






引言:丰富、拟人的角色动画深受观众喜爱,但是传统的角色动画生成方法往往缺少考虑角色的物理属性,尤其是在物理环境中运动时与环境的交互情况。然而,生成能够与环境进行物理交互的多样化且真实的人体运动过程是一项极具挑战性的研究,目前尚没有成熟的解决方案。
【基本信息】
论文标题:PDP: Physics-Based Character Animation via Diffusion Policy
发表期刊:ACM Transactions on Graphics
发表时间:2024年12月3日
【访问链接】
论文链接:https://dl.acm.org/doi/10.1145/3680528.3687683
项目地址:https://stanford-tml.github.io/PDP.github.io/
代码链接:https://github.com/Stanford-TML/PDP
【科学问题】
开发一种能够生成多样化的人类运动、并能在环境中穿行和交互的框架,是角色动画中的一个关键目标,在机器人技术、外骨骼、虚拟 / 增强现实和视频游戏中都有广泛的应用潜力。
这些应用中的许多不仅需要多样化的人体运动姿势,还需要实现这些姿势所需的物理动作,包括与环境的交互过程,从而可以生成更加逼真的人物动作。
基于扩散的方法已经在机器人领域展示出了捕捉高度多样化和多模态技能的能力,但由于快速累积的复合误差,纯粹的训练扩散策略通常会导致高频欠驱动控制任务(如双足行走)的运动不稳定,使智能体偏离最佳训练轨迹。
因此,该论文引入了强化学习策略来优化这个过程,在获得最佳轨迹的同时还能在次优状态下提供纠正措施,使得学习到的策略有机会纠正由环境刺激、模型误差或模拟中的数值误差引起的错误,最终获得获得更好的表现效果。
【核心思路】
该论文提出了一种基于扩散策略和物理属性的角色动画生成策略(Physics-Based Character Animation via Diffusion Policy,PDP),并结合了强化学习(Reinforcement Learning, RL)和行为克隆(Behavior Cloning,BC),为基于物理属性的角色动画创建了一个强大的扩散模型,并在扰动恢复、通用运动跟踪和基于物理的文本到运动合成方面展示了该模型的测试结果。
论文的主要创新包括:
提出了一种鲁棒的行为克隆(BC)方法,该方法可拓展至大型运动数据集,无需复杂的训练架构,且能够轻松适应新技能;
分析了不同的数据增强采样策略对模型性能产生的影响;
引入了基于物理的模型,这类模型支持运动控制、运动追踪以及文本到运动的相关任务。
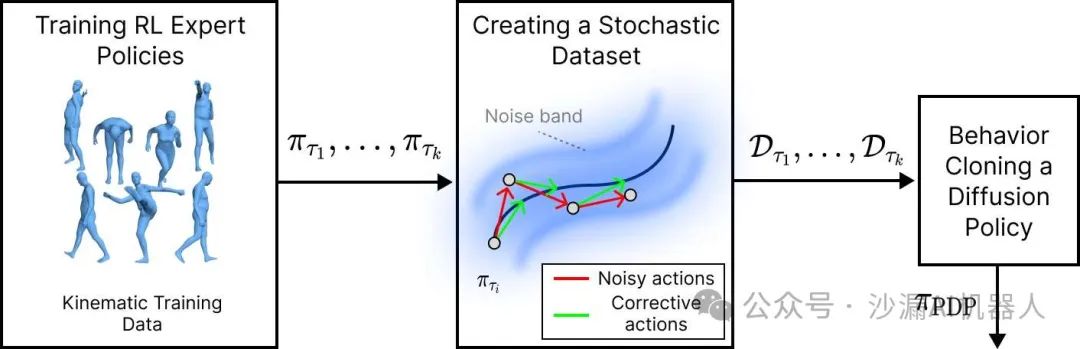
算法的主要步骤包括:
将收集到的人类运动数据集划分为多个任务,并为每个任务训练一个强化学习策略。
使用专家策略收集“有噪声状态下的干净动作”轨迹,其中有噪声的状态是通过执行添加了噪声的强化学习策略的动作获得的,而干净动作仅仅是没有噪声的强化学习策略的动作。
使用得到的数据集通过监督学习来训练扩散模型,生成最终结果。
【实验结果】
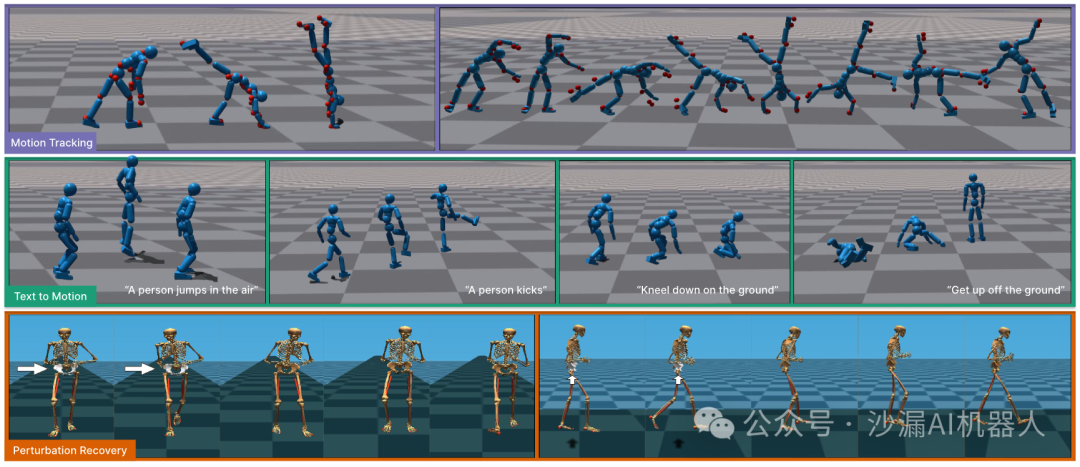
1. 双足步行的外部扰动自恢复
在双足步行过程中受到扰动时,PDP可以捕捉到扰动恢复策略的多模态性。因此,对于相同的扰动,角色可以通过多种方式来恢复平衡,从而提高对分布外扰动的鲁棒性。

2. 通用的动作跟踪
PDP能够跟踪广泛的动态运动,并成功跟踪了 AMASS 数据集中 98.9%的运动模式。

3. 通过文本生成动画
PDP能够从文本描述中生成多样化且逼真的人体运动,还可以将文本命令连接在一起,用来合成新颖的运动序列。

论文视频:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











