






引言:人形机器人由于具有类人形态的灵活性和适应性,有助于在各种环境和任务中协助人类完成工作。然而,人形机器人的研究常常因昂贵且脆弱的硬件而受到限制,迫切需要构建一套完整的能够模拟人形机器人各种运动和各种操作任务的仿真场景,这也将十分有助于大部分的人员参与到人形机器人的算法研究中。
【基本信息】
论文标题:HumanoidBench: Simulated Humanoid Benchmark for Whole-Body Locomotion and Manipulation
发表期刊:arXiv 预印版
发表时间:2024年6月18日
【访问链接】
论文链接:https://arxiv.org/abs/2403.10506
项目链接:https://humanoid-bench.github.io/
代码仓库:https://github.com/carlosferrazza/humanoid-bench
【研究背景】
现有的一些机器人仿真平台往往不能提供充足的人形机器人结构(如灵巧手)、任务场景以及基准的运动模式等,导致能进行的相关算法仿真不多。尤其是灵巧手的缺失会导致人形机器人无法完成大部分的操作任务,难以模拟真实世界的工作内容。
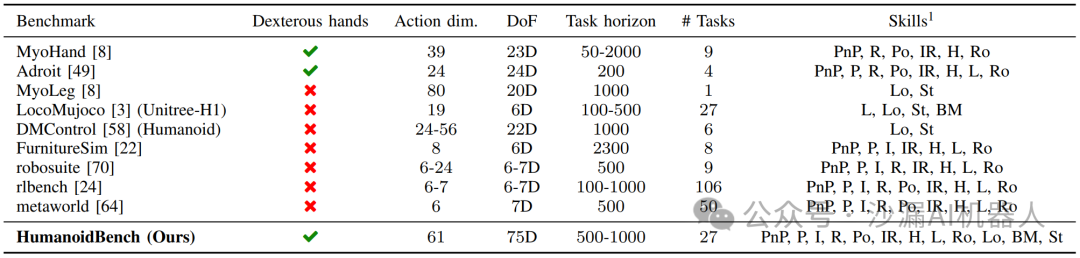
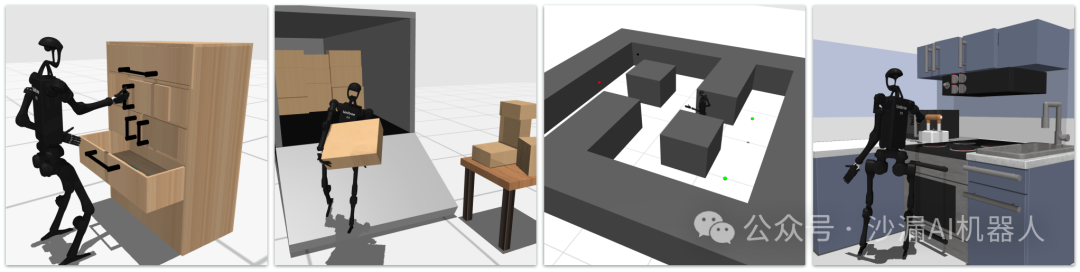
相比之下,该论文提出的HumanoidBench主要基于宇树公司的H1人形机器人开发,运行于Mujoco仿真平台上,可提供一双灵巧手机构及控制接口,也能提供27个不同的全身控制任务,包括15个全身操作任务和12个步行运动任务,例如整理家务、打包和搬运包裹、迷宫导航等等。
【科学问题】
