






 本文介绍了如何使用PyTorch构建一个N-gram语言模型,通过词向量表示进行文本分析,并使用PCA进行降维,展示了训练过程和Word2Vec模型的比较,以可视化的方式呈现了单词之间的相似性。
本文介绍了如何使用PyTorch构建一个N-gram语言模型,通过词向量表示进行文本分析,并使用PCA进行降维,展示了训练过程和Word2Vec模型的比较,以可视化的方式呈现了单词之间的相似性。
# 加载必要的程序包
# PyTorch的程序包
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 数值运算和绘图的程序包
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
# 加载机器学习的软件包,主要为了词向量的二维可视化
from sklearn.decomposition import PCA
#加载‘结巴’中文分词软件包
import jieba
#加载正则表达式处理的包
import re
我这里使用的训练语料是一段《三体》的文本,预览内容如下:

- 分词
# 分词
temp = jieba.lcut(text)
words = []
for i in temp:
#过滤掉所有的标点符号
i = re.sub("[\s+\.\!\/_,$%^*(+\"\'“”《》?“]+|[+——!,。?、~@#¥%……&*():]+", "", i)
if len(i) > 0:
words.append(i)
print(len(words))
words
输出如下:

# 构建三元组列表. 每一个元素为: ([ i-2位置的词, i-1位置的词 ], 下一个词)
# 我们选择的Ngram中的N,即窗口大小为2
trigrams = [([words[i], words[i+1]], words[i+2]) for i in range(len(words)-2)]
# 打印出前三个元素看看
trigrams[:3]
输出如下:
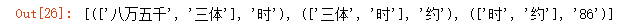
# 得到词汇表
vocab = set(words) # 词表大小为1999
# 两个字典,一个根据单词索引其编号,一个根据编号索引单词
#word_to_idx中的值包含两部分,一部分为id,另一部分为单词出现的次数
#word_to_idx中的每一个元素形如:{w:[id, count]},其中w为一个词,id为该词的编号,count为该单词在words全文中出现的次数
word_to_idx = {}
idx_to_word = {}
ids = 0
#对全文循环,构建这两个字典
for w in words:
cnt = word_to_idx.get(w, [ids, 0])
if cnt[1] == 0:
ids += 1
cnt[1] += 1
word_to_idx[w] = cnt
idx_to_word[ids] = w
构造模型并训练
1). NPLM的实现
我们构造了一个三层的网络:
1、输入层:embedding层,这一层的作用是:先将输入单词的编号映射为一个one hot编码的向量,形如:001000,维度为单词表大小。 然后,embedding会通过一个线性的神经网络层映射到这个词的向量表示,输出为embedding_dim
2、线性层,从context_size*embedding_dim维度到128维度,然后经过非线性ReLU函数
3、线性层:从128维度到单词表大小维度,然后log softmax函数,给出预测每个单词的概率
class NGram(nn.Module):
def __init__(self, vocab_size, embedding_dim, context_size):
