






数据在github中有
截取一段时间的数据,将cnt随时间变化关系绘制成图。
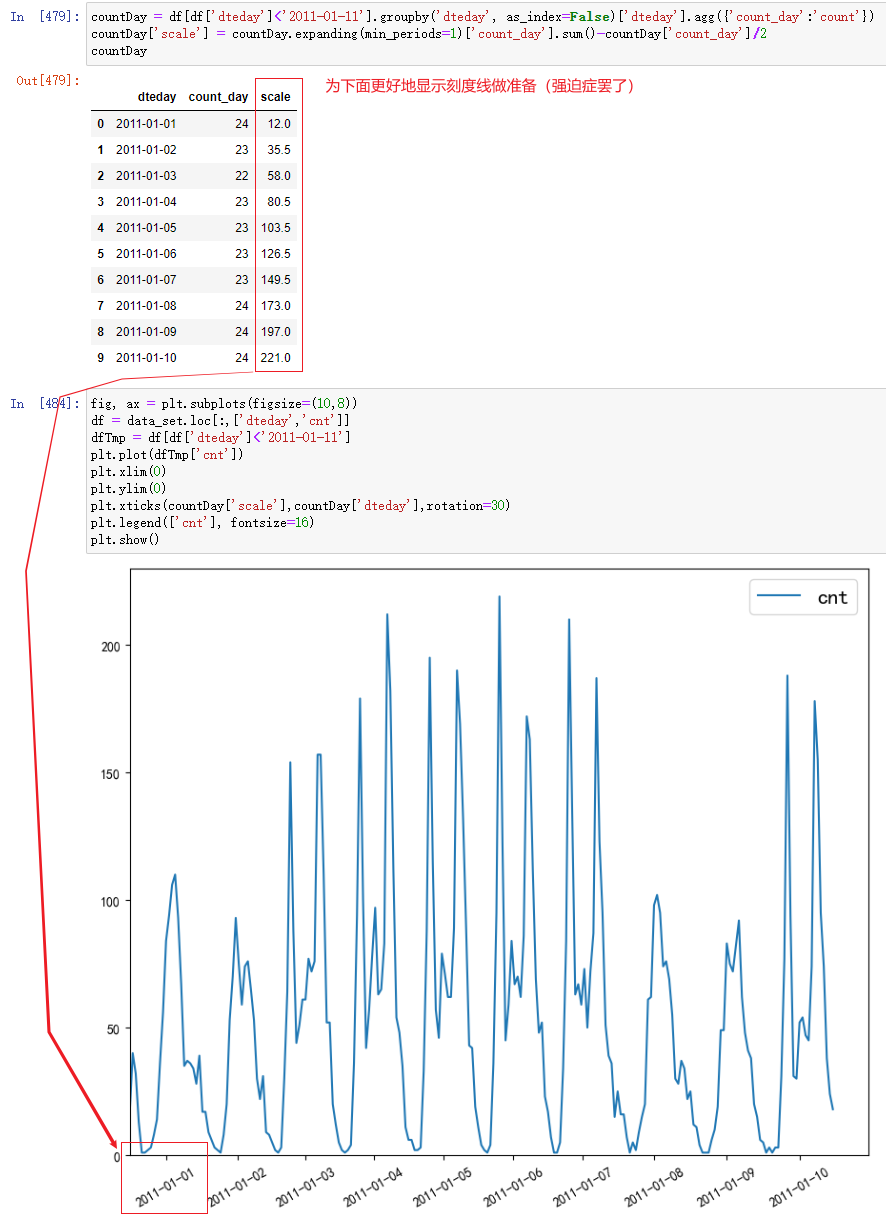
(2011年1月3日至7日、1月10日为工作日,不难看出,工作日的单车使用量高峰远高于周末的)
单车预测器 1.0
这里将构建一个单车预测器,它是一个单一隐含单元的神经网络。我们将训练它拟合共享单车的波动曲线。不过,在设计单车预测器之前,我们有必要了解一下人工神经网络的概念和工作原理。
人工神经网络简介
对于一个单神经元模型 y = w ′ σ ( w x + b ) y=w'\sigma(wx+b) y=w′σ(wx+b)当改变 w’、w、b时,函数的图像也会发生相应的改变。
- w对sigmoid函数曲线的影响
def f(w1, w, b, x):
return w1/(1+np.exp(-w*x-b))
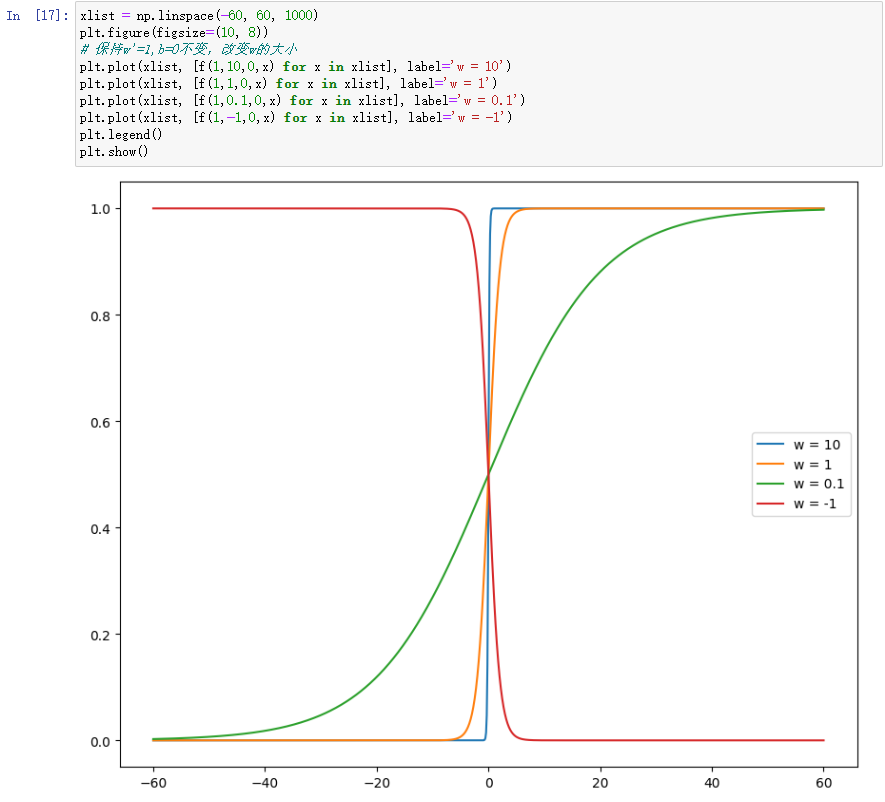
由此可见,当w>0的时候,它的大小控制着函数的弯曲程度,w越大,它在0点附近就越弯曲,因此从x=0的突变也就越剧烈;当w<0的时候,曲线发生了左右翻转,它会从1突变到0。
2. b对sigmoid函数曲线的影响
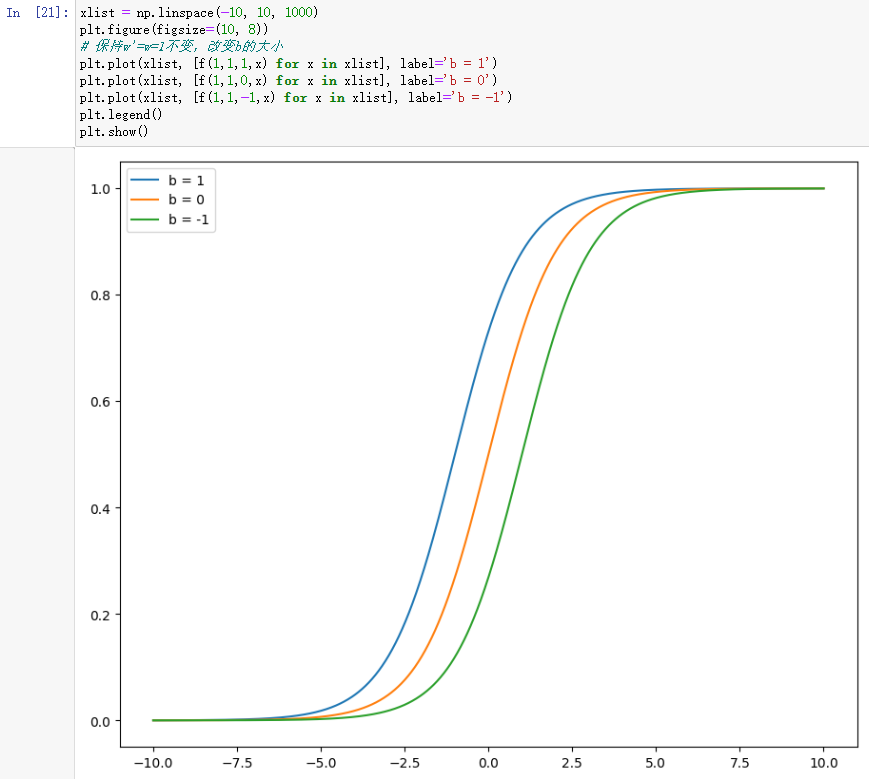
可以看到,b控制着sigmoid函数曲线的水平位置。b>0,函数图像往左平移,反之往右平移。
3. w’对sigmoid函数曲线的影响
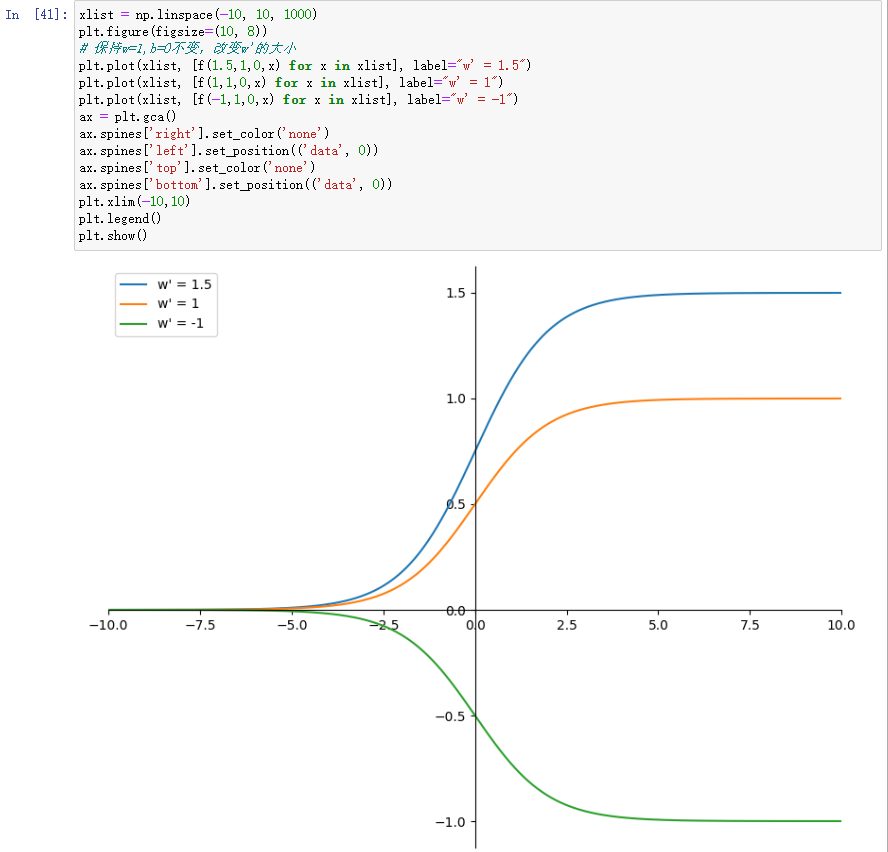
当w’>0的时候,w’控制曲线的高矮;当w’<0的时候,曲线的方向发生上下颠倒。
可见,通过控制w、w’ 和 b 这三个参数,我们可以任意调节从输入x到输出y的函数形状。但是,无论如何调节,这条曲线永远都是S型(包括倒S型)。要想得到更加复杂的函数图像,我们需要引入更多的神经元。
两个隐含神经元
这个网络仍然是一个将x映射到y的函数,函数方程为:
y
=
w
1
′
σ
(
w
1
x
+
b
1
)
+
w
2
′
σ
(
w
2
x
+
b
2
)
y=w'_1\sigma(w_1x+b_1)+w'_2\sigma(w_2x+b_2)
y=w1′σ(w1x+b1)+w2′σ(w2x+b2)
在这个公式中,有w1,w2,w’1,w’2,b1,b2这样6个不同的参数。它们的组合也会对曲线的形状有影响。
例如:
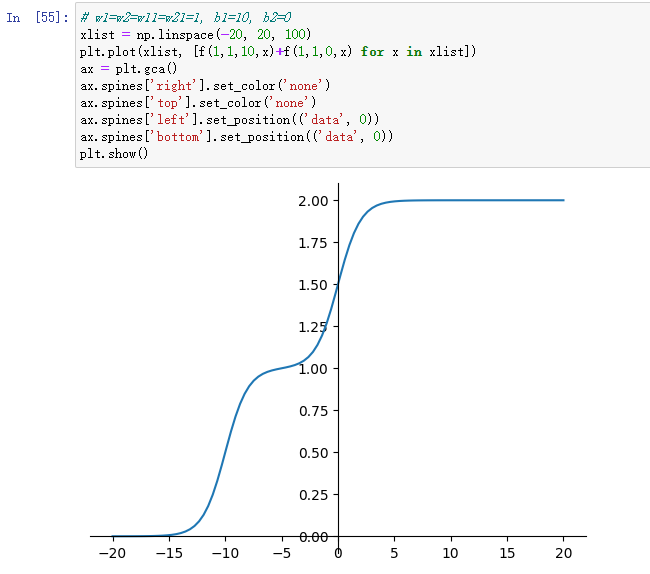
由此可见,合成的函数图像变为了一条具有两个阶梯的曲线。
我们再来看一个参数组合:
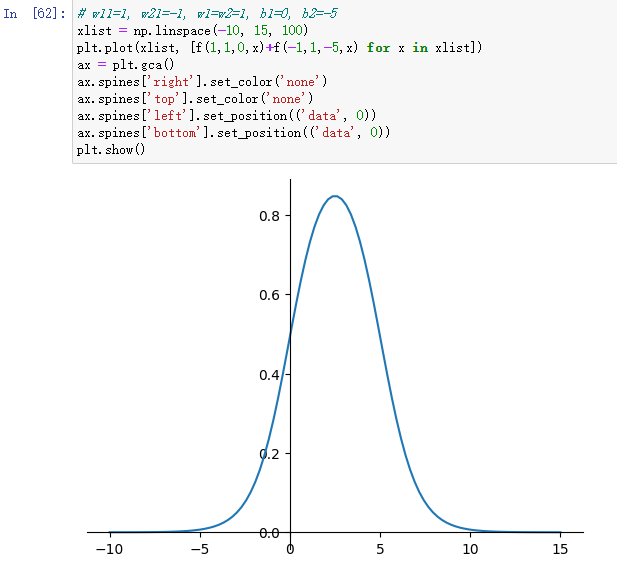
由此可见,我们合成了一条具有单一波峰的曲线,有些类似正态分布的钟形曲线。一般地,只要变换参数组合,我们就可以用两个隐含神经元拟合出任意具有单峰的曲线。
那么,如果有4个或者6个甚至更多的隐含神经元,不难想象,就可以得到具有双峰、三峰和任意多个峰的曲线,我们可以粗略地认为两个神经元可以用来逼近一个波峰(波谷)。事实上,对于更一般的情形,科学家早已从理论上证明,用有限多的隐含神经元可以逼近任意的有限区间内的曲线,这叫做通用逼近定理。
训练与运行
要想完成神经网络的训练,首先要给这个神经网络定义一个损失函数,用来衡量网络在现有的参数组合下输出的表现。