现有的机器人仿真平台大多针对下肢运动设计,部分还能提供单臂操作的任务,且以末端夹爪为主,缺少仿人形的五指灵巧手的配置,而双臂操作任务在日常生活中极为常见,且需要灵活的手部来操作各种工具。

此外,针对一些复杂的操作过程,往往需要进行长时规划(Long term planning),将一系列的复杂操作结合到一起,并且考虑运动的平衡性、所操作物品的质量、环境的接触等复杂的约束,才能生成最终可以实现的复杂运动和操作过程。尤其是针对人形机器人来说,在进行复杂操作的同时还要保持整体的运动平衡十分具有挑战性。
因此,所构建的人形机器人仿真平台和基准测试需要包含足够数量的日常操作任务,且能够提供一些基本的运动控制策略来构建人形机器人多任务操作的基准测试集,从而让更多的研究者可以在该平台上研究算法并进行对比测试。
【核心思路】
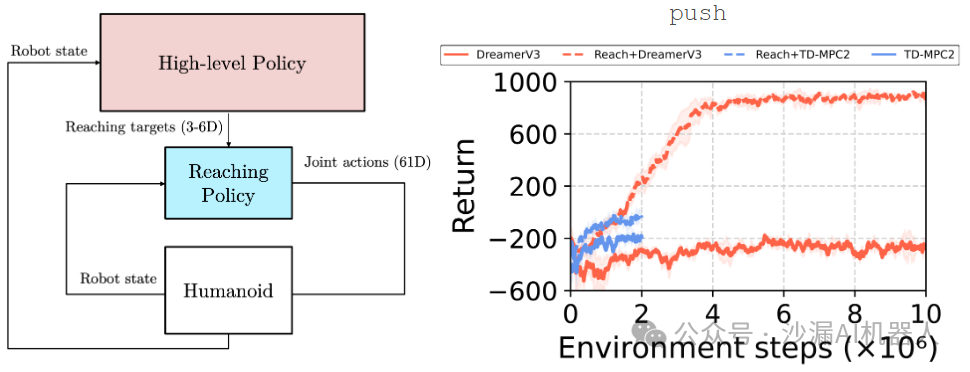
