






 本文详细记录了使用Keras进行文本分类时如何配置GPU环境,包括检查硬件、安装CUDA和cuDNN、使用Anaconda管理环境以及配置TensorFlow-GPU的过程。作者通过亲身体验,分享了在Windows11上安装CUDA12.0和cuDNN,解决protobuf版本问题,并最终成功运行TensorFlow-GPU的步骤。文章还提到了GPU训练的效率提升以及遇到的资源耗尽问题。
本文详细记录了使用Keras进行文本分类时如何配置GPU环境,包括检查硬件、安装CUDA和cuDNN、使用Anaconda管理环境以及配置TensorFlow-GPU的过程。作者通过亲身体验,分享了在Windows11上安装CUDA12.0和cuDNN,解决protobuf版本问题,并最终成功运行TensorFlow-GPU的步骤。文章还提到了GPU训练的效率提升以及遇到的资源耗尽问题。
系列文章目录–学年论文复盘
Keras使用GPU计算
提示:本科菜鸡的记录
文章目录
前言
提示:这里可以添加本文要记录的大概内容:
近期在写本学期的学年论文,其中有一项是做文本分类的实验,我的路线是对BERT进行微调,使用keras进行训练,训练的过程中我发现时间开销我真的吃不销,该电脑没有配置GPU,自己动手来配置一下,这篇文章以后可以给自己或者师弟师妹看。
一、查看硬件
1.首先你要确定使用电脑的显卡型号,我所使用的这台电脑是有独显的,在设备管理器查看即可,这一步是要衡量你的显卡算力。
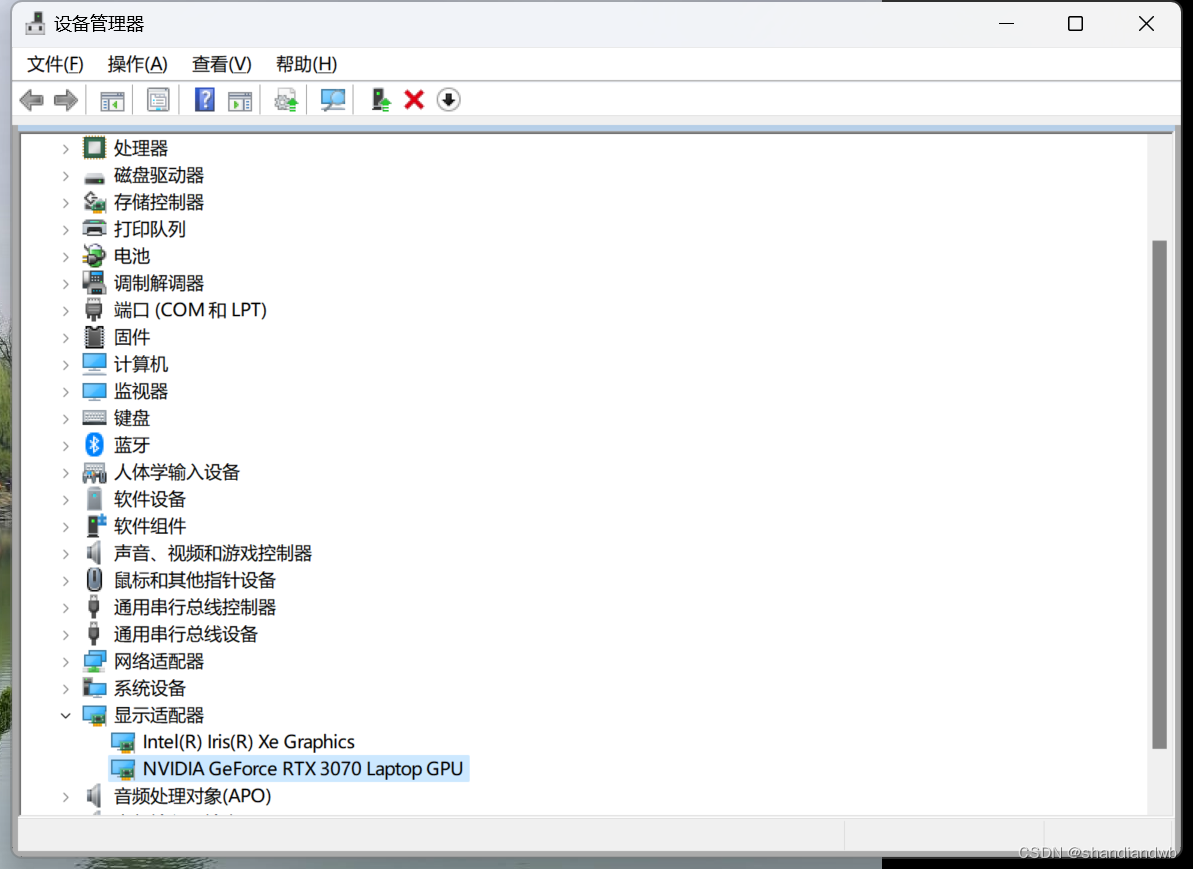
我的显卡是GeForce RTX 3070
2.去英伟达官网查看对应的算力:https://developer.nvidia.com/cuda-gpus
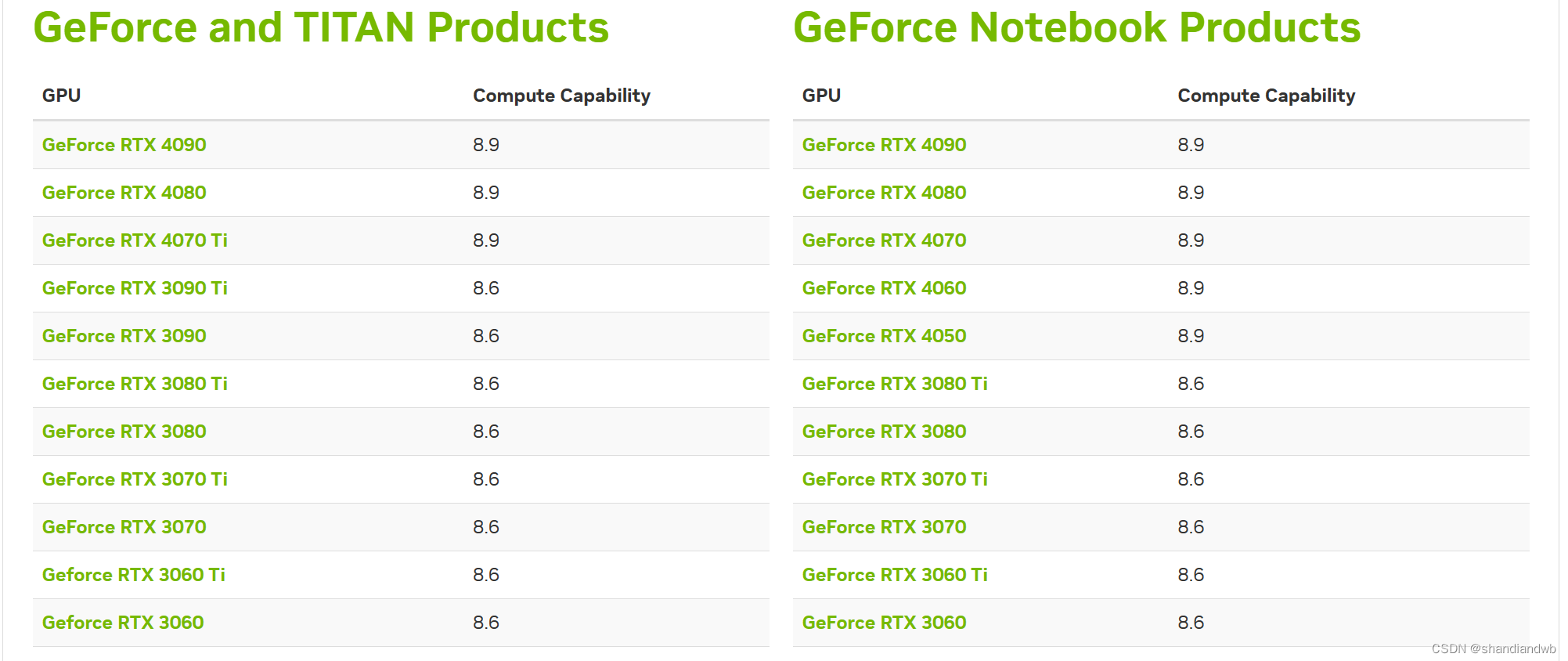 这台电脑的算力在8.6
这台电脑的算力在8.6
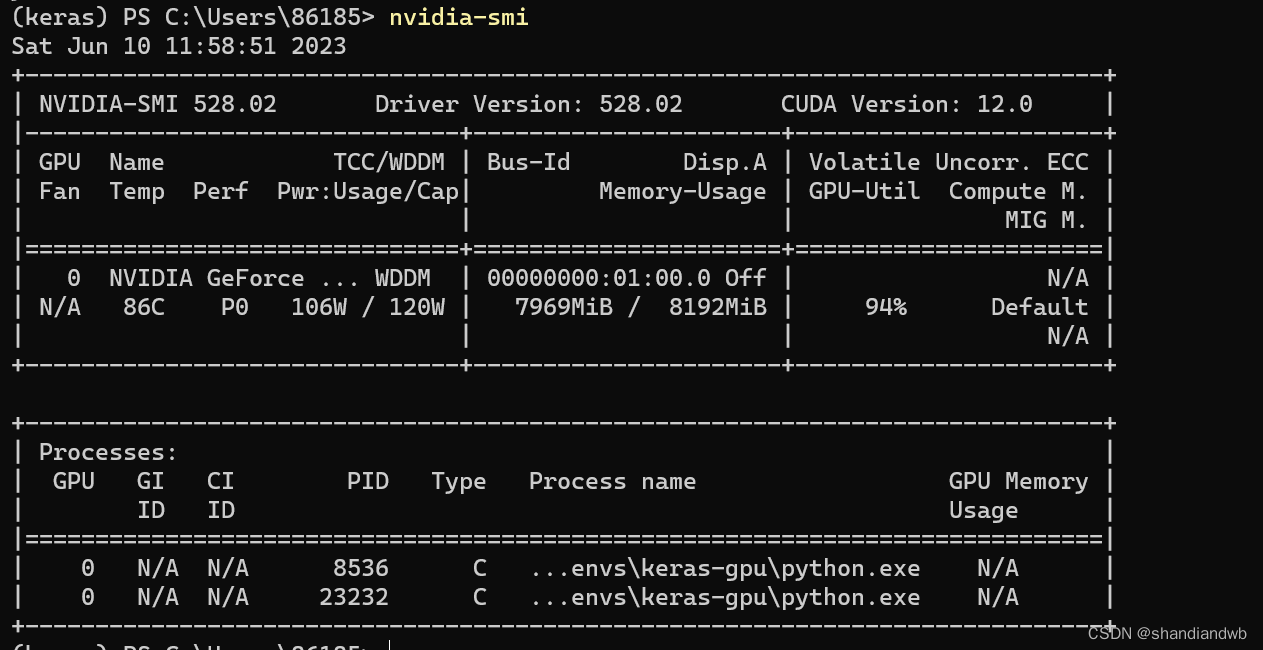
3.查看GPU的驱动版本,打开cmd。
