






Antutu auto - 闭源
安兔兔跑分的测试内容包括CPU、GPU、内存、存储等多个方面。具体来说,它通过运行一系列测试程序来评估这些关键组件的性能。例如,CPU测试会运行一些计算密集型任务来评估处理器的运算能力;GPU测试则会展示图形处理能力,包括渲染复杂场景和执行3D图形操作的能力。此外,内存和存储测试则评估设备的内存管理和存储读写速度。 随着版本的更新,安兔兔也在不断改进其测试内容和方式。例如,安兔兔V5.0引入了单线程测试以评估低功耗状态下的CPU性能,并且3D测试场景在光照、阴影、动画等方面进行了调整,以更准确地反映设备的实际性能。
Geekbench - 闭源
Geekbench是一款用于测试电脑处理器性能的软件。它可以测试CPU和GPU的性能,同时也可以测试内存速度和硬盘速度。Geekbench的测试原理是通过运行一系列的基准测试,这些测试涵盖了不同的计算类型,如浮点运算、整数运算、数据处理等,来评估硬件的性能。 测试结果通常以单位时间内完成的数据操作数量来表示,如每秒钟完成的万亿次浮点运算(TFLOPS),或每秒钟完成的百万次整数运算(MILLIONS INT OPS)。
GFXBench - 闭源