super(NGram, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim) #嵌入层
self.linear1 = nn.Linear(context_size * embedding_dim, 128) #线性层
self.linear2 = nn.Linear(128, vocab_size) #线性层
def forward(self, inputs):
#嵌入运算,嵌入运算在内部分为两步:将输入的单词编码映射为one hot向量表示,然后经过一个线性层得到单词的词向量
#inputs的尺寸为:1*context_size
embeds = self.embeddings(inputs)
#embeds的尺寸为: context_size*embedding_dim
embeds = embeds.view(1, -1)
#此时embeds的尺寸为:(1, context_size*embedding_dim)
# 线性层加ReLU
out = self.linear1(embeds)
out = F.relu(out)
#此时out的尺寸为1*128
# 线性层加Softmax
out = self.linear2(out)
#此时out的尺寸为:1*vocab_size
log_probs = F.log_softmax(out, dim = 1)
return log_probs
def extract(self, inputs):
embeds = self.embeddings(inputs)
return embeds
NPLM的训练
losses = [] #纪录每一步的损失函数
criterion = nn.NLLLoss() #运用负对数似然函数作为目标函数(常用于多分类问题的目标函数)
model = NGram(len(vocab), 10, 2) #定义NGram模型,向量嵌入维数为10维,N(窗口大小)为2
optimizer = optim.SGD(model.parameters(), lr=0.001) #使用随机梯度下降算法作为优化器
#循环100个周期
for epoch in range(20):
total_loss = torch.Tensor([0])
for context, target in trigrams:
# 准备好输入模型的数据,将词汇映射为编码
context_idxs = [word_to_idx[w][0] for w in context]
context_var = torch.tensor(context_idxs, dtype = torch.long)
# 清空梯度:注意PyTorch会在调用backward的时候自动积累梯度信息,故而每隔周期要清空梯度信息一次。
optimizer.zero_grad()
# 用神经网络做计算,计算得到输出的每个单词的可能概率对数值
log_probs = model(context_var)
loss = criterion(log_probs, torch.tensor([word_to_idx[target][0]], dtype = torch.long))
# 梯度反传
loss.backward()
# 对网络进行优化
optimizer.step()
# 累加损失函数值
total_loss += loss.data
losses.append(total_loss)
print('第{}轮,损失函数为:{:.2f}'.format(epoch, total_loss.numpy()[0]))
输出如下:

注:上面损失看似很大,实际上是因为我没有把它加和之后求平均,它是那七千多个训练样本累加之后得到的损失值。
结果展示