输入
nvidia-smi
输出:
4.下载cuda和cuDNN前先检查一下自己有没有下载
cmd中输入
nvcc -V #返回不是系统命令则没有下载安装
或者去C:\Program Files下寻找NVIDIA GPU Computing Toolkit,没有这个文件也是没有安装
二、安装cuda和cuDNN
1.下载
-
下载的cuda必须低于你的驱动程序中的cuda version,例如我的cuda version是12.0那么我可以下载12.0以下的。
-
cuda下载地址: https://developer.nvidia.com/cuda-toolkit-archive cuda 12.0大概要3.4G
-
cuDNN下载地址:https://developer.nvidia.com/rdp/cudnn-archive cuDNN是cuda的扩展程序需要和cuda版本对应,英伟达如今对版本进行了对应标注,但也要注意。
另外这台电脑的os使用的是win11,可能以前发布的cuda不支持win11,这个也要注意。
一路狂按即可。
2. 完成后检查环境变量
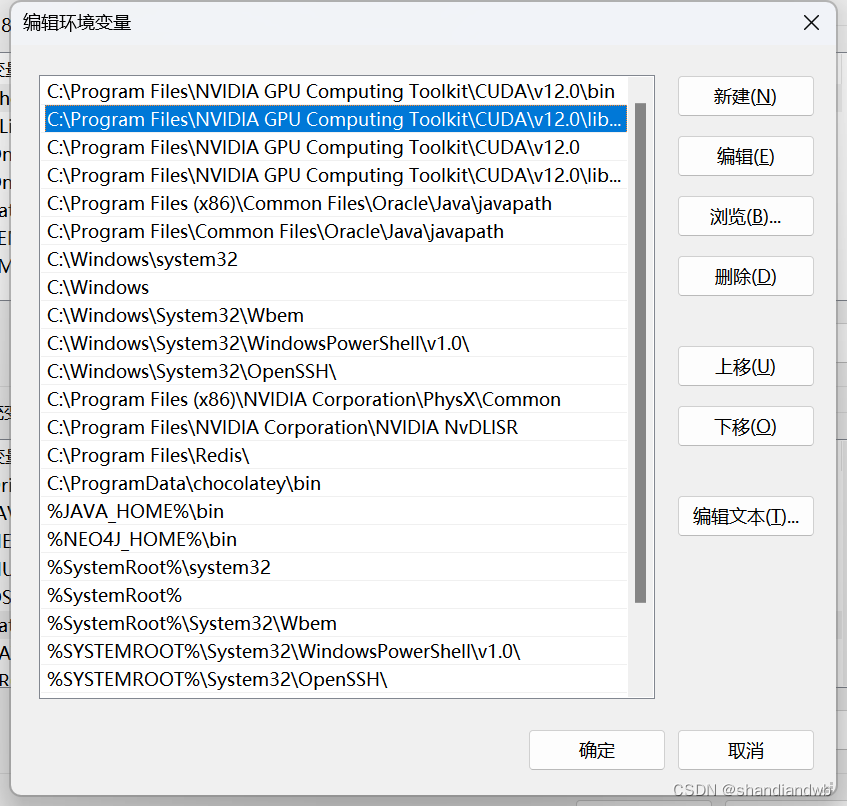
上面前四行出现则没有上面问题,没有就自己手动配置一下,这里的影响是配置过你可以在任何地方调用你的nvcc,如果没有就只能在这些路径下才能调用了。
具体path如下,需要根据版本微调
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\libnvvp
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\lib\x64
3. cuda和cuDNN下载完成后把cuDNN的文件迁移到cuda下
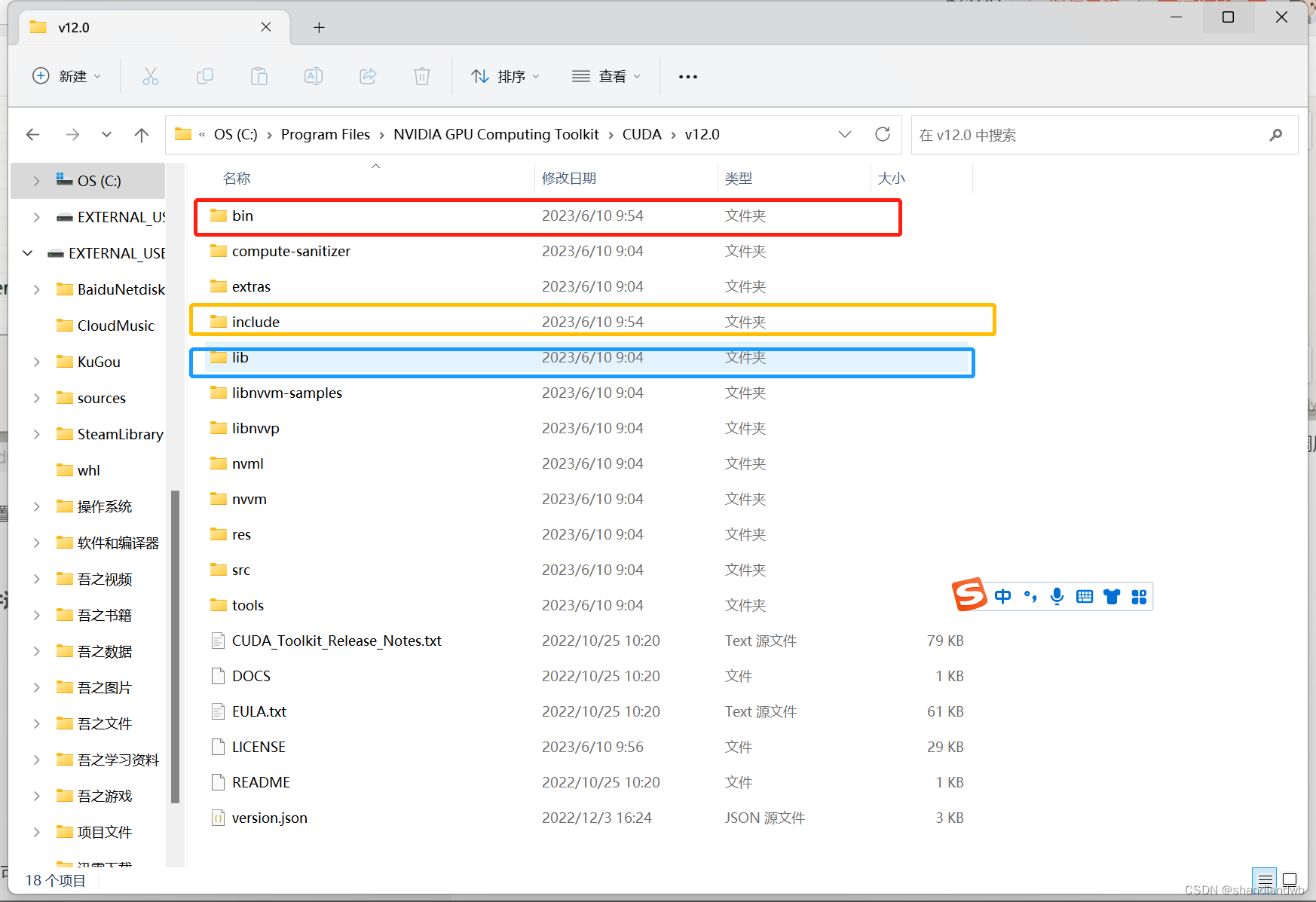
把cuDNN的文件夹下的文件复制到cuda的对应文件夹下。
注意!!!!是把例如cuDNN的bin文件夹下的全部文件复制到cuda的bin文件下