GFXBench是一个跨平台、跨API的3D基准测试软件,旨在精准反映设备的GPU图形性能。它支持所有行业标准和供应商特定的API,包括OpenGL, OpenGL ES, Vulkan, Metal, DirectX/Direct3D和DX12。GFXBench通过多个测试场景充分考察设备的图形表现,这些测试场景包括霸王龙(T-Rex)、曼哈顿3.0(Manhattan)、曼哈顿3.1(Manhattan)、赛车(Car Chase)等,分别对应OpenGL ES 2.0/3.0/3.1/3.1标准下的性能测试。这些测试压力越来越高,结果以平均帧率(FPS)衡量,能够全面评估设备的图形处理能力和游戏性能。 GFXBench的测试分为两个层次:高水平测试和低水平测试。高水平测试(如Car Chase, Manhattan 3.1, Manhattan)对类似游戏的内容进行密集的图形性能分析,模拟现实生活中的应用设计,结果更有意义。低水平测试(如Driver Overhead 2, ALU2, Tessellation, Texturing)则测量特定的图形性能方面,包括驱动程序开销、算术逻辑单元、镶嵌装饰、纹理填充等,这些测试能够更深入地分析GPU的特定性能指标。 通过GFXBench的测试,用户可以了解设备的图形处理能力、游戏性能以及GPU在不同负载下的表现,这对于评估手机或其他设备的图形渲染效率、优化游戏体验等方面具有重要意义。