该项目构建了一个丰富的人形机器人仿真任务基准测试集,包含27个人形机器人的操作和运动任务,并且引入了层级强化学习(Hierarchical Reinforcement Learning, HRL)算法来构建长时规划任务,生成人形机器人多自由度关节在高维运动空间中的协同运动控制策略。
其中,所构建的机器人仿真模型主要依靠宇树科技公司的人形机器人H1和G1,每个模型都有一双五指灵巧手可用于操作任务的执行。除了基本的姿态和关节角度传感器,在机器人的头部还添加了双目视觉传感器,在手臂、手指及足端添加了力传感用于触觉感知,可提供三维接触力的信息反馈。
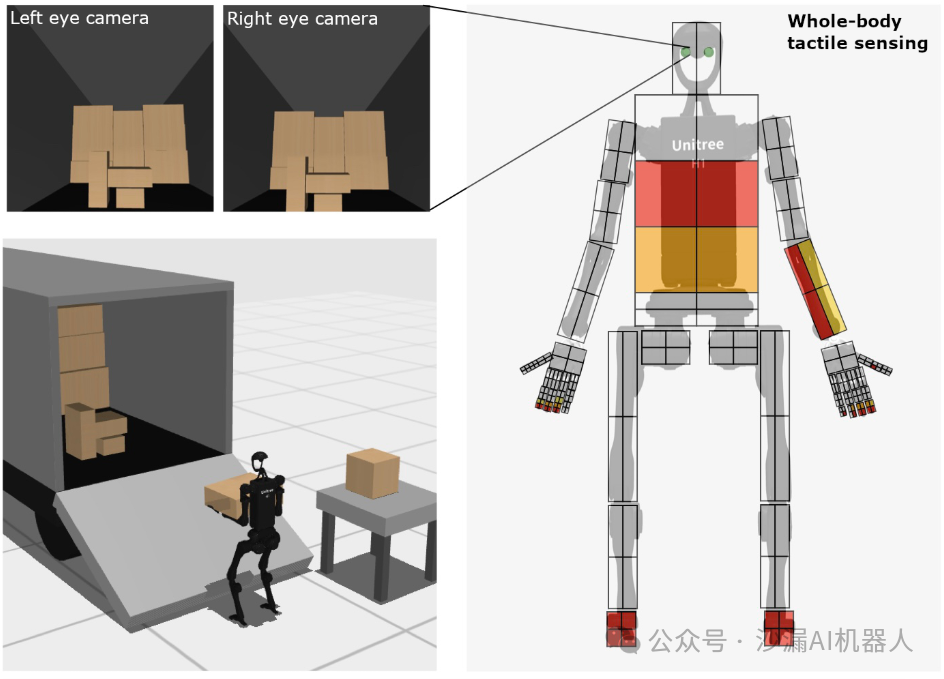
手掌和手指上的力传感演示:
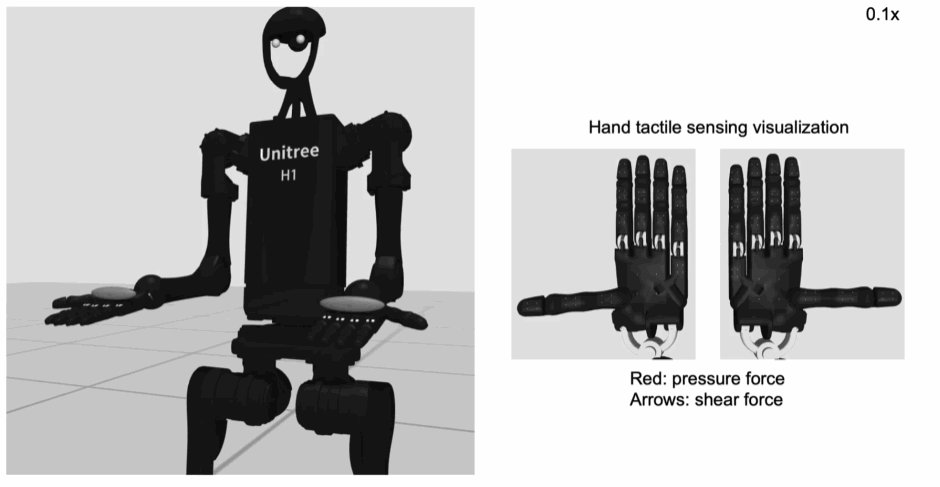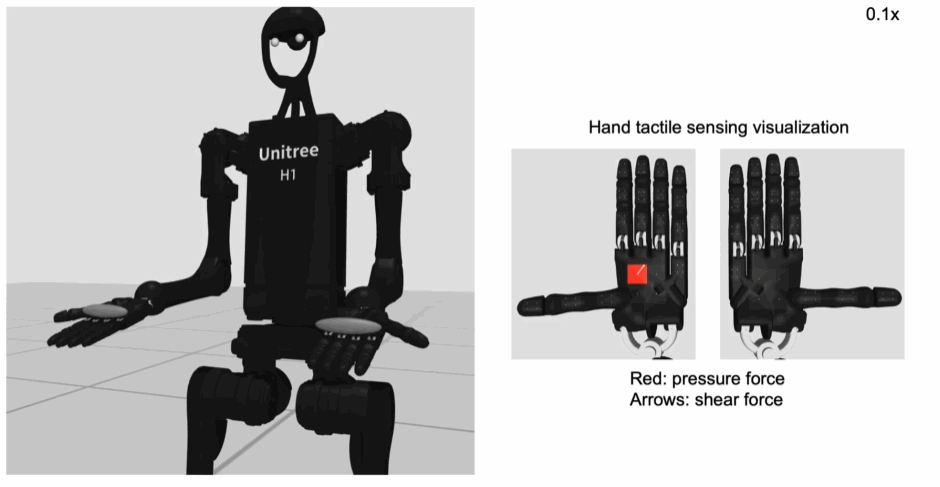