# 从训练好的模型中提取每个单词的向量
vec = model.extract(torch.tensor([v[0] for v in word_to_idx.values()], dtype = torch.long))
vec = vec.data.numpy()
# 利用PCA算法进行降维
X_reduced = PCA(n_components=2).fit_transform(vec)
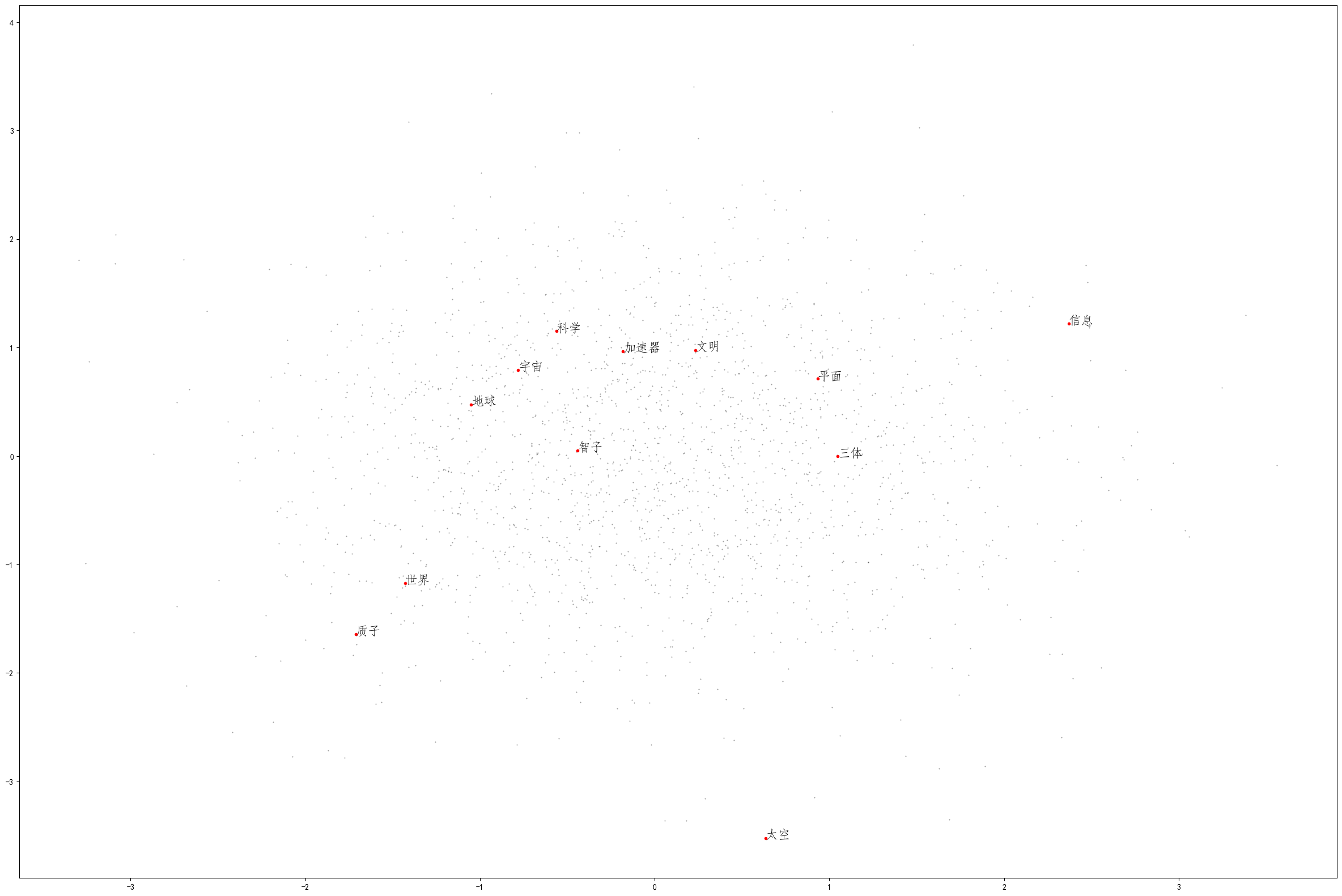
# 绘制所有单词向量的二维空间投影
fig = plt.figure(figsize = (30, 20))
ax = fig.gca()
ax.set_facecolor('white')
ax.plot(X_reduced[:, 0], X_reduced[:, 1], '.', markersize = 1, alpha = 0.4, color = 'black')
# 绘制几个特殊单词的向量
words = ['智子', '地球', '三体', '质子', '科学', '世界', '文明', '太空', '加速器', '平面', '宇宙', '信息']
# 设置中文字体,否则无法在图形上显示中文
zhfont1 = matplotlib.font_manager.FontProperties(fname='./华文仿宋.ttf', size=16)
# plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus']=False
for w in words:
if w in word_to_idx:
ind = word_to_idx[w][0]
xy = X_reduced[ind]
plt.plot(xy[0], xy[1], '.', alpha =1, color = 'red')
plt.text(xy[0], xy[1], w, fontproperties = zhfont1, alpha = 1, color = 'black')
输出如下:
# 定义计算cosine相似度的函数
def cos_similarity(vec1, vec2):
norm1 = np.linalg.norm(vec1)
norm2 = np.linalg.norm(vec2)
norm = norm1 * norm2
dot = np.dot(vec1, vec2)
result = dot / norm if norm > 0 else 0
return result
# 在所有的词向量中寻找到与目标词(word)相近的向量,并按相似度进行排列
def find_most_similar(word, vectors, word_idx):
vector = vectors[word_to_idx[word][0]]
simi = [[cos_similarity(vector, vectors[num]), key] for num, key in enumerate(word_idx.keys())]
sort = sorted(simi, reverse=True)
words = [i[1] for i in sort]
return words
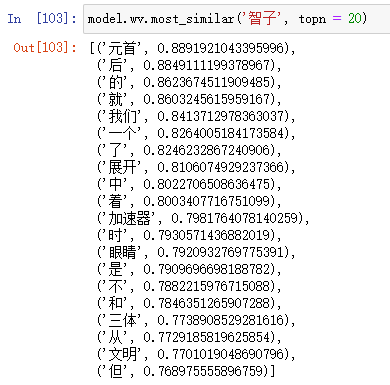
# 与智子靠近的词汇
find_most_similar('智子', vec, word_to_idx)
输出如下:

Word2Vec的应用
# 加载Word2Vec的软件包
import gensim
from gensim.models import Word2Vec
from gensim.models.keyedvectors import KeyedVectors