Steam - 开源
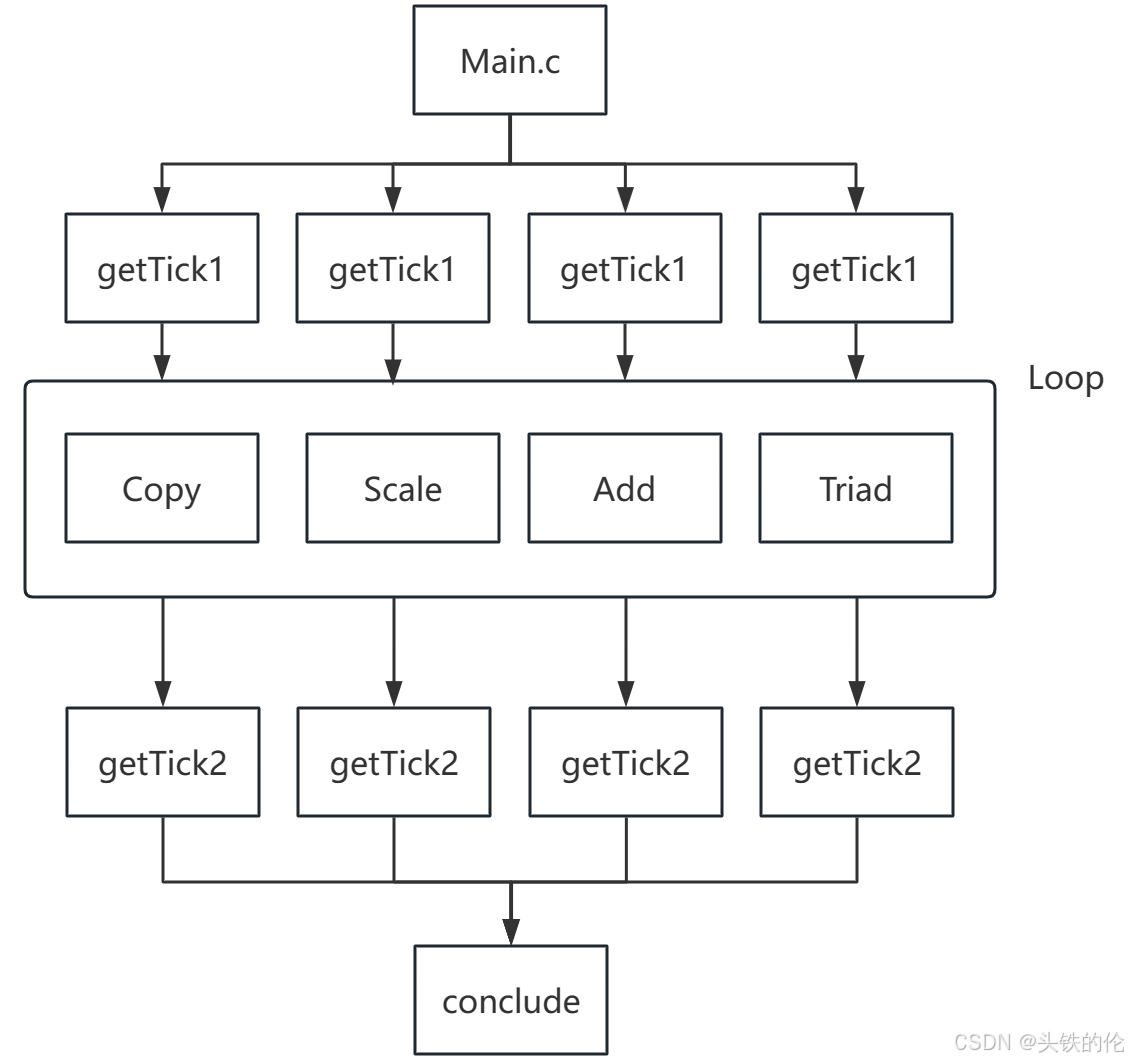
该程序对CPU的计算能力也有一定要求,即便是同arm平台,不同架构也会存在影响,stream对CPU内存带宽压力很大。stream测试得到的是可持续运行的内存带宽最大值,而并不是一般的硬件厂商提供的理论最大值,测试子项如下:
Copy - 1R1W
c[i] = a[i]
Scale - 1R1W
b[j] = scalar*c[j];
Add - 2R1W
c[j] = a[j]+b[j];
Triad - 2R1W
a[j] = b[j]+scalar*c[j];
Dhrystone - 开源
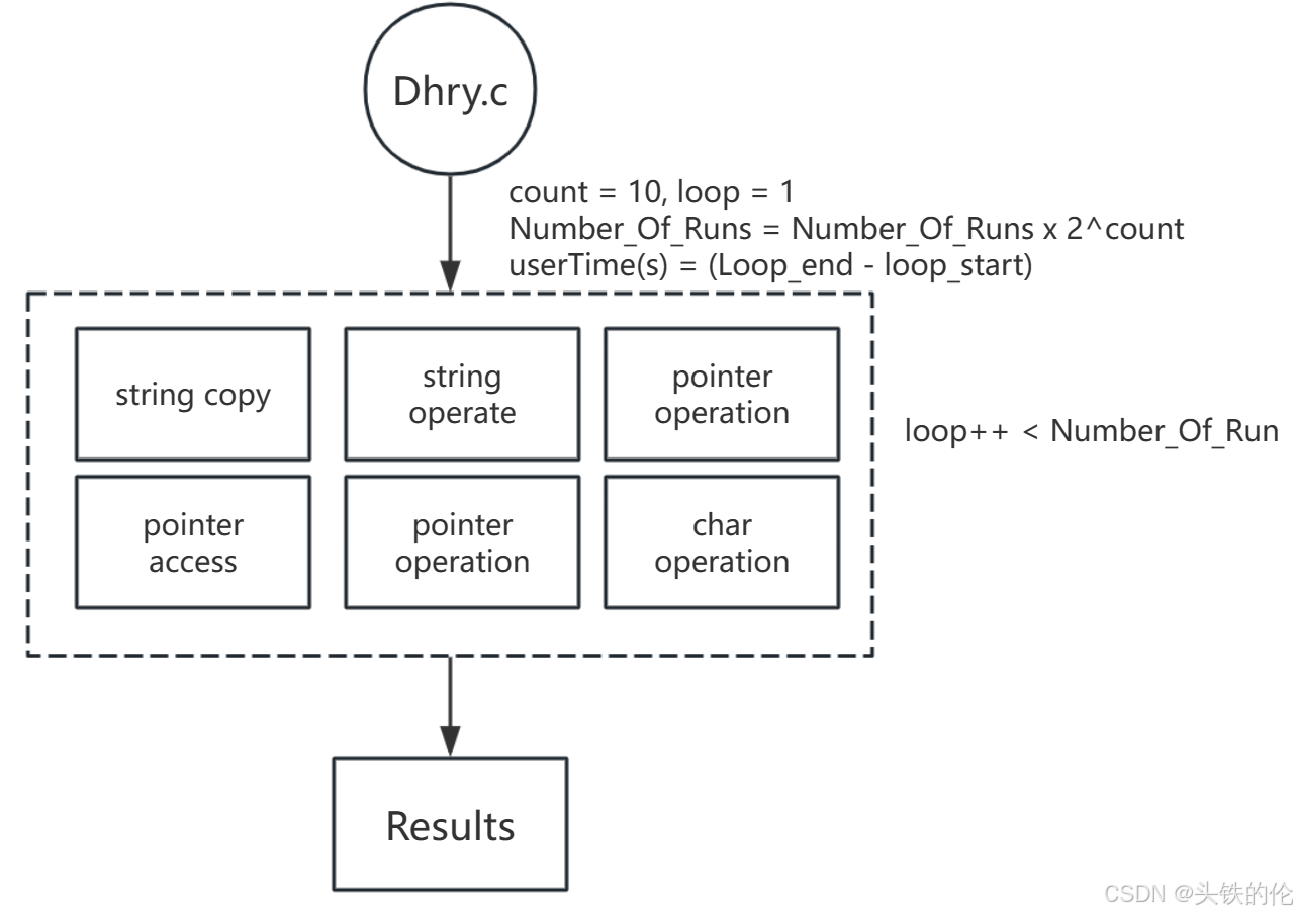
计算公式
MIPS = Number_Of_Runs / User_Time/1757
因为历史原因我们把在VAX-11/780机器上的测试结果1757 Dhrystones/s定义为1 DMIPS,因此在其他平台测试到的每秒Dhrystones数应除以1757,才是真正的DMIPS数值,故DMIPS其实表示的是一个相对值。
iozone - 开源
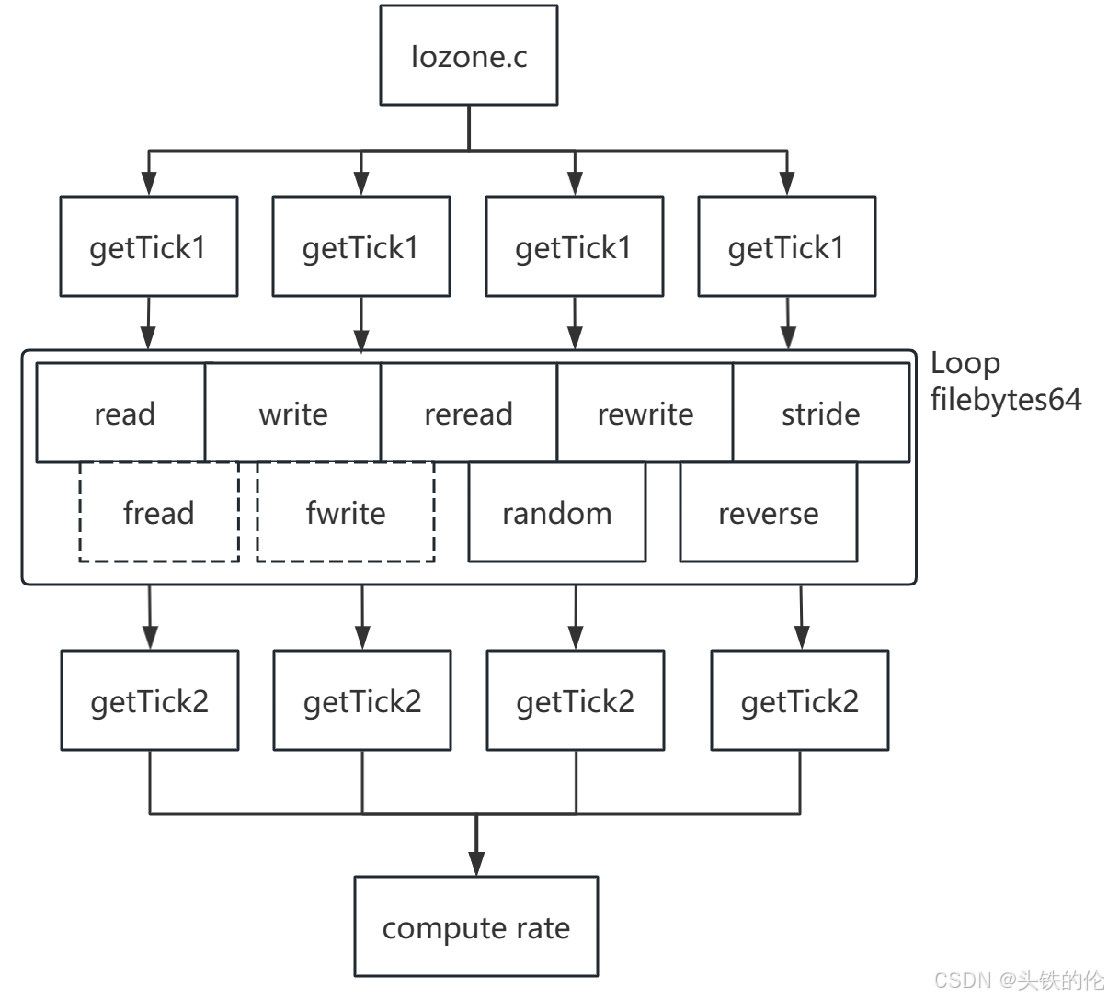
