






从python3.7开始,字典dict会按照键值对插入字典的顺序排序。OrderedDict的顺序是按照插入时间顺序还是键值排列顺序?OrderedDict与dict的区别是什么?OrderedDict的底层实现是什么?
OrderedDict的顺序也是按照键值对插入时间顺序来排的。这一点它与dict是一样的:
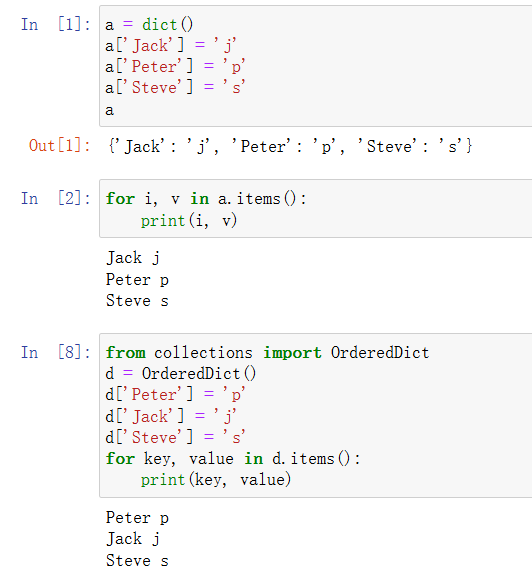
要说区别吧,在内置的方法上倒是有,
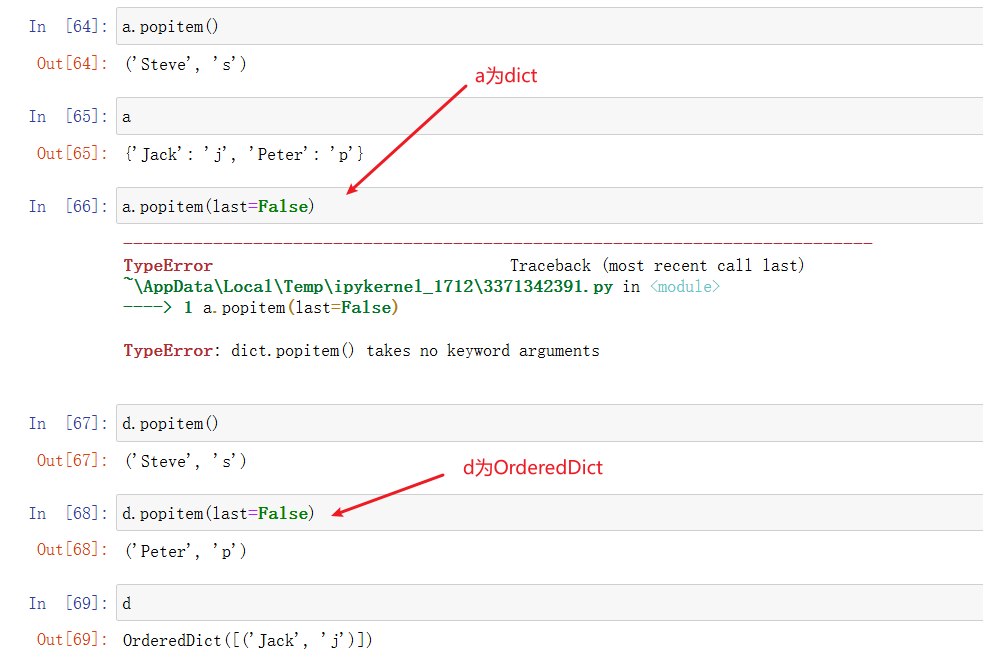
字典的popitem方法没有参数last,它不能通过设置last=False来删除第一个插入的键值对;OrderedDict可以。
另外一个区别,dict没有move_to_end方法,OrderedDict有。
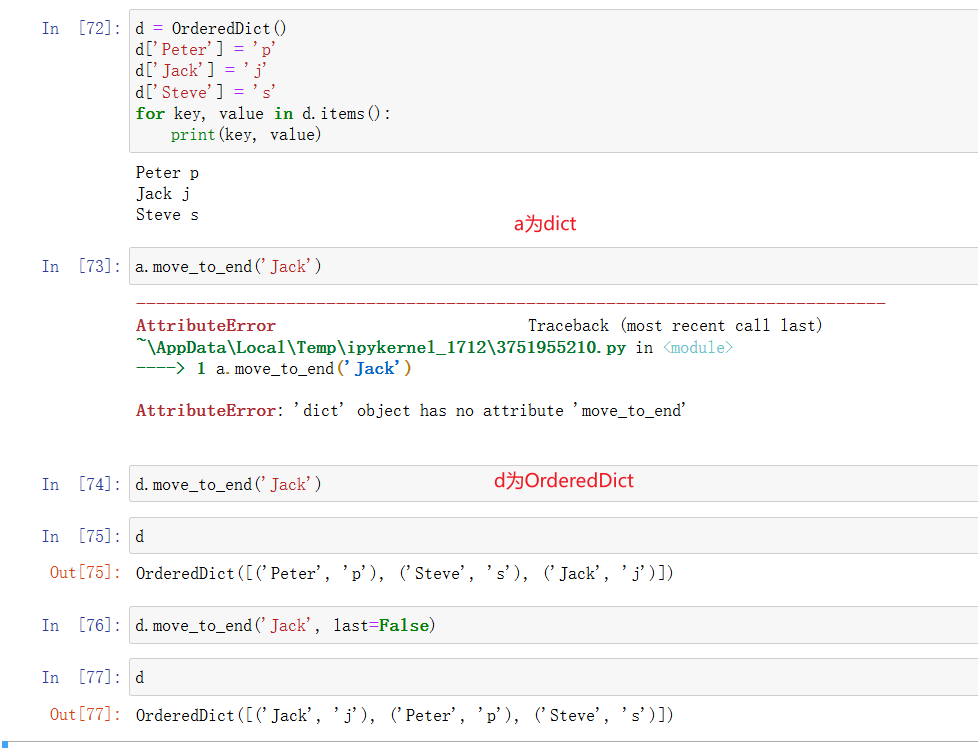
OrderedDict在内部使用了一个双向链表来维护元素的插入顺序。当向OrderedDict中添加元素时,它会被添加到链表的尾部。当我们遍历OrderedDict时,它会按照链表中的顺序依次访问元素。
什么是全局解释器锁(GIL)
在Python中,全局解释器锁(GIL)本质上是一个互斥锁,它是在解释器(CPython)层面上的锁。Python语言设计之初,计算机广泛使用的还是单核CPU,为了解决多线程之间的数据完整与状态同步问题,最简单的方法就是加锁,每个线程在运行前都需要获取一把锁,从而保证同一时刻只能有一个线程运行,这把锁就是全局解释器锁。
GIL确保了一个进程中同一时刻只有一个线程运行,多线程在实际运行中只调用了一个CPU核心,无法使用多个CPU核心,因此多线程不能在多个CPU核心上并行,面对计算密集型的操作时,无法利用CPU的多核优势,运行效率较低。但是GIL对于单线程及I/O密集型的多线程运行没有影响。Python中的每个进程都有自己的解释器,因此多进程不受GIL的限制,可以在CPU的多个核心上并行,多进程适合计算密集型的操作,但是进程的开销较大,不适用于I/O密集型的操作。
GIL不是Python的缺陷,只是一种针对解释器的设计思想,其中使用GIL的解释器有CPython,未使用GIL的解释器有JPython。
多线程的限制以及多进程参数传递的方式
在Python中由于GIL的存在,导致进程中同一时刻只能有一个线程运行,因此,多线程无法使用多个CPU核心实现并行,只能在单一CPU核心上实现并发。面对计算密集型操作多线程无法利用CPU多核优势,运行效率较低。
多进程不受GIL的影响,可以在多个CPU核心并行。进程与线程之间的数据彼此独立,多进程传递参数时可以通过 multiprocessing.Value 或 multiprocessing.Array 方式传递。
什么是多线程竞争
进程与进程之间相互独立,每个进程都拥有自己的内存空间。线程不具有自己的内存空间,是进程的一个实例,一个进程中可以存在多个线程,这些线程共享进程的内存空间。当多个线程运行时,可能对内存空间中的资源进行抢占。例如,A、B两个人相当于两个线程,他们共用一个银行账户,银行账户中有500元,这个银行账户相当于进程内存空间中的共享资源,现在A、B同时去银行办理业务,他们看到的账户余额都是500元,A存100元,账户余额变为600元;B取出200元,账户余额变为300元。