有了损失函数,我们就有了调整神经网络参数的方向——尽可能地让损失函数最小化。因此,神经网络要学习的就是神经元之间连线上的权重及偏置,学习的目的是得到一组能够使总误差最小的参数值组合。
这是一个求极值的优化问题,高等数学告诉我们,只需要令导数为零就可以求得。然而,由于神经网络一般非常复杂,包含大量非线性运算,直接用数学求导数的方法行不通,所以,我们一般使用数值的方式来进行求解,也就是梯度下降算法。每次迭代都向梯度的负方向前进,使得误差值逐步减小。参数的更新要用到反向传播算法,将损失函数沿着网络一层一层地反向传播,来修正每一层的参数。我们在这里不会详细介绍反向传播算法,因为 PyTorch已经自动将这个复杂的算法变成了一个简单的命令:backward。只要调用该命令,PyTorch 就会自动执行反向传播算法,计算出每一个参数的梯度,我们只需要根据这些梯度用梯度下降算法更新参数,就可以完成学习。
神经网络的学习和运行通常是交替进行的。也就是说,在每一个周期,神经网络都会进行前馈运算,从输人端运算到输出端;然后,根据输出端的损失值来执行反向传播算法,从而调整神经网络上的各个参数。不停地重复这两个步骤,就可以令神经网络学习得越来越好。
失败的神经预测器
在弄清楚了神经网络的工作原理之后,下面我们来看看如何用神经网络预测共享单车使用量。
为了让演示更加简单清晰,这里仅选择数据中的前50条记录,绘制出下面的曲线:
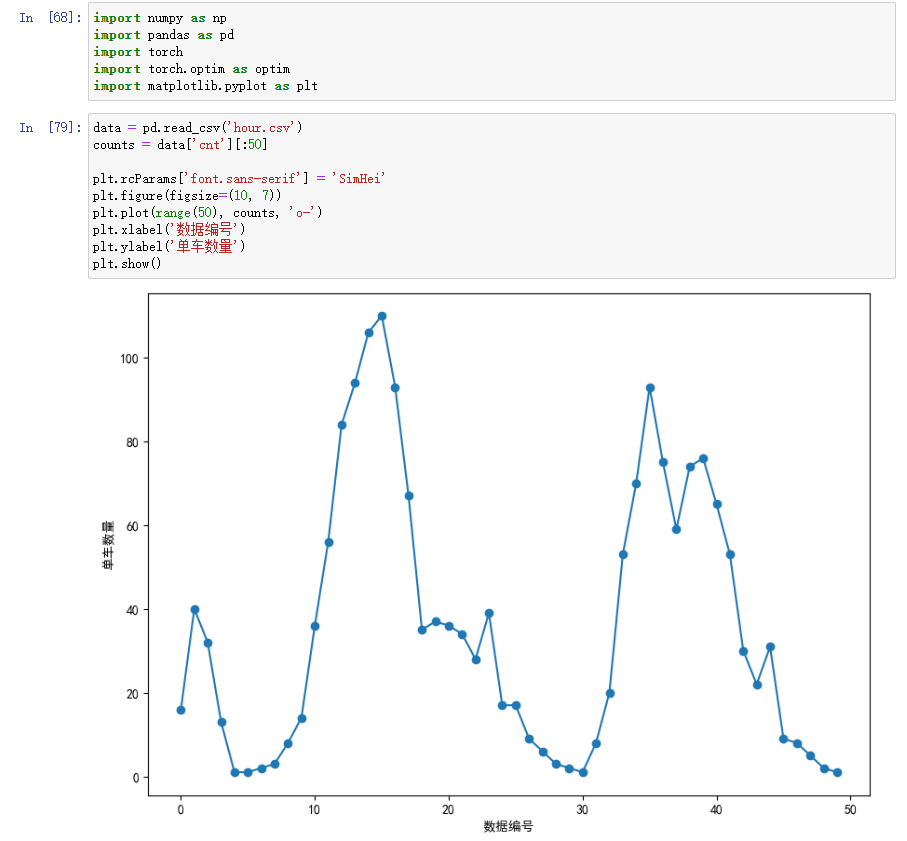
通过观察曲线,我们发现它至少有3个峰,采用10个隐含单元就足以拟合这条曲线了。
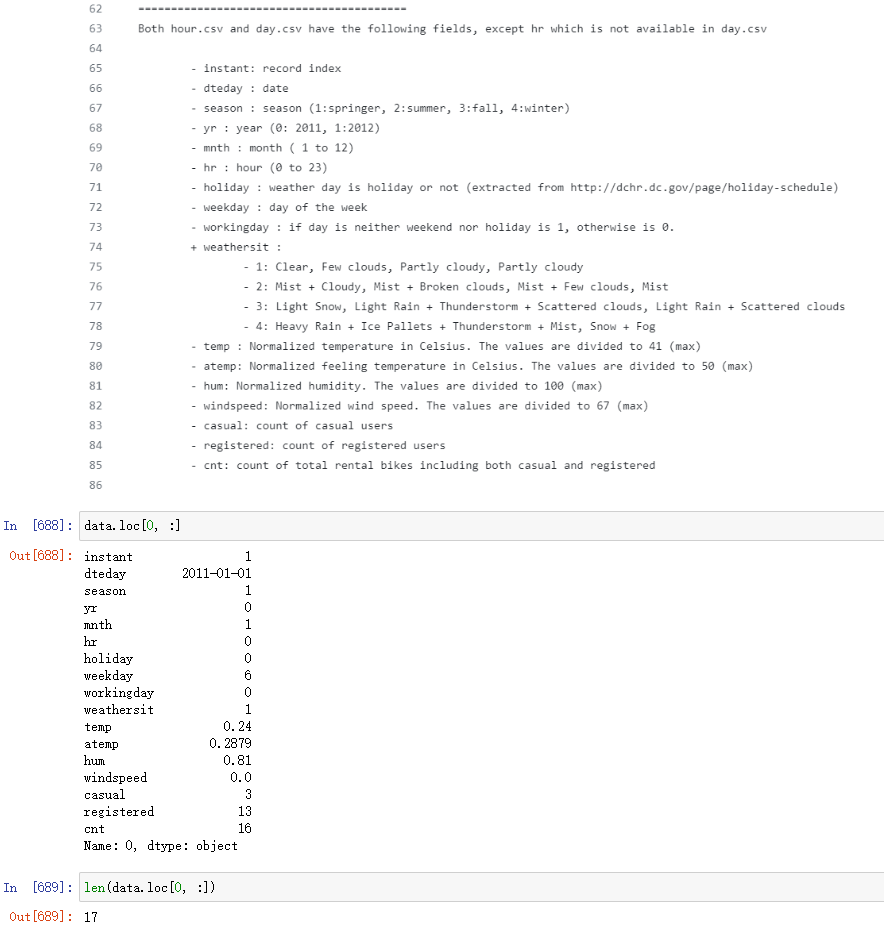
- 准备好数据之后,就可以用PyTorch搭建人工神经网络了。
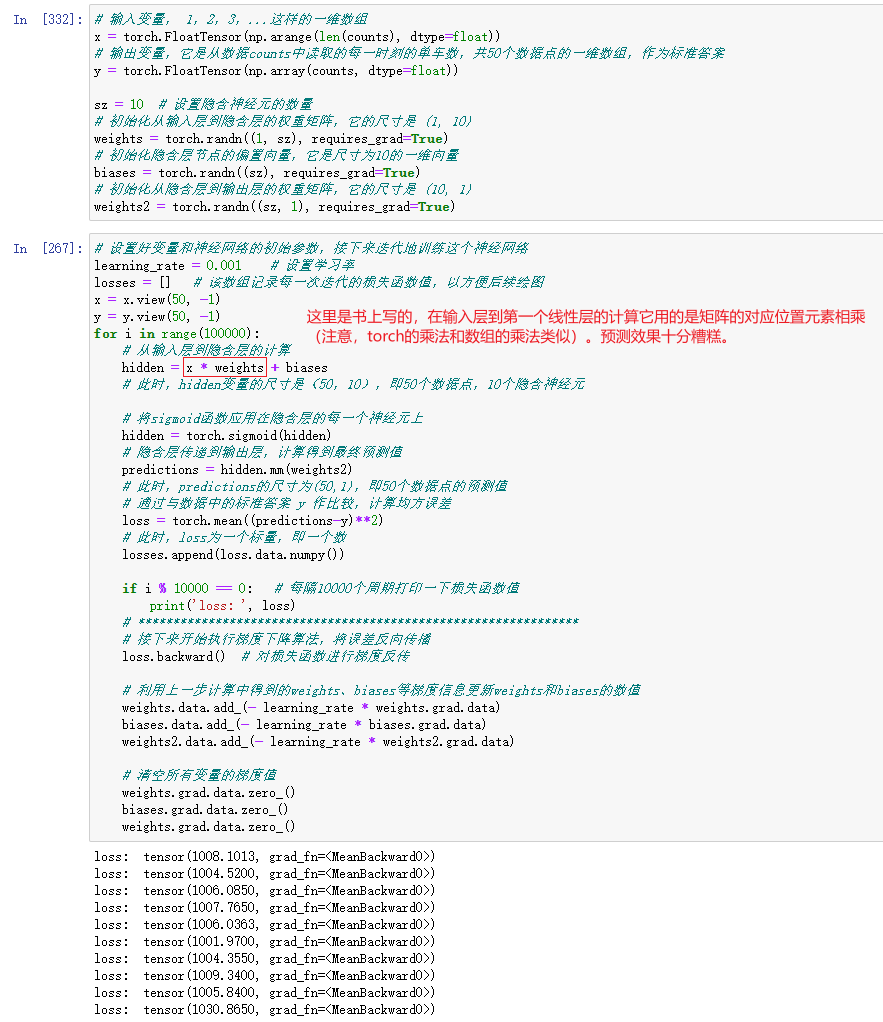
(即使我给他加上退出条件【当loss小于900时退出循环】,也不大行,似乎损失值都没有低于1000的)
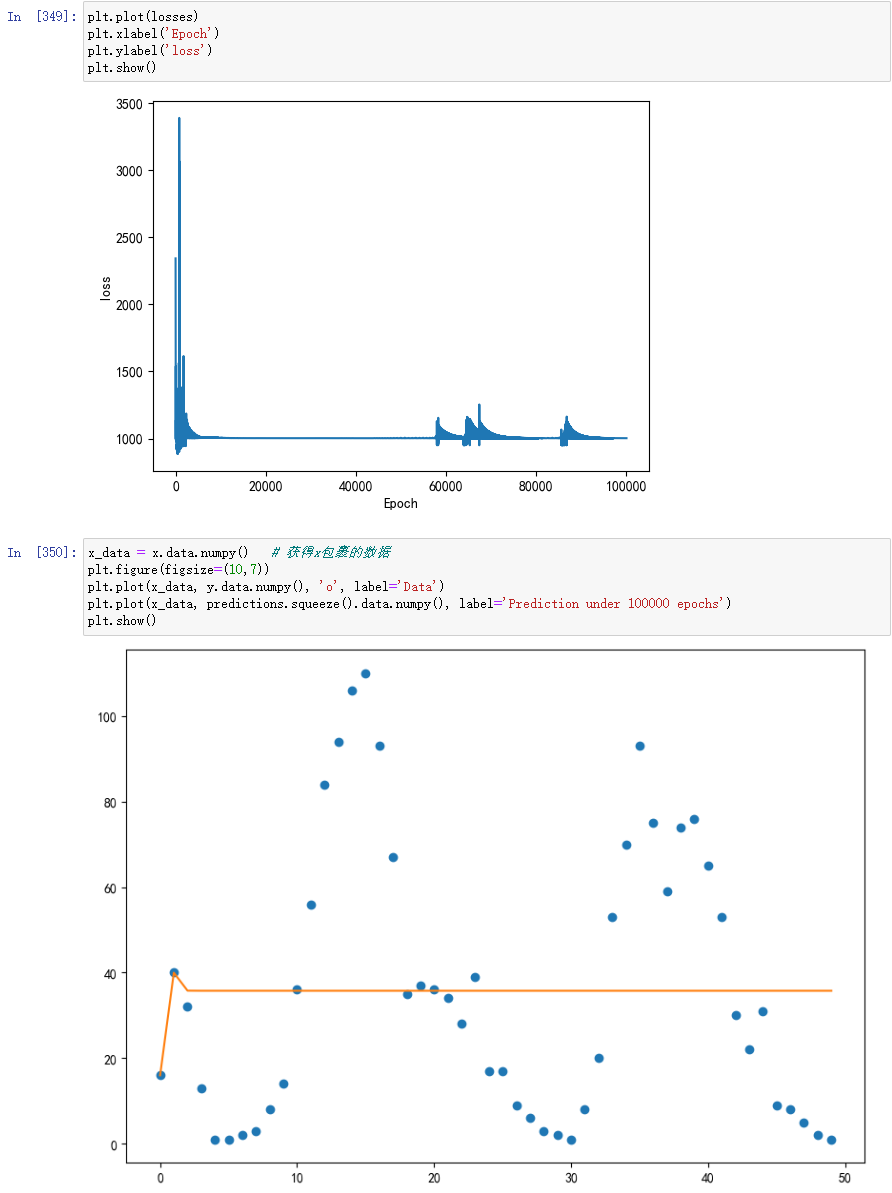
后来发现在执行完一轮之后,在清空变量的梯度值时,weights2的梯度没有清空,写的是weights。。
修改之后,一切正常了

可以看到,我们的预测曲线在第一个波峰比较好地拟合了数据,但是在此后,它却与真实数据相差甚远。
我们知道,x的取值范围是1 ~ 50,而所有权重和偏置的初始值都是设定在(-1,1)的正态分布随机数,那么输入层到隐含层节点的数值范围就成了-50~50,要想将sigmoid函数的多个峰值调节到我们期望的位置,需要耗费很多计算时间。事实上,如果让训练时间更长些,我们可以将曲线后面的部分拟合得很好。
这个问题的解决方法是将输入数据的范围做归一化处理,也就是让 x 的输入数值范围为0 ~ 1.因为数据中x的范围是1~50,所以,我们只需要将每一个数值都除以50就可以了:
x = torch.FloatTensor(np.arange(len(counts), dtype=float)/len(counts))
该操作会使x的取值范围变为0.002, 0.004,…,1。做了这些改进后再来运行程序,可以看到这次训练速度明显加快,拟合效果也更好了:
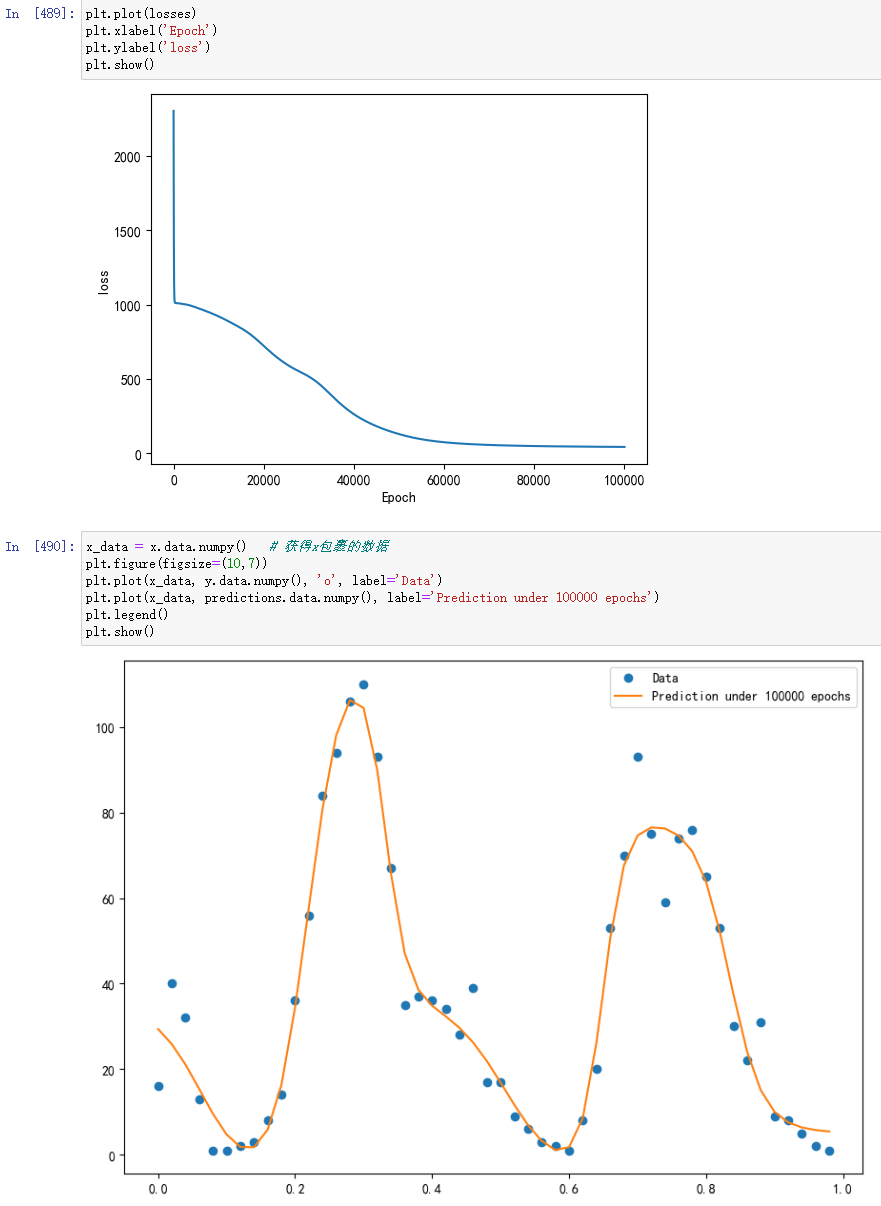