Iozone是用于测试平台IO表现的开源工具,主要测试用例如左图所示。 其中fread和fwrite为可选内容,根据代码来看,目前还有mix测试作为待开发项 rate计算方法如下:
Rate= filebytes64/(tick2 - tick1)-time_res - burst_sleep_time)
Gl2Mark - 开源

GLMark使用不同类型的UI测试 常规渲染,shadow渲染,desktop渲染,refract渲染等。
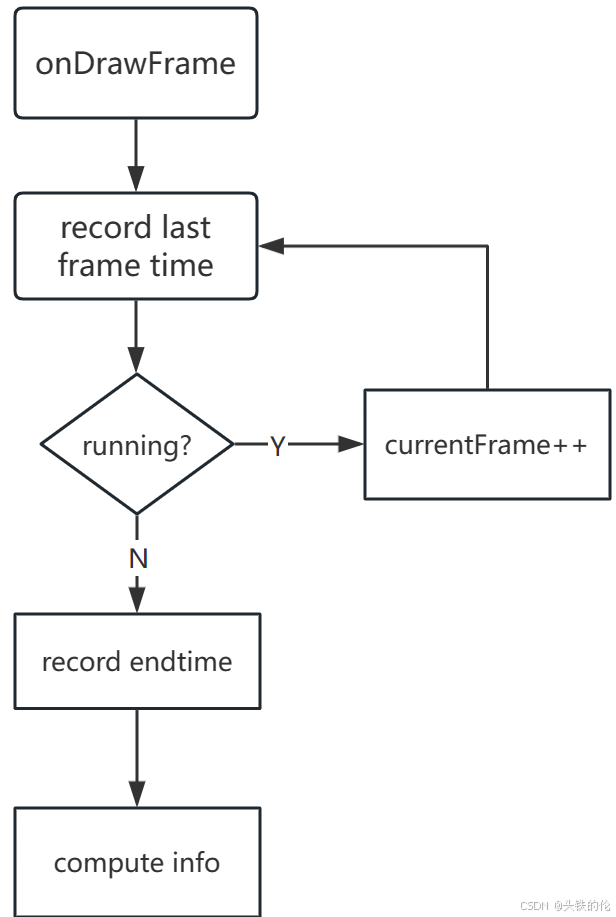
onDrawFrame :这里使用android提供的动画组件GLSurfaceView通过openGl检测帧率变化。GLSurfaceView后台存在UI thread,在可以绘制下一帧的时候会被调用给到前台进行绘制。
帧率计算 :FPS = currentFrame_/ (lastUpdate - start) Frametime = 1000.0 / FPS
抖动:暂无此功能
lat_mem_rd
测试内存读的能力,也在一定程度上反应设备内存管理、寻址速度等多方面表现。
此工具比较简单,就是通过成百上千次指针寻址操作来评估内存rd耗时,计算原理如下:
原理: getTime1 -> *pointer x 1000次 -> getTime2
