




 本文详细介绍了各种排序算法(如冒泡、合并、二分、快速、希尔、归并、堆、桶排序),数据结构(如二分搜索树、堆结构),以及哈夫曼和Prim算法在构建最优前缀码和最小生成树中的应用。重点讲解了如何利用堆结构优化操作和哈夫曼树的构建过程。
本文详细介绍了各种排序算法(如冒泡、合并、二分、快速、希尔、归并、堆、桶排序),数据结构(如二分搜索树、堆结构),以及哈夫曼和Prim算法在构建最优前缀码和最小生成树中的应用。重点讲解了如何利用堆结构优化操作和哈夫曼树的构建过程。
选择排序

冒泡排序

合并有序数组

while…else语句是用来判断while循环是否被完整执行完的语句。如果while循环的结束是因为while后面的判断语句idx<len(arr1)的返回值为False,则执行else;如果是因为break而跳出循环,则不执行else
二分查找

二分搜索树中的插入与搜索

快速排序
方法一:

方法二:

方法三:

希尔排序

在for循环中,由于每组的第一个元素不用进行插入排序,而它们的下标处于0~step-1,所以从下标step开始遍历。
需要注意的是,如果要先分组,然后一次性使组内的元素有序,需要使用两个循环。为了提高效率,上面脚本直接使用一个for循环,每遍历到一个数,就对它所在的组进行插入排序。这样遍历同样符合插入排序的顺序要求。在插入排序中,要改变当前下标的值,所以使用变量 ind 存储当前下标,防止影响 for 循环。
普通插入排序等同于增量为 1 的希尔排序,跨元素的希尔排序实际上只改变了增量,逻辑上与普通插入排序没有区别。
归并排序

- 参考书籍的优化版归并排序:

堆排序:
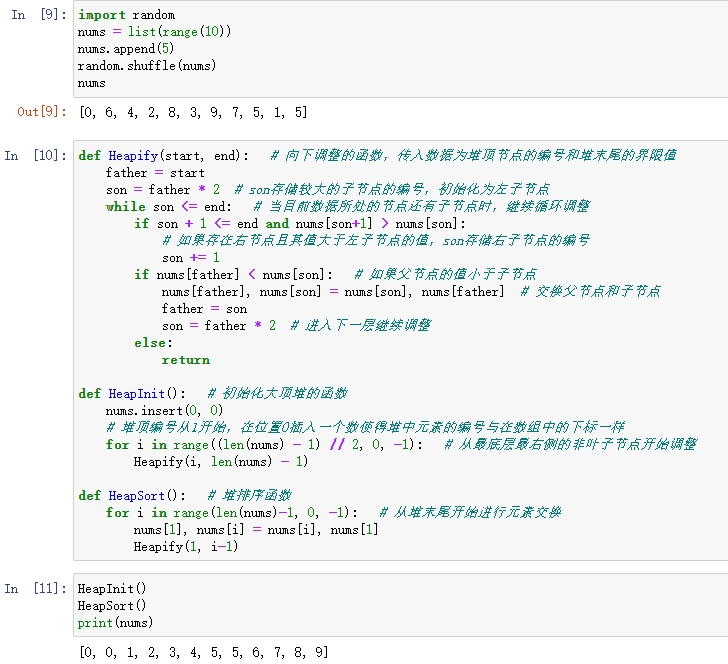
先调用HeapInit()函数对堆进行初始化。函数中的for循环对所有非叶子节点进行遍历。传进向下调整的Heapify()函数的参数有两个,一个是要调整的堆的堆顶,另一个是堆中最大的叶子节点的范围。因为可能调整的所有堆的末尾都是叶子节点,而叶子节点的编号乘2必定大于数组长度,所以可以使用要排序的数组长度(len(nums)-1,因为下标0的元素不在排序范围内)作为范围。
初始化大顶堆完成后,再调用堆排序函数进行排序。需要注意的是,堆中的最大值与堆末尾元素交换后,它就从堆中被删去了,所以在调用Heapify()函数时,堆的范围是原本堆末尾元素的编号-1,即 i - 1。否则,如果没有把堆末尾减1,堆中的最大值在堆的末尾,那么除堆顶元素外的两个子树之一不符合堆性质,也就不符合向下调整的条件。for循环结束后,堆排序就完成了。如果想要降序排序,把大顶堆转换成小顶堆即可。
桶排序:

代码中,countn[i]存储的值是元素 i 在数组中出现的次数。所以,在往result数组中添加元素时,要添加countn[i]次。代码实现的程序是升序排序,若想要降序排序,遍历countn数组时从后往前即可。
如果要排序的元素范围不确定,我们需要采用稍有不同的一种方法。
桶排序代码(非固定元素范围版):

在这段代码中,与固定元素范围版不一样的地方在于每个桶的编号和它存储的元素不同。最小值对应的是编号0,最小值+1对应的是编号1,也就是说,元素 i 对应的编号是它自身减去最小值。往桶里放入元素和输出元素时都要以这个规律为准。
以上的方法都只适用于对整数的排序。可以看出,为了排序定义的大部分桶都没有被使用。如果数据量不大但出现了极值,会造成严重的空间浪费。为了满足这两种需求,我们可以把排序范围分段,例如在 1 < x <= 100 范围内的元素放入同一个桶内, 100 < x <= 200 的元素放入一个桶内,以此类推。每一个桶内所包含的元素范围大小必须相等。在每一个桶内,再使用其他排序算法对元素进行排序,之后按顺序合并所有的桶即可。
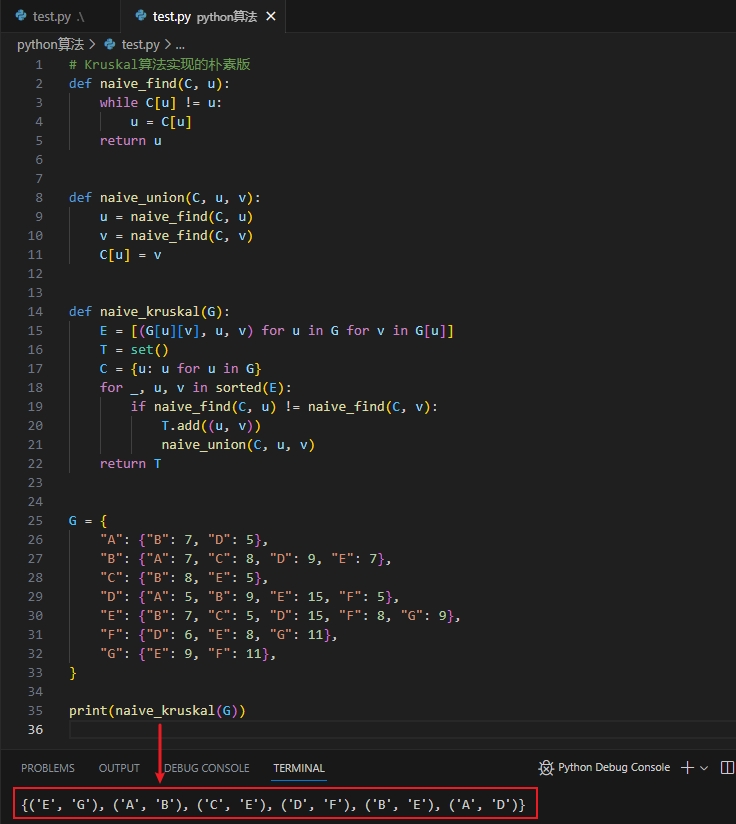
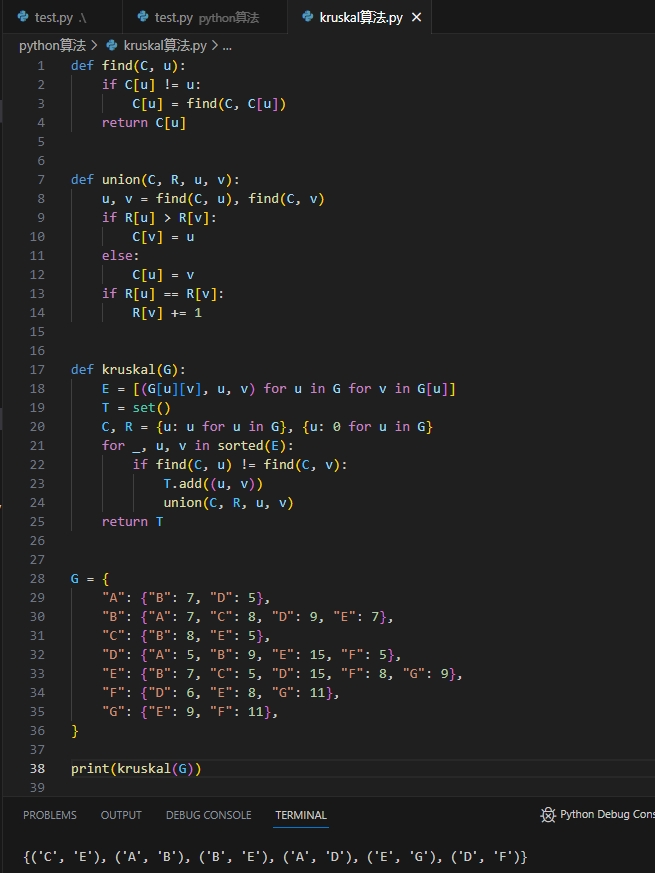
Kruskal算法实现的朴素版:

哈夫曼算法

在上述实现中,有几个细节值得注意。其中一个主要特性是它使用了堆结构(用的是heapq模块)。很显然,上述那种反复选取、合并两个最小无序列表项原本是一个平方级操作(线性级选取操作,乘以线性级迭代操作),但我们通过堆结构将其化简成一个线性对数级操作(对数级的选取和重新添加操作)。当然,这些树不能被直接添加到堆结构中。我们需要将其按发生概率排序。对此,我们可以直接添加元组“概率、树”,在概率(也就是权值)各不相同的情况下,就能进行操作。但当森林结构中有两棵树的发生概率相同时,该结构就必须找出较小的那棵树。这个问题的一种解决方案是在两者之间再增加一个字段,用该字段来区别所有对象。在这里,我们增加的是一个计数器。这样一来(由于有了概率、编号、树[frq, num, tree]结构的三重制约,概率相同的情况下,我们所赋予的编号一定不同,从而避免了树结构之间的直接比较操作。
当然,想要将这项技术运用到文本的压缩与解压缩中去的话,我们还需要进行一些预处理与后期加工。首先,我们需要对各字符出现的概率进行计数(例如运用collections模块中的Counter类)。然后,一旦我们构建出了自己的哈夫曼树,就必须能在其中找到所有字符的编码。可以用下面这段简单的遍历完成这个任务(它用二叉树结构的叶节点路径来编码每个字符,0表示左边,1表示右边。另外,由于这里所有的字符都落在叶节点上,所以解码相关文本时不会遇到任何歧义问题[因为我们确定每个编码都是从根节点到叶节点]。另外,对于“结构中任意有效代码不可能是其他代码的前缀”这种属性,我们在术语中称之为前缀码。)
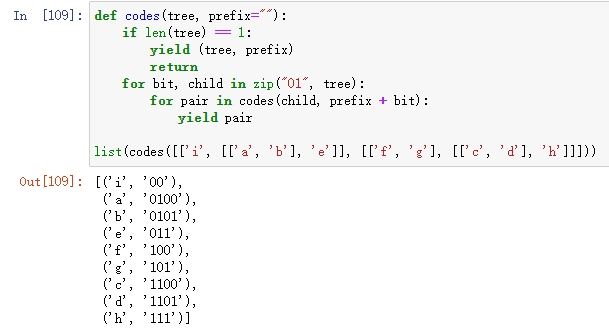
哈夫曼树问题可用于构建最优前缀码,以及在局部方案中通过归并最小树结构来构建一个适用于整体的贪心算法。
最小生成树问题,该结构可以用Kruskal算法(该算法会始终试图往树结构中添加最短边)或Prim算法(该算法会始终试图连接树结构与其最近点)来构建。
Prim算法
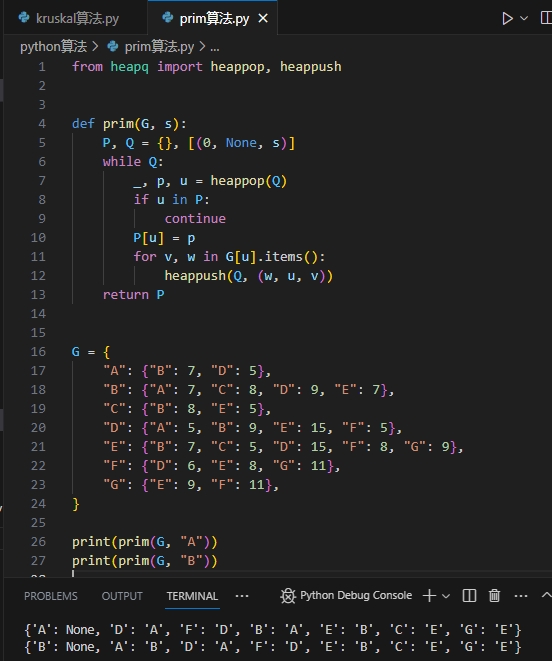
- 关于Prim算法的描述:


















 2570
2570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