from gensim.models.word2vec import LineSentence
# 读入文件、分词,形成一句一句的语料
# 注意跟前面处理不一样的地方在于,我们一行一行地读入文件,从而自然利用行将文章分开成“句子”
f = open("3body.txt", 'r', encoding='utf-8')
lines = []
for line in f:
temp = jieba.lcut(line)
words = []
for i in temp:
#过滤掉所有的标点符号
i = re.sub("[\s+\.\!\/_,$%^*(+\"\'“”《》]+|[+——!,。?、~@#¥%……&*():;‘]+", "", i)
if len(i) > 0:
words.append(i)
if len(words) > 0:
lines.append(words)
# 调用Word2Vec的算法进行训练。
# 参数分别为:size: 嵌入后的词向量维度;window: 上下文的宽度,min_count为考虑计算的单词的最低词频阈值
model = Word2Vec(lines, vector_size = 20, window = 2 , min_count = 0)
Word2Vec对象的常用方法:
-
找出最接近某个词的前20个词:
-
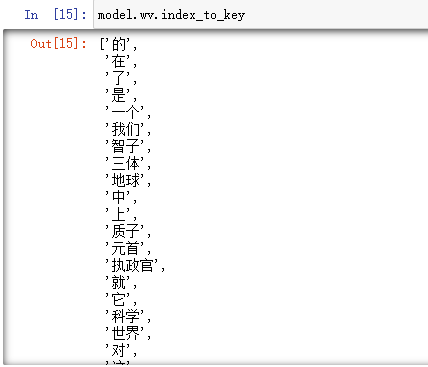
按照顺序去看对象的每一个字符:
-
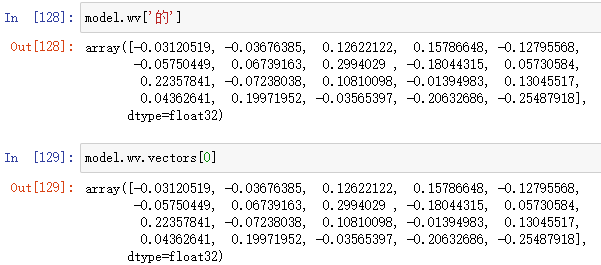
两种方法去看对应字符的向量表示:
- 按照字符获取向量
- 按照索引顺序获取向量
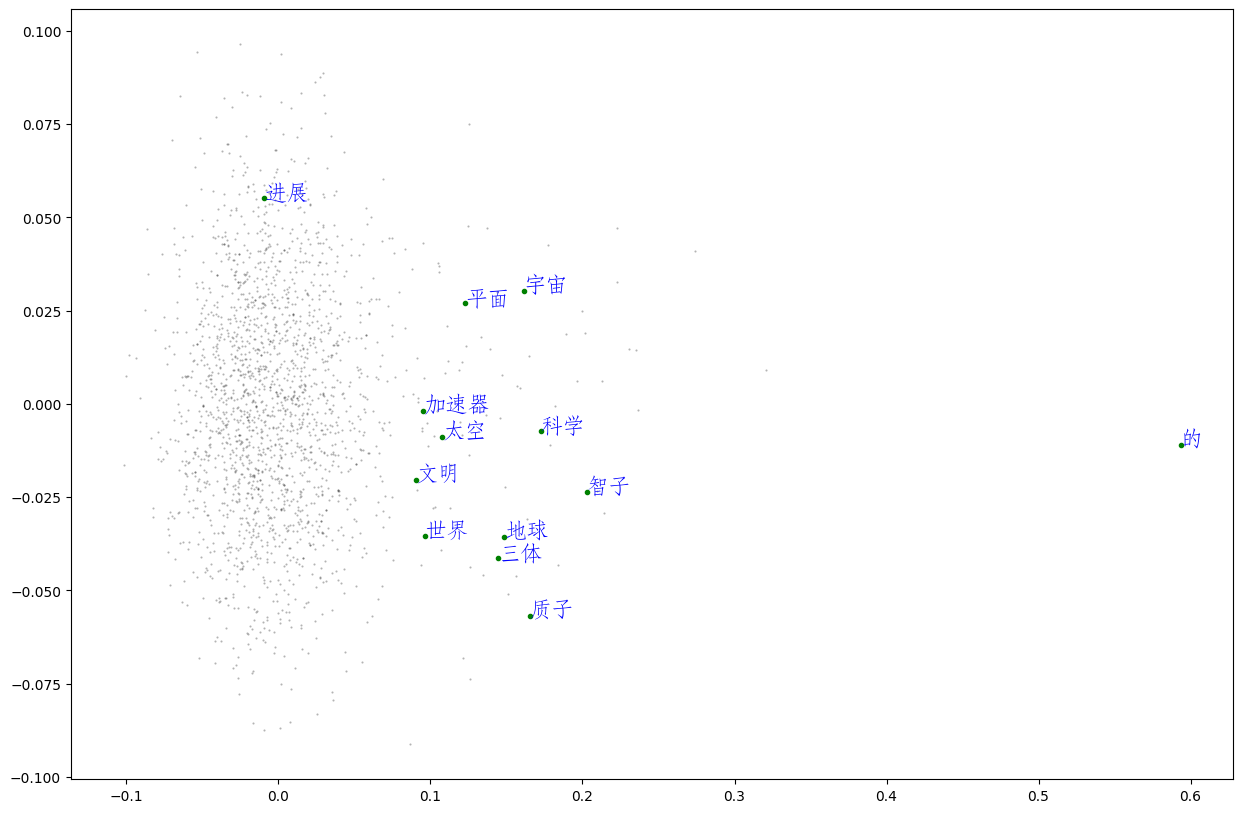
# 将词向量投影到二维空间
word2ind = {}
rawWordVec = model.wv.vectors
for i, w in enumerate(model.wv.index_to_key):
word2ind[w] = i
X_reduced = PCA(n_components=2).fit_transform(rawWordVec)
# 绘制星空图
# 绘制所有单词向量的二维空间投影
fig = plt.figure(figsize = (15, 10))
ax = fig.gca()
ax.set_facecolor('white')
ax.plot(X_reduced[:, 0], X_reduced[:, 1], '.', markersize = 1, alpha = 0.3, color = 'black')
# 绘制几个特殊单词的向量
words = ['智子', '地球', '三体', '质子', '科学', '世界', '文明', '太空', '加速器', '平面', '宇宙', '进展','的']
# 设置中文字体,否则无法在图形上显示中文
zhfont1 = matplotlib.font_manager.FontProperties(fname='./华文仿宋.ttf', size=16)
for w in words:
if w in word2ind:
ind = word2ind[w]
xy = X_reduced[ind]
plt.plot(xy[0], xy[1], '.', alpha =1, color = 'green')
plt.text(xy[0], xy[1], w, fontproperties = zhfont1, alpha = 1, color = 'blue')
输出如下:

















 9387
9387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