mem_rd_latency = time2 - time1
lat_ctx
lat_ctx -P -N 10 -s 16 procs
-P 启动多少组进行并行测试
-N 重复测试次数
-S 读写数据大小
procs 单个组运行进程的数量以及管道数量。
lat_ctx 用于测试cpu上下文切换速度。整体结构如下
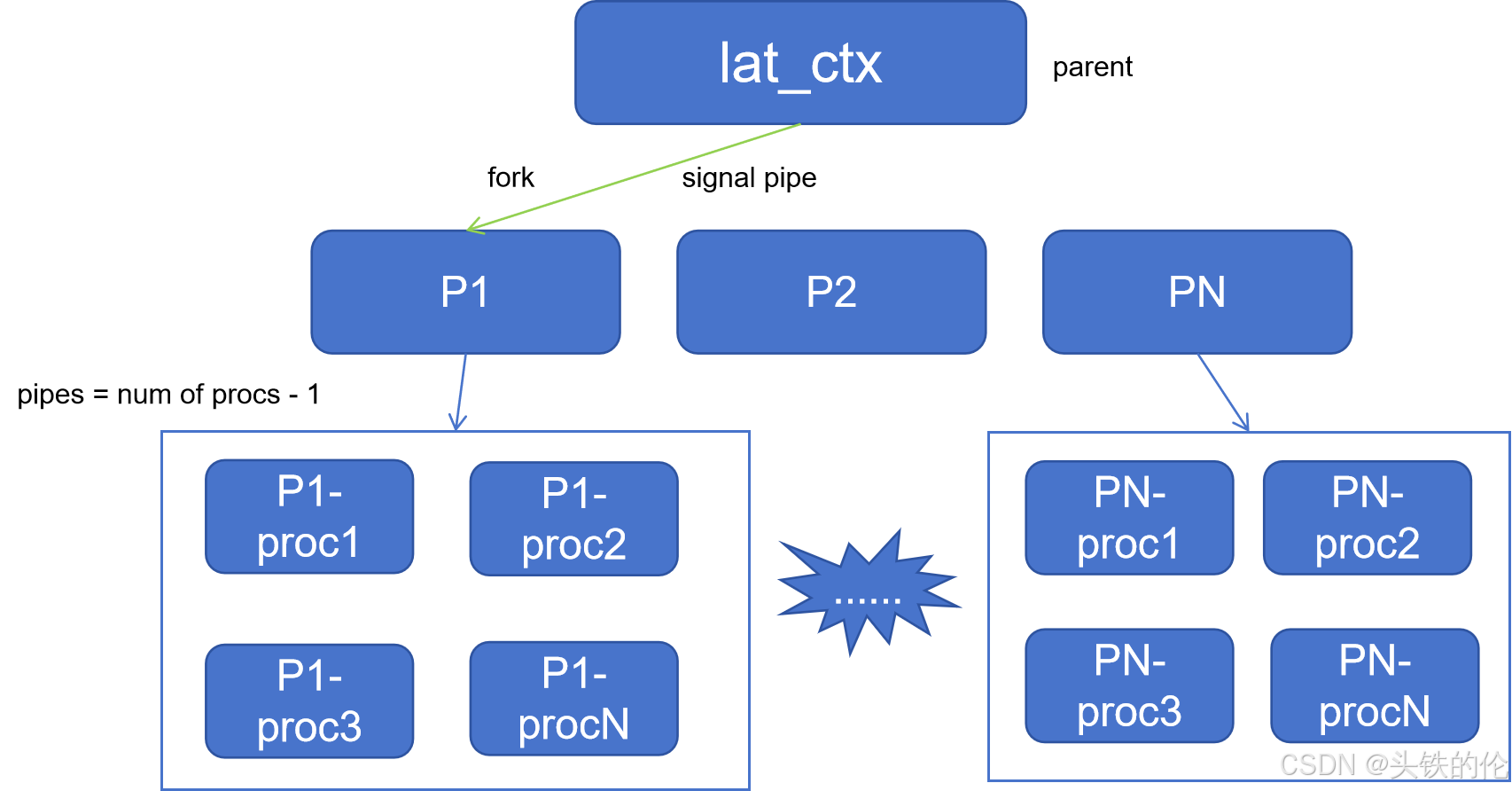
lmbench支持平行测试,常规测试中会fork一个子进程来进行测试,父进程则通过signal pipe来控制子进程行为。当-P大于1时,lmbench会fork多个子进程来并行测试。
主要通过进程1写管道数据(数据大小由-s决定)后进程2被调起接受数据,然后进程2回复respone给进程1.这样进程1可以根据数据ping-pong一次的时间确认进程2此次切换花费了多久。这里额外需要一个数据pipe的overhead,由于管道的传输是需要时间的,所以再开始测试前需要先评估此设备上管道的overhead大小。大体计算公式如下:
ctx_switch = Time-ping-pong - overhead-pipe

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