接下来,我们就需要用训练好的模型来做预测了。我们的预测任务是后面50条数据的单车数量。此时x取值是51,52,…,100,同样也要除以50:
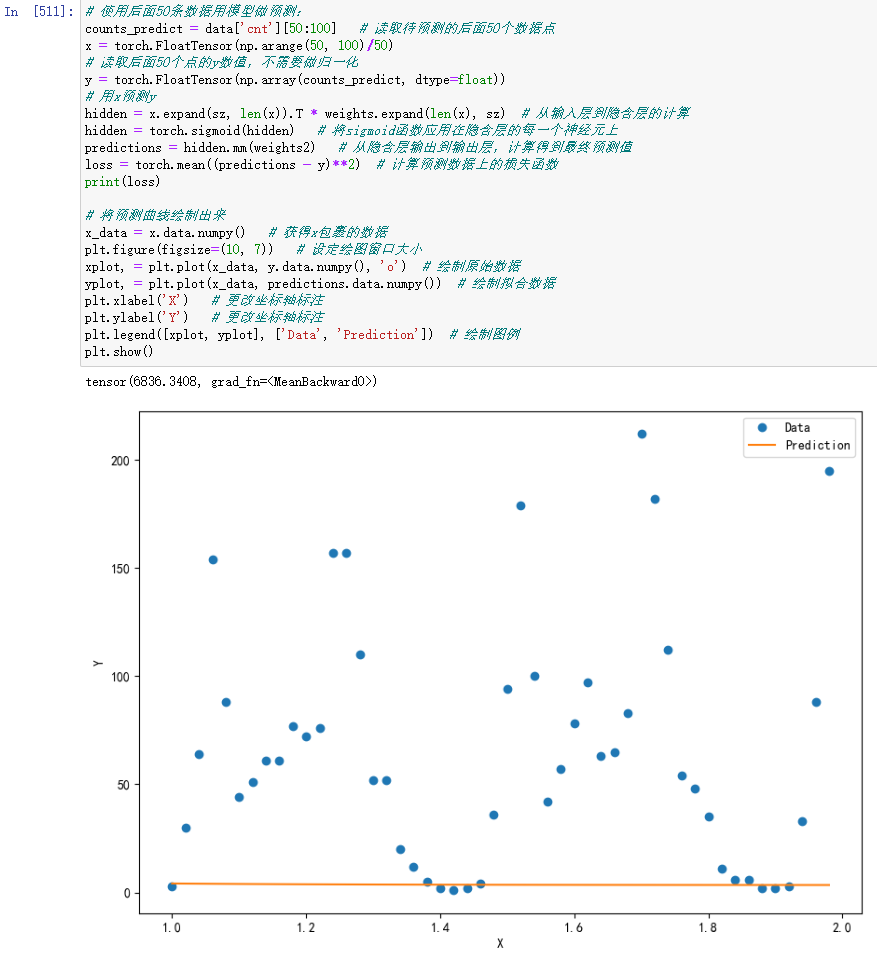
最终,我们得到了上图所示的曲线,直线是我们的模型给出的预测曲线,圆点是实际数据所对应的曲线。模型预测与实际数据几乎可以说完全没对上。
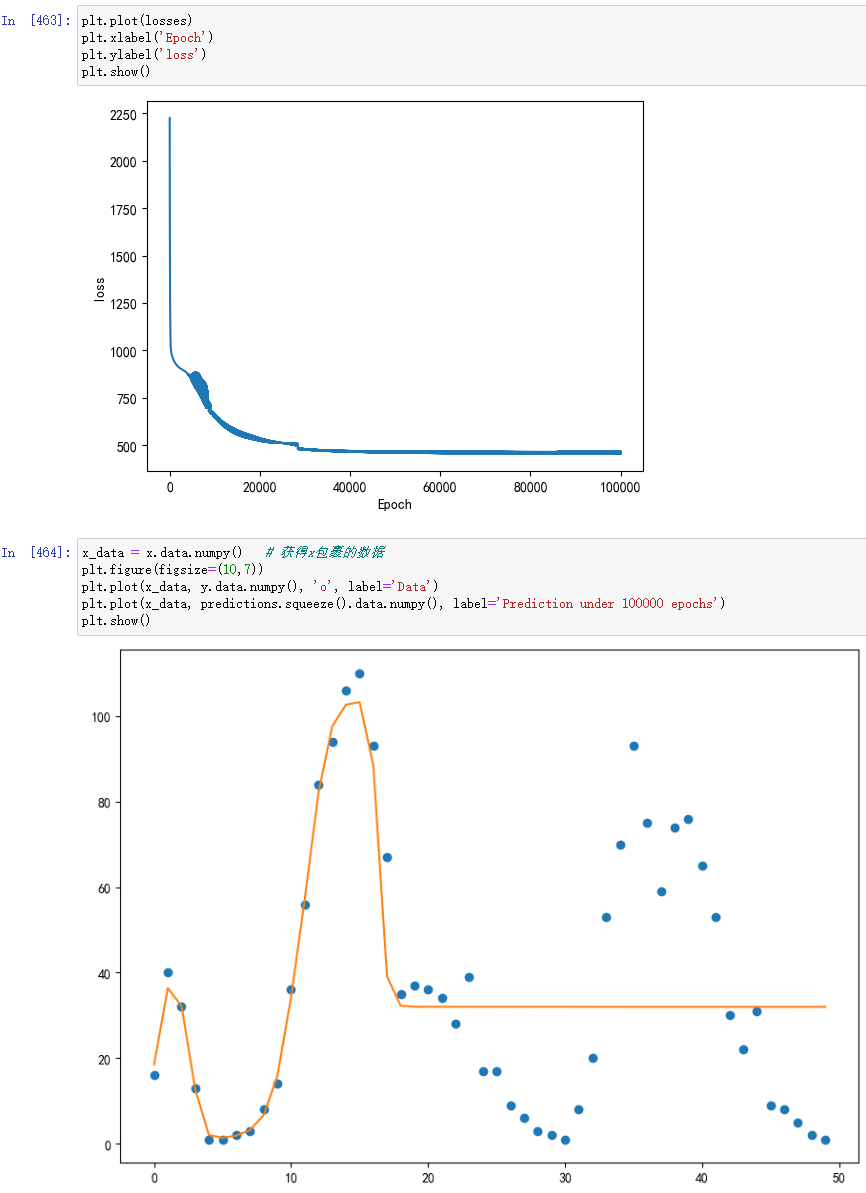
个人修改,用矩阵乘法的方式
我这里将输入层到线性层之间用矩阵乘法来做修改进行尝试:

预测效果好很多
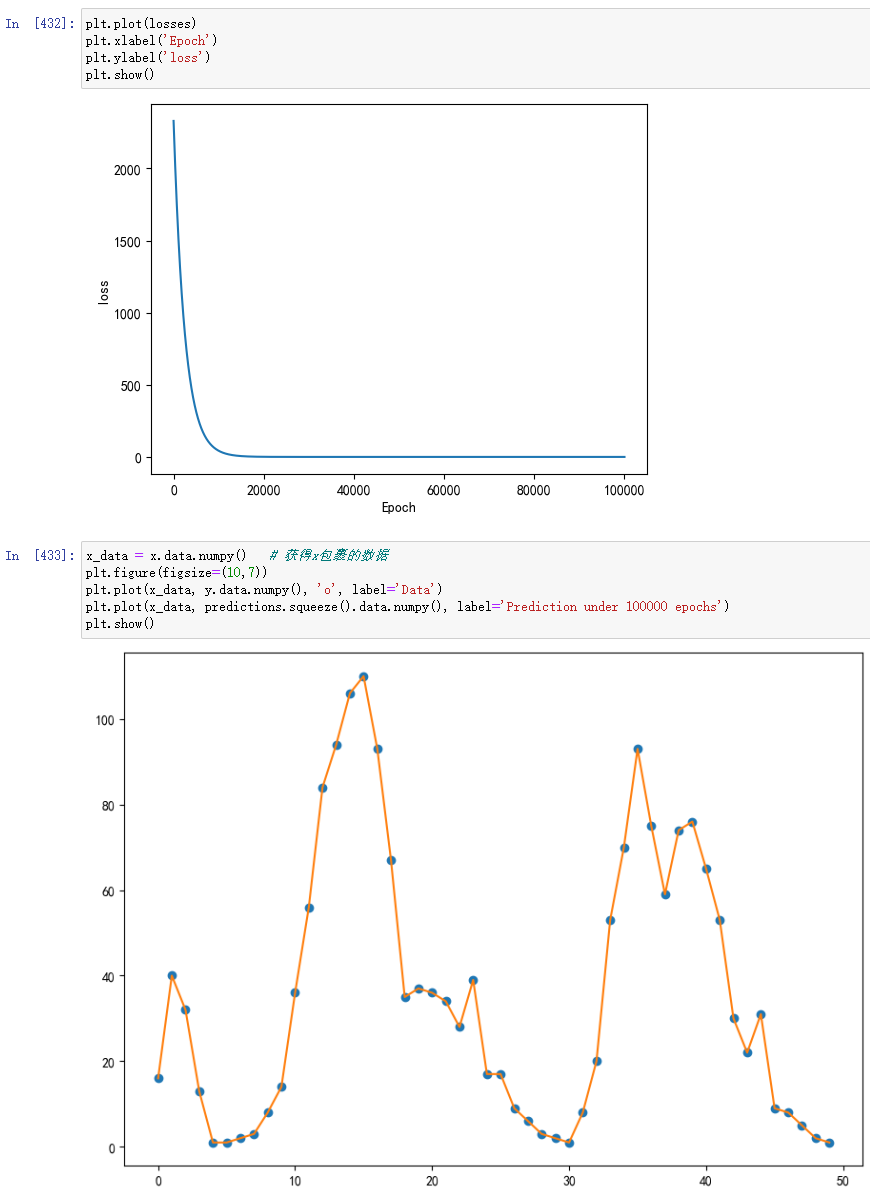
但我怀疑,它是不是过拟合了。。。
果然,用后面50条数据做测试,的确不大行:
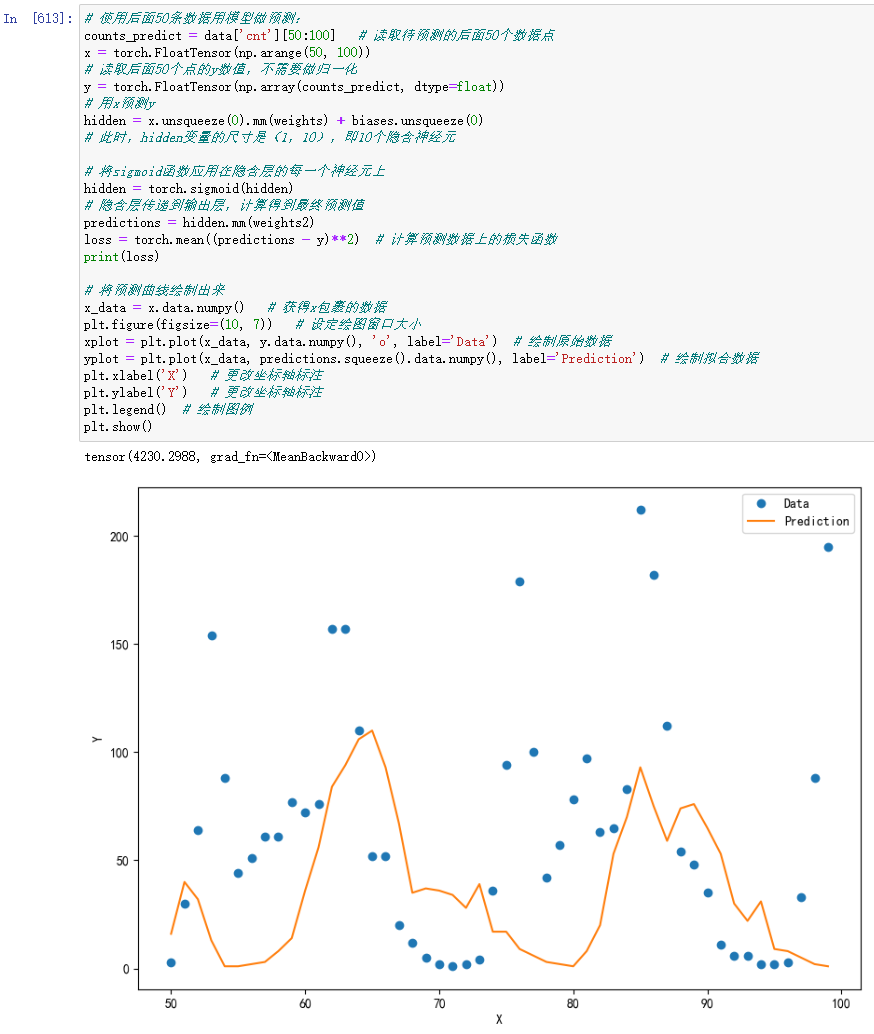
过拟合
所谓过拟合现象,是指模型可以在训练数据上进行非常好的预测,但在全新的测试数据上表现不佳。
为什么会出现这种现象呢?原因就在于我们选择了错误的特征变量:我们尝试用数据的下标(1,2,3,…)或者它的归一化(0.1,0.2,…)来对y进行预测。然而曲线的波动模式(也就是单车的使用数量)显然并不依赖于下标,而是依赖于诸如天气、风速、星期几和是否是节假日等因素。
由这个例子可以看出,一味地追求人工智能技术,而不考虑实际问题的背景,很容易让我们走弯路。当我们面对大数据时,数据背后的意义往往可以指导我们更加快速地找到分析大数据的捷径。
单车预测器 2.0
数据的预处理过程
在我们动手设计神经网络之前,最好还是再认真了解一下数据,因为增强对数据的了解会起到更重要的作用。
深入观察数据,我们发现,所有的变量可以分成两种:一种是类型变量、另一种是数值变量。
所谓的类型变量,是指这个变量可以在不同的类别中取值,例如星期(week) 这个变量就有1,2,3,⋯,0这几种类型,分别代表星期一、星期二、星期三··· ···星期日这几天。而天气状况(weathersit)这个变量可以从1~4中取值,其中1表示晴天,2表示多云,3表示小雨/雪,4表示大雨/雪。
另一种类型是数值类型,这种变量会从一个数值区间中连续取值。例如,湿度(humidity)就是一个从[0,1]区间中连续取值的变量。温度、风速也是这种类型的变量。
我们不能将不同类型的变量不加任何处理地输入神经网络,因为不同的数值代表完全不同的含义。在类型变量中,数字的大小实际上没有任何意义。比如数字5比数字1大,但这并不代表周五会比周一更特殊。除此之外,不同的数值类型变量的变化范围也不一样。如果直接把它们混合在一起,势必会造成不必要的麻烦。综合以上考虑,我们需要对两种变量分别进行预处理。
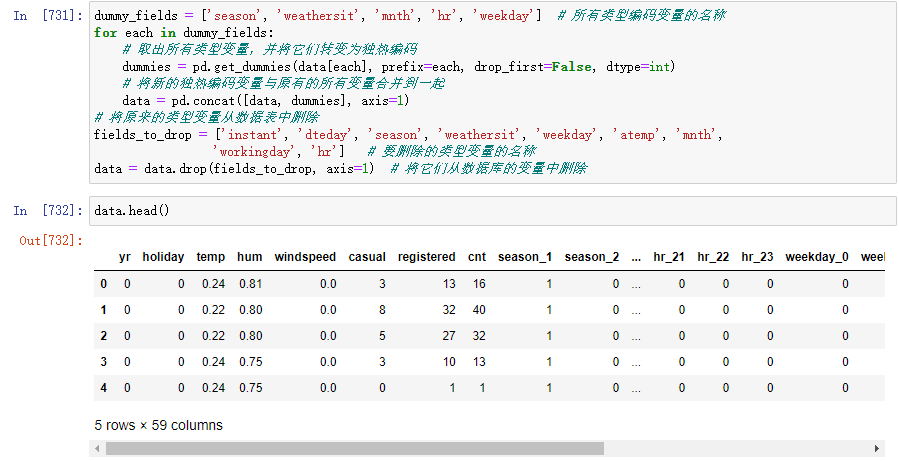
- 类型变量的独热编码
采用独热编码后,不同的数值就转变为了不同的向量,向量的长度由数值类型决定,其他位置都为0,只有一个位置为1。1代表激活,于是独热编码的向量就对应了不同的激活模式。这样的数据更容易被神经网络处理。
接下来,只需要在数据中将某一列类型变量转化为多个列的独热编码向量,就可以完成这种变量的预处理了。
因此,原来的weekday这个属性就转变为7个不同的属性,数据库一下就增加了6列。
pandas可以很容易实现上面的操作,代码如下:
dummy_fields = ['season', 'weathersit', 'mnth', 'hr', 'weekday'] # 所有类型编码变量的名称
for each in dummy_fields:
# 取出所有类型变量,并将它们转变为独热编码
dummies = pd.get_dummies(data[each], prefix=each, drop_first=False)
# 将新的独热编码变量与原有的所有变量合并到一起
data = pd.concat([data, dummies], axis=1)
# 将原来的类型变量从数据表中删除
fields_to_drop = ['instant', 'dteday', 'season', 'weathersit', 'weekday', 'atemp', 'mnth',
'workingday', 'hr'] # 要删除的类型变量的名称
data = data.drop(fields_to_drop, axis=1) # 将它们从数据库的变量中删除
原始数据:
经过处理后,原本只有17列的数据一下子变为了59列,如下:
2. 数值类型变量的处理
数值类型变量的问题在于每个变量的变化范围都不一样,单位也不一样,因此不同的变量不能进行比较。我们采取的解决方法是对这种变量进行标准化处理,也就是用变量的均值和标准差来对该变量做标准化,从而把特征数值的平均值变为0,标准差变为1。比如,对于温度 temp这个变量来说,它在整个数据库中取值的平均值为 mean(temp),标准差 std(temp),那么,归一化的温度计算为:
t
e
m
p
′
=
t
e
m
p
−
m
e
a
n
(
t
e
m
p
)
s
t
d
(
t
e
m
p
)
temp' = \frac{temp-mean(temp)}{std(temp)}
temp′=std(temp)temp−mean(temp)
temp’是一个位于[-1,1]区间的数。这样做的好处是可以将不同取值范围的变量设置为处于平等的地位。
代码演示:
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/c31161ccf7244e93e53b19503bbaee85.png)
3. 数据集的划分
首先,将变量集合分为特征和目标两个集合。其中,特征变量集合包括:年份(yr)、是否是节假日(holiday)、温度(temp)、湿度(hum)、风速(windspeed)、季节1 ~ 4(season)、天气1 ~ 4(weathersit,不同天气状况)、月份1 ~ 12(mnth)、小时0 ~ 23(hr)和星期0 ~ 6(weekday),它们是输入给神经网络的变量。目标变量包括:用户数(cnt)、临时用户数(casual),以及注册用户数(registered)。其中我们仅仅将cnt作为目标变量,另外两个暂时不做任何处理。我们将利用56个特征变量作为神经网络的输入,来预测1个变量作为神经网络的输出。
接下来,我们将17379条记录划分为两个集合:前16875条记录作为训练集,用来训练我们的神经网络;后21天的数据(504条记录)作为测试集,用来检验模型的预测效果,这部分数据是不参与神经网络训练的。
数据处理代码如下:
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/8ffeb655537bd23514eec669f7991424.png)