4. 检查是否安装成功
检查cuda安装
nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Mon_Oct_24_19:40:05_Pacific_Daylight_Time_2022
Cuda compilation tools, release 12.0, V12.0.76
Build cuda_12.0.r12.0/compiler.31968024_0
三、找一个包管理工具,例如Anaconda
Anaconda安装就常规安装就可以。
四、配置Tensorflow
1.Tensorflow必须在2.10版本及一下才支持windows
2.Tensorflow-gpu的版本号与Tensorflow版本号一直即可
3.独自建立一个环境,避免其他包冲突的麻烦
本文安装的包版本组合如下:
python 3.8.12 +tensorflow2.70+tensorflow-gpu+2.70 keras
1.安装tensorflow
(keras-gpu) pip install tensorflow-gpu==2.7.0 -i https://pypi.mirrors.ustc.edu.cn/simple
如果没有报错说明安装成功,虽然如此,但清华源的这个镜像包出现了一个问题
python
import tensorflow as tf #终端进python导入tensorflow
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "D:\WorkSoftware\Install\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\__init__.py", line 41, in <module>
from tensorflow.python.tools import module_util as _module_util
File "D:\WorkSoftware\Install\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\__init__.py", line 41, in <module>
from tensorflow.python.eager import context
File "D:\WorkSoftware\Install\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\eager\context.py", line 33, in <module>
from tensorflow.core.framework import function_pb2
File "D:\WorkSoftware\Install\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\core\framework\function_pb2.py", line 16, in <module>
from tensorflow.core.framework import attr_value_pb2 as tensorflow_dot_core_dot_framework_dot_attr__value__pb2
File "D:\WorkSoftware\Install\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\core\framework\attr_value_pb2.py", line 16, in <module>
from tensorflow.core.framework import tensor_pb2 as tensorflow_dot_core_dot_framework_dot_tensor__pb2
File "D:\WorkSoftware\Install\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\core\framework\tensor_pb2.py", line 16, in <module>
