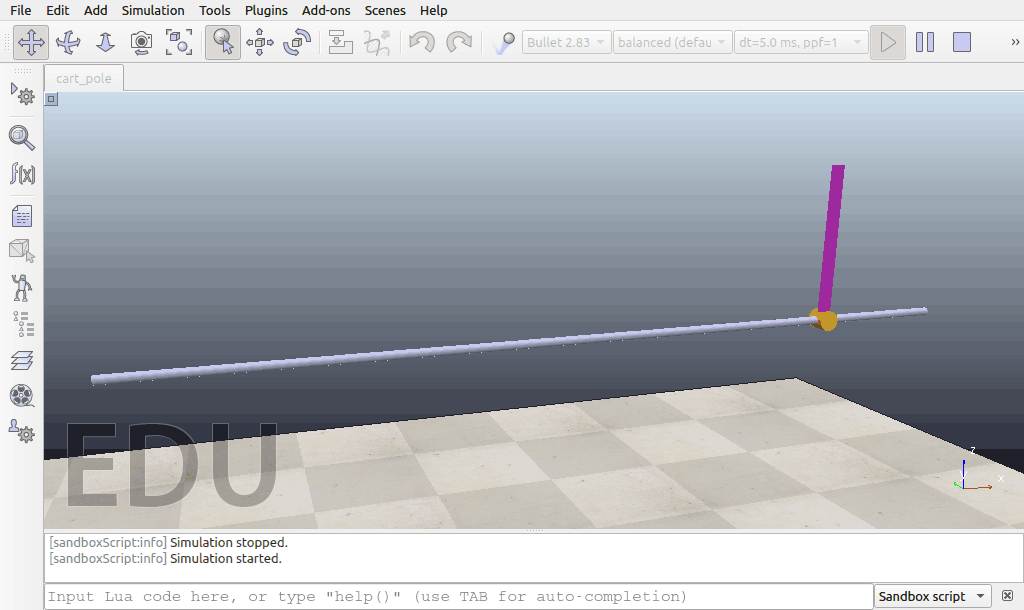
最终的效果与仿真环境中模型的配置,所使用的强化学习算法等都有关系,因此,如果尝试改进模型的参数以及其他的强化学习算法,或进行更长时间的模型训练,我们可能会得到更好的控制效果。
















 5511
5511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