构建神经网络
在数据处理完毕后,我们将构建新的人工神经网络。这个网络有3层:输入层、隐含层和输出层。每个层的尺寸(神经元个数)分别是56、10和1。其中,输入层和输出层的神经元个数分别由数据决定,隐含神经元个数则根据我们对数据复杂度的预估决定。通常,数据越复杂,数据量越大,需要的神经元就越多。但是神经元过多容易造成过拟合。
除了前面讲的用手工实现神经网络的张量计算完成神经网络搭建外,PyTorch还实现了自动调用现成的函数来完成同样的操作,这样的代码更加简洁,如下所示:
# 定义神经网络架构,features.shape[1]个输入单元,10个隐含单元,1个输出单元
input_size = features.shape[1]
hidden_size = 10
output_size = 1
batch_size = 128
neu = torch.nn.Sequential(
torch.nn.Linear(input_size, hidden_size),
torch.nn.Sigmoid(),
torch.nn.Linear(hidden_size, output_size),
)
在这段代码里,我们可以调用torch.nn.Sequential()来构造神经网络,并存放到neu变量中。torch.nn.Sequential()这个函数的作用是将一系列的运算模块按顺序搭建成一个多层的神经网络。在本例中,这些模块包括从输入层到隐含层的线性映射torch.nn.Linear(input_size, hidden_size)、隐含层的非线性sigmoid函数torch.nn.Sigmoid(),以及从隐含层到输出层的线性映射torch.nn.Linear(hidden_size, output_size)。值得注意的是,Sequential里面的层次并不与神经网络的层次严格对应,而是指多步的运算,它与动态计算图的层次相对应。
我们也可以使用PyTorch自带的损失函数:
cost = torch.nn.MSELoss()
这是PyTorch自带的一个封装好的计算均方误差的损失函数,它是一个函数指针,赋予了变量cost。在计算的时候,我们只需要调用cost(x,y)就可以计算预测向量x和目标向量y之间的均方误差。
除此之外,PyTorch还自带了优化器来自动实现优化算法:
optimizer = torch.optim.SGD(neu.parameters(), lr=0.01)
torch.optim.SGD()调用了PyTorch自带的随机梯度下降算法作为优化器。在初始化optimizer的时候,我们需要待优化的所有参数(在本例中,传入的参数包括神经网络neu包含的所有权重和偏置,即neu.parameters()),以及执行梯度下降算法的学习率 lr = 0.01。在一切都准备好之后,我们便可以实施训练了。
数据的批处理
在进行训练循环的时候,如果在每一个训练周期内都将所有的数据一股脑地输入神经网络的话,这在数据量不大的情况下没有什么问题。但是,如果数据量很大,则会出现运算速度过慢、迭代可能不收敛等问题。
解决方法通常是采用批处理的模式,也就是将所有的数据记录划分成一个批次大小的小数据集,然后在每个训练周期给神经网络输入一批数据,批次的大小依问题的复杂度和数据量的大小而定,在这里,我们设定batch_size=128。