from tensorflow.core.framework import resource_handle_pb2 as tensorflow_dot_core_dot_framework_dot_resource__handle__pb2
File "D:\WorkSoftware\Install\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\core\framework\resource_handle_pb2.py", line 16, in <module>
from tensorflow.core.framework import tensor_shape_pb2 as tensorflow_dot_core_dot_framework_dot_tensor__shape__pb2
File "D:\WorkSoftware\Install\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\core\framework\tensor_shape_pb2.py", line 36, in <module>
_descriptor.FieldDescriptor(
File "D:\WorkSoftware\Install\Anaconda3\envs\tensorflow\lib\site-packages\google\protobuf\descriptor.py", line 561, in __new__
_message.Message._CheckCalledFromGeneratedFile()
TypeError: Descriptors cannot not be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.If you cannot immediately regenerate your protos, some other possible workarounds are:
1. Downgrade the protobuf package to 3.20.x or lower.
2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
More information: https://developers.google.com/protocol-buffers/docs/news/2022-05-06#python-updates
原因是是protobuf包没有装上或者下的版本和你的tensorflow-board不对应
pip install protobuf #如果还有问题指定版本下载
然后重新进入python 环境,查看tensorflow的版本信息, 输入命令:
import tensorflow as tf
tf.__version__
输出:显示2.7.0
2.再测试如下代码
import tensorflow as tf
print(tf.__version__)
print(tf.test.gpu_device_name())
print(tf.config.experimental.set_visible_devices)
print('GPU:', tf.config.list_physical_devices('GPU'))
print('CPU:', tf.config.list_physical_devices(device_type='CPU'))
print(tf.config.list_physical_devices('GPU'))
print(tf.test.is_gpu_available())
# 输出可用的GPU数量
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
# 查询GPU设备
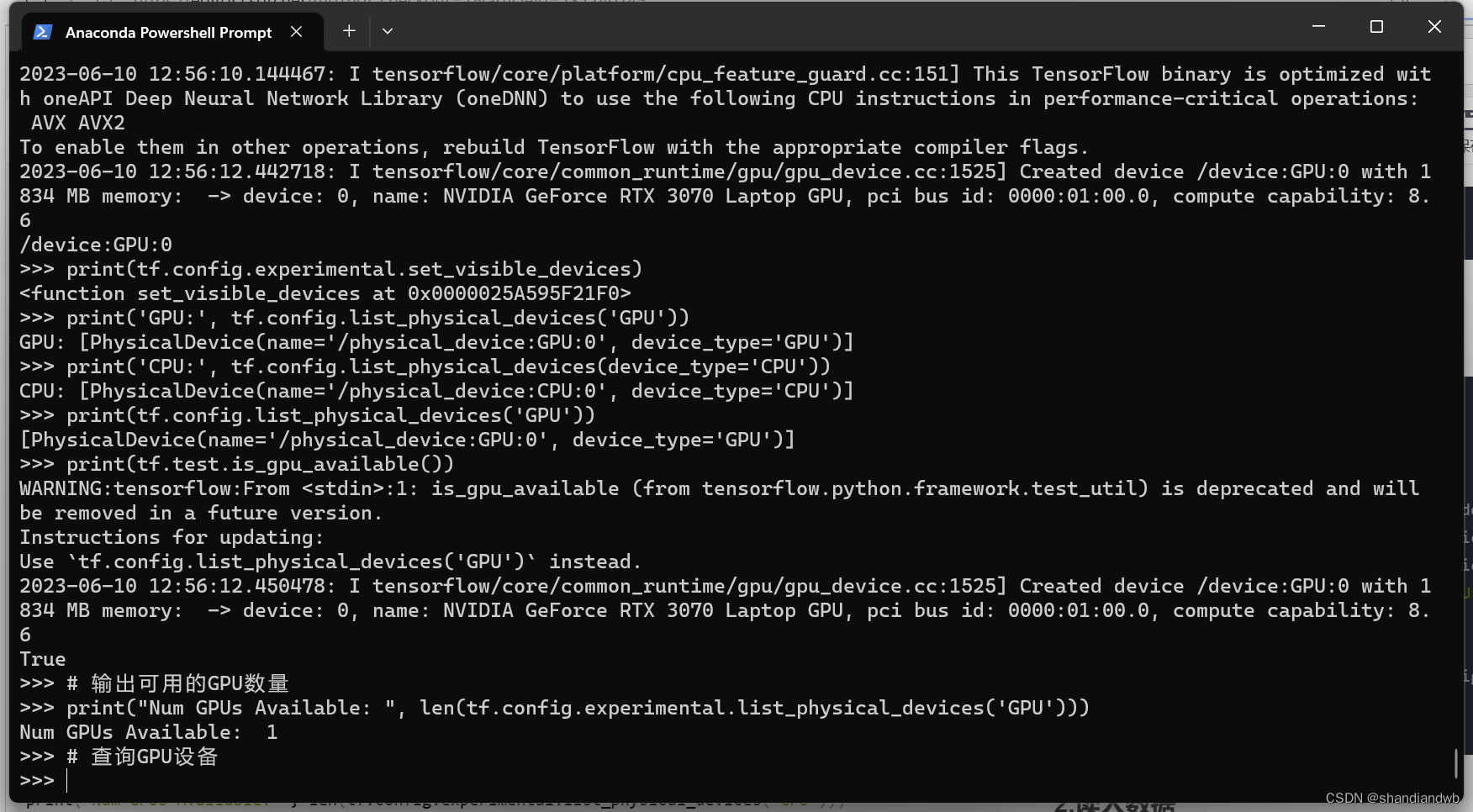
结果中返回过True,显示你的GPU数量则tensorflow-gpu配置成功
五、keras使用tensorflow-gpu计算
pip install keras == 2.7.0
keras集成度相当高,使用起来和简单,在model.fit前加上一个设置即可,例如:
with tf.device("/gpu:0"): #使用cpu用/cpu:0,这里的数字是你的设备编号,显然我只有一个gpu
model.fit_generator(
train_D.__iter__(),
steps_per_epoch=len(train_D),
epochs=3,
validation_data=test_D.__iter__(),
validation_steps=len(test_D)
)
经过我测试GPU做AI计算的速度比CPU大约快80倍左右。但是还是有其他的缺陷的
ResourceExhaustedError: OOM when allocating tensor with shape[1024,728,1,1] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[node model/block13_sepconv2/separable_conv2d (defined at <ipython-input-41-425b3e9b7078>:11) ]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
[Op:__inference_train_function_41706]
Function call stack:
train_function
cpu训练不会溢出,但是gpu溢出,这个时候就要减少bach_size的数量或者是少喂数据了,不过也可以换一个显存更高的的gpu。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