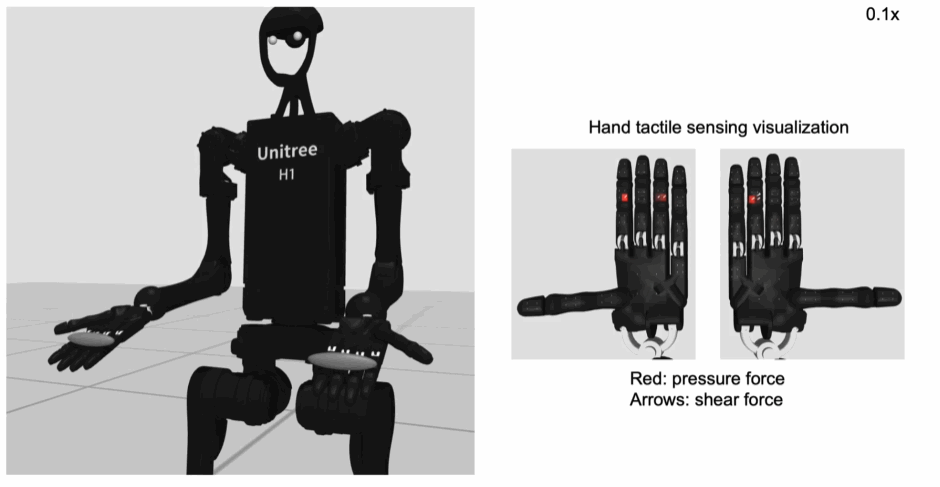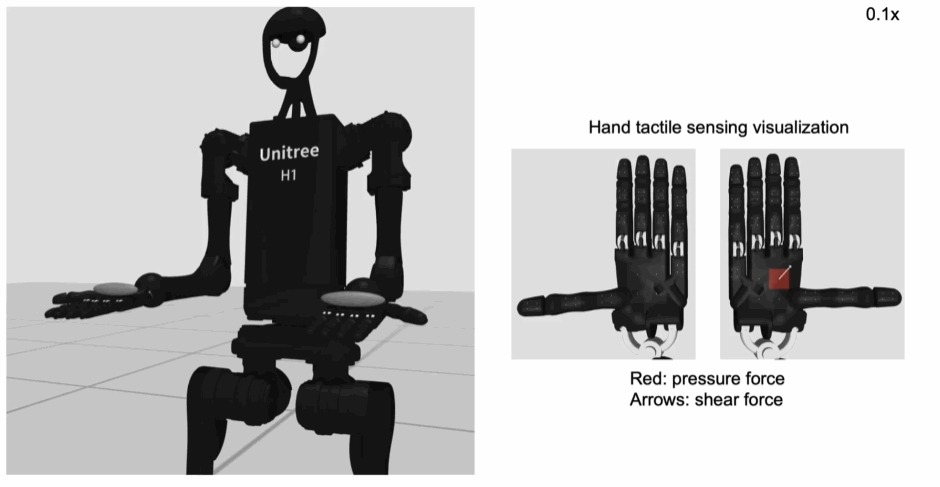
机器人模型支持位置控制(关节角度)和力矩控制两种控制模式,但是位置控制模式更加稳定。总共能够控制的关节数量为61个,控制频率位50Hz。
此外,对于许多需要长期规划的任务来说,比如平衡、行走、伸手拿取等,该项目构建了一种层级强化学习的算法框架,可以根据任务需求生成高级规划策略和低级控制策略,测试了包括PPO、SAC等在内的前沿强化学习算法,得到了良好的训练结果。
【实验结果】
该项目提供了多种基准测试任务用于展现所构建的机器人仿真模型的潜力,也展示了基于所构建的层级强化学习算法所能实现的人形机器人的复杂任务场景控制效果。
步行任务:包括行走、跑步、爬行、复杂地形双足步行等。