采用批处理后的训练代码如下:
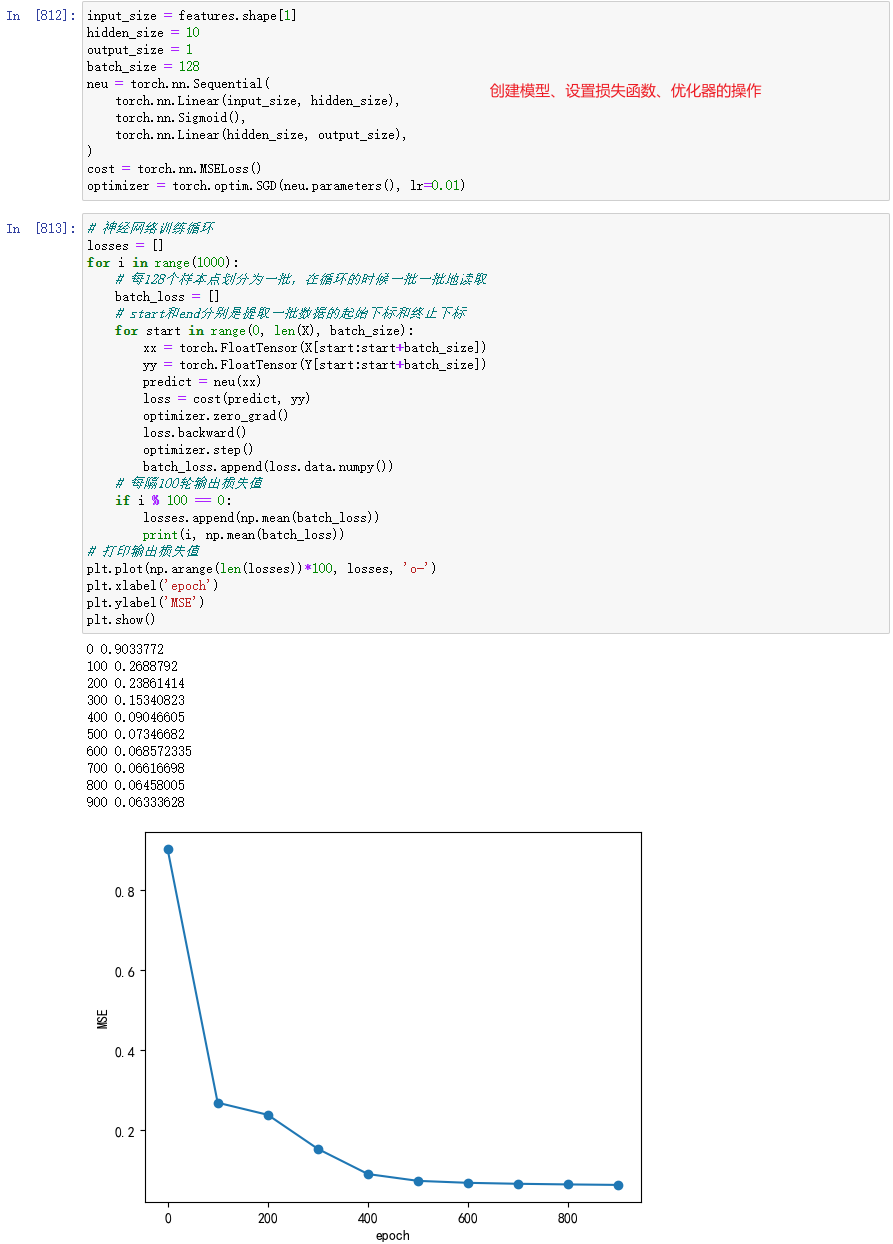
运行上面这段程序,我们便可以训练这个神经网络了。上图执行结果展示的是随着训练周期的增加,损失函数的下降情况。其中,横坐标表示训练周期,纵坐标表示平均误差。可以看到,平均误差随训练周期的增加快速下降。
测试神经网络
接下来,我们便可以用训练好的神经网络在测试集上进行预测,并且将后21天的预测数据与真实数据画在一起进行比较:
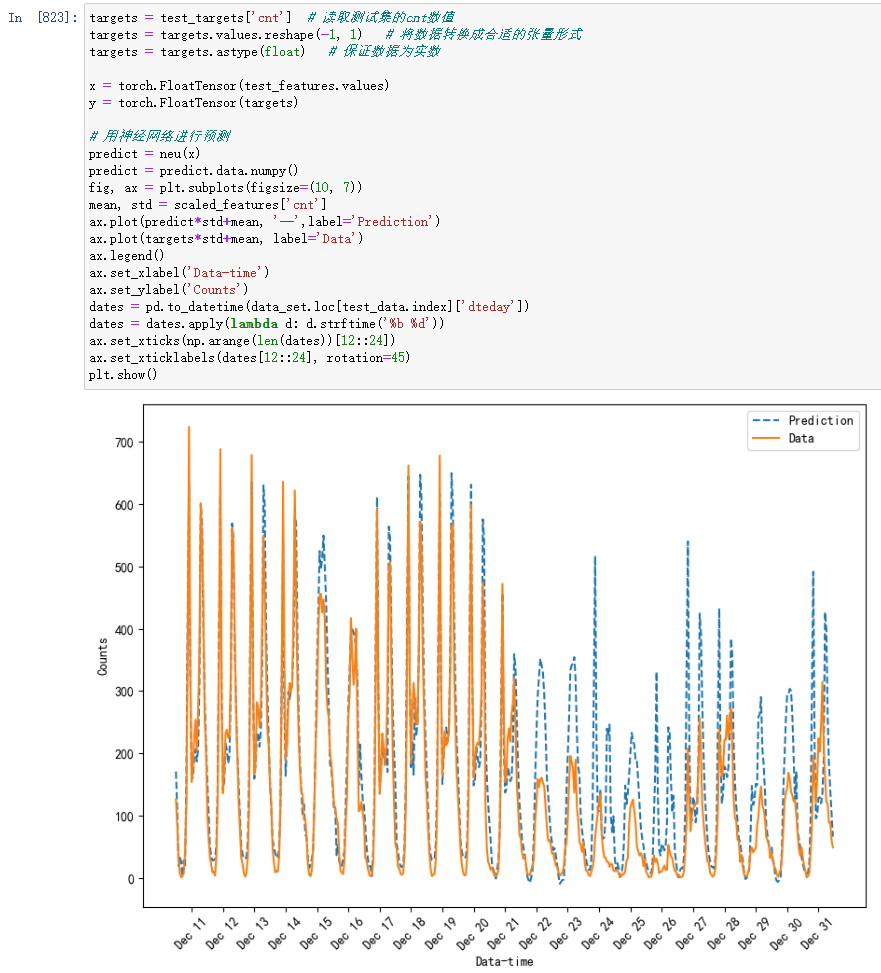
实际曲线与预测曲线的对比如上图所示。其中横坐标是不同的日期,纵坐标是预测或真实数据的值,虚线为预测曲线,实线为实际数据。
可以看到,两条曲线基本是吻合的,但是在12月25日前后几天的实际值和预测值偏差较大。为什么这段时间的表现这么差呢?
仔细观察数据,我们发现12月25日正好是圣诞节。对于欧美国家来说,圣诞节就相当于我国的春节,在圣诞节假期前后,人们的出行习惯会与往日有很大的不同。但是,在我们的训练样本中,因为整个数据仅有两年的长度,所以包含圣诞节前后的样本仅有一次,这就导致我们没办法对这一假期的模式进行很好的预测。
剖析神经网络neu
目前我们的工作已经全部完成了。不过,接下来再对上面这个训练好的神经网络neu进行剖析,看看它究竟为什么在一些数据上表现优异,而在另一些数据上表现欠佳。
对于我们来说,神经网络在训练的时候发生了什么完全是黑箱,但是,神经网络节点之间连线的权重实际上就在计算机的存储中,我们可以把感兴趣的数据提取出来进行分析。
我们定义了一个函数feature(),用于提取神经网络中存储在连线和节点中的所有参数,代码如下:
# 定义一个函数feature(),用于提取神经网络中存储在连线和节点中的所有参数
def feature(X, net):
# 定义一个函数,用于提取网络的权重信息。
# 所有的网络参数信息全部存储在Neu的named_parameters集合中
X = torch.from_numpy(X).type(torch.FloatTensor)
dic = dict(net.named_parameters()) # 从这个集合中提取数据
weights = dic['0.weight'] # 可以按照”层数.名称“来索引集合中的相应参数值
biases = dic['0.bias']
h = torch.sigmoid(X.mm(weights.T) + biases.expand(len(X), -1))
# 隐含层的计算过程
return h # 输出层的计算
在上面这段代码中,我们用 net.named_parameters()命令提取出神经网络的所有参数,其中包括了每一层的权重和偏置,并且把它们放到python字典中。接下来就可以通过如上代码来提取数据,例如可以通过 dic[‘0.weight’] 和 dic[‘0.bias’] 的方式得到第一层的所有权重和偏置。此外,我们还可以通过遍历参数字典 dic 获取所有可提取的参数名称。
由于数据量较大,因此我们选取一部分数据输入神经网络,并提取网络的激活模式。我们知道,预测不准的日期有12月22日、12月23日、12月24日这3天。所以,就将这3天的数据聚集到一起,存入subset 和 subtargets 变量中:
bool1 = data_set['dteday'] == '2012-12-22'
bool2 = data_set['dteday'] == '2012-12-23'
bool3 = data_set['dteday'] == '2012-12-24'
# 将3个布尔型数组求与
bools = [any(tup) for tup in zip(bool1, bool2, bool3)]
# 将相应的变量取出
subset = test_features.loc[data_set[bools].index]
subtargets = test_targets.loc[data_set[bools].index]
subtargets = subtargets['cnt']
subtargets = subtargets.values.reshape(-1, 1)
将这3天的数据输入神经网络中,用前面定义的feature()函数读出隐含神经元的激活数值,存入results中。为了方便阅读,可以将归一化输出的预测值还原为原始数据的数值范围。
# 将数据输入到神经网络中,读取隐含神经元的激活数值,存入result中
results = feature(subset.values, neu).data.numpy()
# 这些数据对应的预测值(输出层)
predict = neu(torch.FloatTensor(subset.values)).data.numpy()
# 将预测值还原为原始数据的数值范围
mean, std = scaled_features['cnt']
predict = predict * std + mean
subtargets = subtargets * std + mean
接下来,我们将隐含神经元的激活情况全部画出来。同时,为了比较,我们将这些曲线与模型预测的数值画在一起,可视化的结果如下图所示:
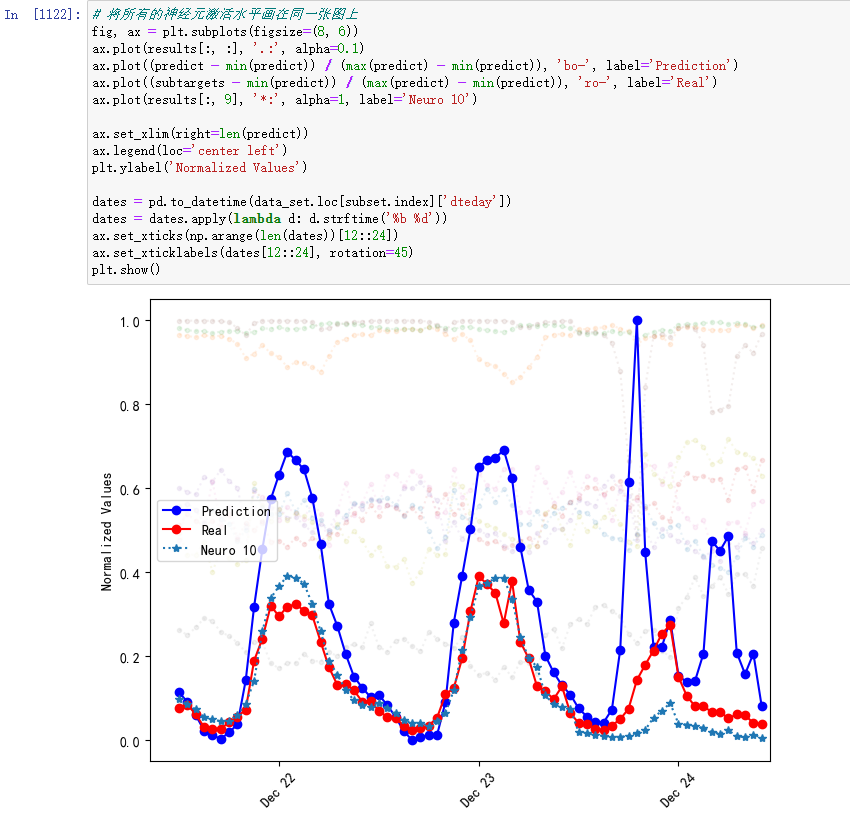
图中蓝色曲线是模型的预测值,红色曲线是实际值,不同颜色的浅色虚线是前九个神经元的输出值,绿色五角星虚线是第十个神经元的输出值。可以发现,Neuro 10的输出曲线与真实输出曲线比较接近。因此,我们可以认为该神经元对提高预测准确性有更大的贡献。
同时,我还想知道Neuro 10为什么表现较好以及它的激活是由谁决定的。进一步分析它的影响因素,发现影响大小是通过输入层指向它的权重来判断的。
我们可以通过下列代码将这些权重可视化:
# 找到与峰值对应的神经元,将其到输入层的权重输出
dic = dict(neu.named_parameters())
weights = dic['0.weight']
plt.plot(weights.data.numpy()[9,:], 'o-')
plt.xlabel('Input Neurons')
plt.ylabel('Weight')
结果如下图所示(我加了几个设置注释的命令)。横轴代表不同的权重,也就是输入神经元的编号;纵轴代表神经网络训练后的连线的权重。例如,横轴的第12个数对应输入层的第12个神经元,对应到输入数据中,是检测天气类别的类型变量。第31个数是小时数,也是类型变量,检测的是早上5点这种模式。我们可以将其理解为,纵轴的值为正就是促进,值为负就是抑制。所以下图中的波峰就是将该神经元激活,波谷就是神经元未激活。