这种情况就是发生了多线程的抢占,它们同时访问共享资源,进行操作,多线程抢占会导致数据错乱,运行结果出错。因此,为了保证线程安全,需要对共享资源加锁,保证同一时刻只有一个线程访问和操作共享资源,这样当A进行存钱时,B无法进行取钱操作,A存完钱,银行账户更新为600元后,B才能取钱,最终银行账户变为400元。
手撕代码环节
"""
设计并实现一个哈希表,提供get/set两个接口,
接口具体设计不限,哈希算法不限,哈希碰撞处理算法不限。
简单起见, key和value仅要求为整型数。
请自行提供测试用例,除基本功能外,要求涵盖哈希碰撞的情况
"""
class HashTable:
def __init__(self, size):
self.size = size
self.keys = [None] * size
self.values = [None] * size
def _hash_function(self, key):
# 返回的映射逻辑为取键的余数
return key % self.size
def _get_next_index(self, current_index):
return (current_index + 1) % self.size
def get(self, key):
hash_key = self._hash_function(key)
start_index = hash_key
while self.keys[hash_key] is not None:
if self.keys[hash_key] == key:
return self.values[hash_key]
hash_key = self._get_next_index(hash_key)
if hash_key == start_index:
break
def set(self, key, value):
hash_key = self._hash_function(key)
start_index = hash_key
while self.keys[hash_key] is not None and self.keys[hash_key] != key:
hash_key = self._get_next_index(hash_key)
if hash_key == start_index:
raise Exception("Hash table is Full")
self.keys[hash_key] = key
self.values[hash_key] = value
if __name__ == "__main__":
a = HashTable(5)
for i in range(5):
a.set(i + 1, i + 3)
print("=======")
for i in range(5):
print(a.get(i + 1))
print("=========")
print(a.get(6))
a.set(6, 1)















 1097
1097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