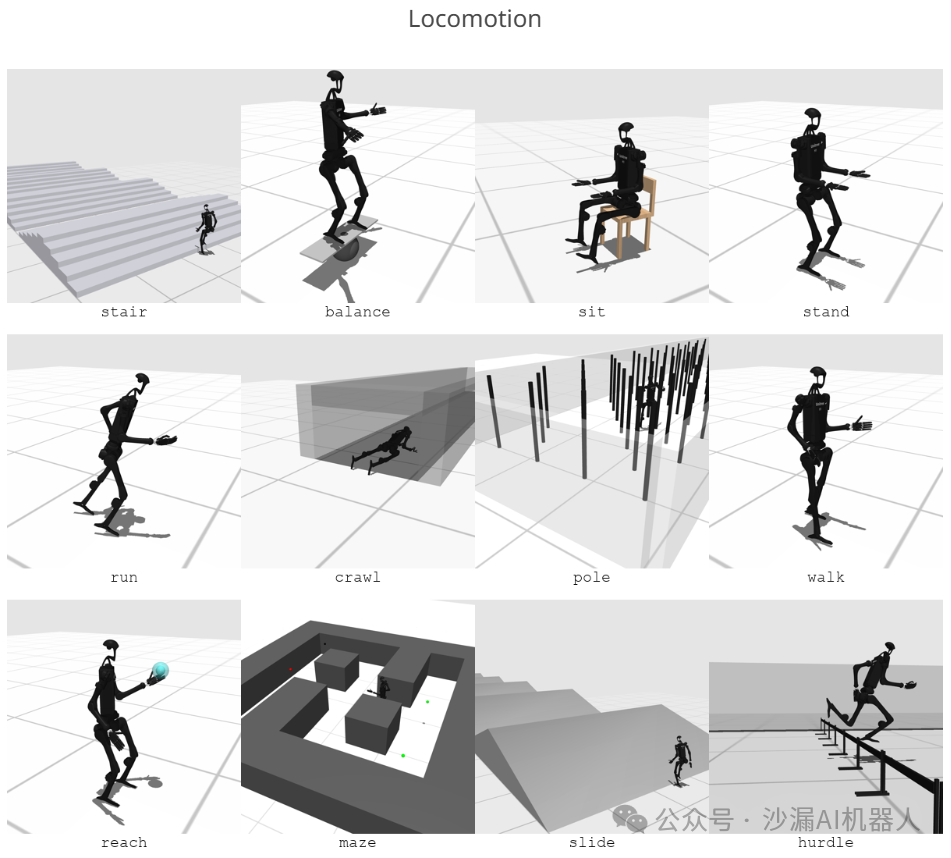
静态操作任务:包括取放物品、开关抽屉等。

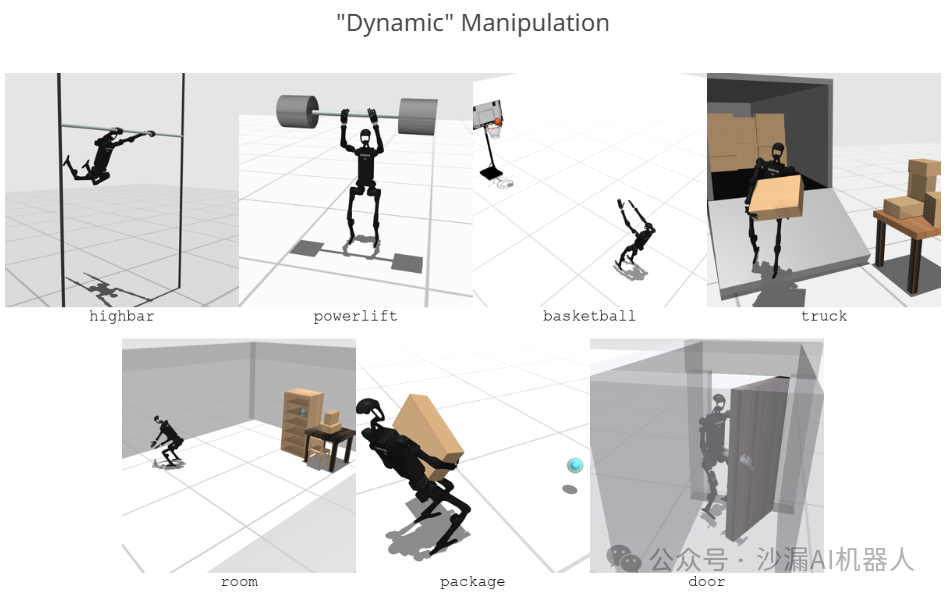
动态操作任务:包括举重、投篮、物品搬运、开关门等。
层级强化学习算法的实现效果:人形机器人的双手跟踪随机变化的目标位置,同时要配合双腿生成合理的运动策略来保持全身的稳定。

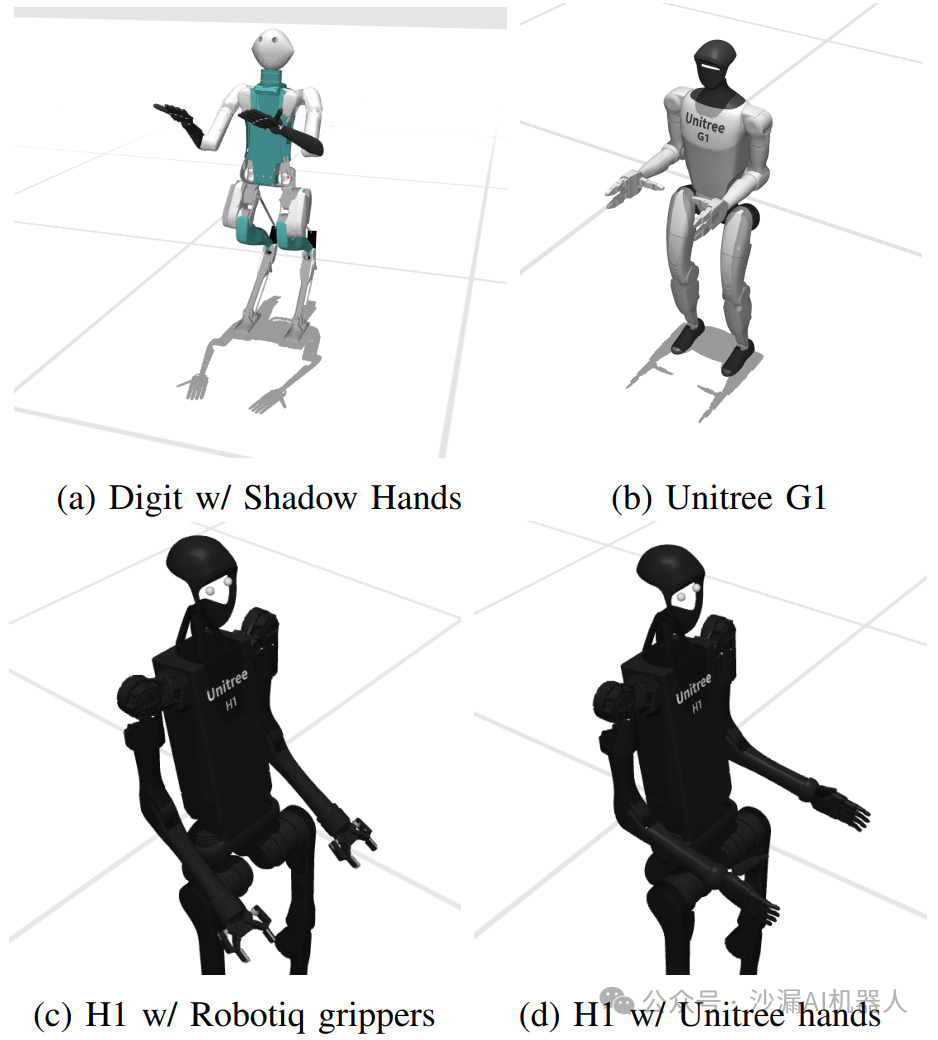
当然,该仿真平台也支持部分其他人形机器人的仿真和基准测试。
综上,该项目构建的人形机器人仿真平台及其基准测试结果可以给相关从业者提供基础的人形机器人运动控制框架,作者在Github上开源了所有的模型和算法。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