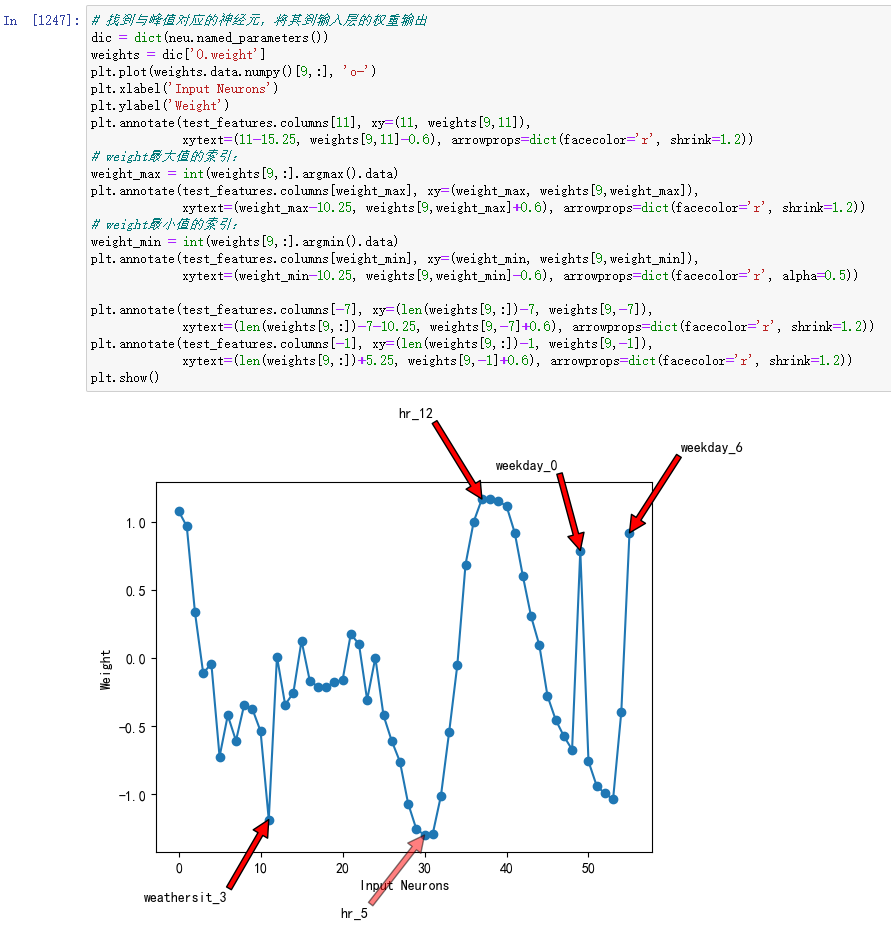
我们看到,这条曲线在hr_12 和 weekday_0,6 方面有较高的权重,这表示 Neuro 10正在检测现在是不是中午12点,同时也在检测今天是不是周六或者周日。如果满足这些条件,则神经元就会被激活。与此相对的是,神经元在 weathersit_3和hr_5这两个输入上的权重值为负值,并且刚好是低谷,这意味着该神经元会在”下雨或下雪“,以及”早上5点“的时候被抑制。通过翻看日历可知,2012年的12月22日和23日刚好是周六和周日,因此 Neuro 10被激活了,它们对正确预测这两天的正午高蜂做了贡献。但是,由于圣诞节即将到来,人们可能早早回去为圣诞做准备,因此这个周末比较特殊,并未出现往常周末的大量骑行需求,于是Neuro 10给出的激活值导致了正午单车预测值过高。
与此类似,我们可以找到导致12月 24日早晚高峰预测值过高的原因。我们发现 Neuro 6起到了主要作用,因为它的波动刚好跟预测曲线在24 日的早晚高峰负相关,如下图所示:
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/046676e62ef73db03403b8f2d470ec77.png)
同理,这个神经元对应的权重及其检测的模式如下图所示:
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/6429cacf1cb9693f209716672abc9bd2.png)
这个神经元检测的模式和 Neuro 10 相似却相反,它在早晚高峰的时候受到抑制,在节假日和周末激活。进一步考察从隐含层到输出层的连接,我们发现 Neuro 6的权重为负数,但是这个负值又没有那么小。

所以,这就导致了 Neuro 6在12月24日早晚高峰的时候被抑制,但是这个信号抑制的效果并不显著,无法导致预测尖峰出现。
所以,我们分析出神经预测器 Neu 在这3天预测不准的原因是圣诞假期的反常模式。12月24日是圣诞夜,该网络对节假日早晚高峰抑制单元的抑制程度不够,所以导致了预测不准。如果有更多的训练数据,我们可以将 Neuro 6的权重调节得更低,这样就有可能提高预测的准确率。
小结
- 通过调整神经网络中的参数,我们可以得到任意形状的曲线
- 批处理:即将数据切分成批,在每一个训练周期中,都用一小批数据来训练神经网络并调整参数。这种批处理的方法既可以加速程序的运行,又能够让神经网络稳步地调节参数。
- 神经网络模型的预测能力不只和神经元的个数有关,还与神经网络的结构和输入数据有关。
- 在训练神经网络时需要清空梯度,因为backward()函数是会累加梯度的。我们在进行一次训练后,就立即进行梯度反传,所以不需要系统累加梯度。不清空梯度有可能导致模型无法收敛。
- 并不是所有神经网络都可以进行剖析。因为预测共享单车使用量的模型结构比较简单,隐藏神经元只有10个。当网络模型中神经元的个数较多或者有多层神经元的时候,神经网络模型的某个”决策“会难以归因到某个神经元里。这时就难以用”剖析“的方式来分析神经网络模型了。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









