






前言
自 2016 年诞生以来,YOLO 系列从一个简单而有效的目标检测框架,逐步演变为一个在速度与精度之间实现高度平衡的复杂模型。多年来,每一代版本都在特征提取、主干网络架构、注意力机制以及优化技术方面引入了显著的改进。
- YOLOv1 至 YOLOv5 专注于优化基于卷积神经网络(CNN)的架构,提升检测效率。
- YOLOv6 至 YOLOv9 集成了先进的训练策略与轻量化结构,增强了部署的灵活性。
- YOLOv10 引入了基于 Transformer 的模型,并消除了非极大值抑制(NMS)的需求,进一步优化了实时检测性能。
- YOLOv11 和 YOLOv12 在前述改进的基础上,融合了创新方法论,推动了效率与精度的极限。
YOLOv12

YOLOv12 模型由 Yunjie Tian(纽约州立大学布法罗分校)、Ye Qixiang(中国科学院大学)和 David Doermann(纽约州立大学布法罗分校)在论文《YOLOv12: Attention-Centric Real-Time Object Detectors》中首次提出。
代码地址:[GitHub - sunsmarterjie/yolov12: YOLOv12: Attention-Centric Real-Time Object Detectors](https://github.com/sunsmarterjie/yolov12)
长期以来,提升 YOLO 框架的网络架构一直是关键任务,但改进主要集中于基于卷积神经网络(CNN)的方法,尽管注意力机制在建模能力上已被证明具有优越性。原因在于,基于注意力的模型在速度上无法与基于 CNN 的模型相媲美。本文提出了一种以注意力为中心的 YOLO 框架,即 YOLOv12,它在保持与先前基于 CNN 模型相当速度的同时,充分利用了注意力机制的性能优势。
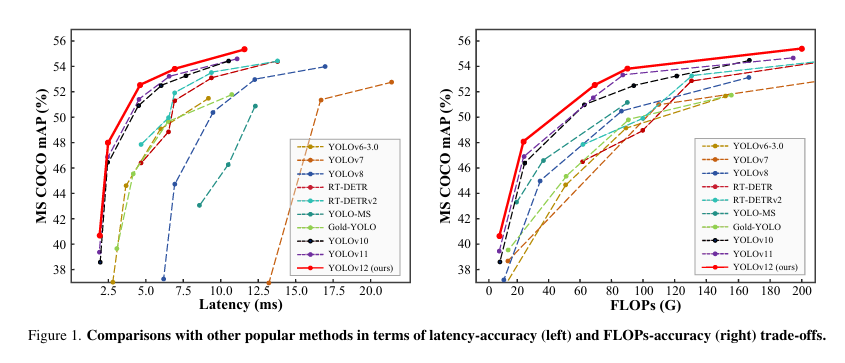
YOLOv12 在精度上超越了所有流行的实时目标检测器,同时保持了具有竞争力的速度。例如,YOLOv12-N 在 T4 GPU 上实现了 40.6% 的平均精度均值(mAP),推理延迟仅为 1.64 毫秒,分别比先进的 YOLOv10-N 和 YOLOv11-N 高出 2.1% 和 1.2% 的 mAP,且速度相当。这一优势也延伸到其他模型规模。
YOLOv12 还超越了改进 DETR 的端到端实时检测器,例如 RT-DETR 和 RT-DETRv2:YOLOv12-S 击败了 RT-DETR-R18 和 RT-DETRv2-R18,运行速度快 42%,仅使用 36% 的计算量和 45% 的参数。 。
YOLOv12 的独特之处在于将注意力机制融入其架构,摒弃了传统的卷积神经网络(CNN)方法。这种以注意力为核心的设计使模型能够聚焦于图像中的关键区域,从而提升特征提取效率和检测精度。其核心架构优化包括改进的主干网络 R-ELAN、7x7 可分离卷积以及基于 FlashAttention 的区域注意力机制,这些特性共同促成了其卓越的性能表现。
YOLOv12 的革新之处
在计算机视觉领域,由于注意力机制通常面临效率低下的问题,传统目标检测架构多依赖卷积神经网络(CNN)。然而,CNN 在处理二次计算复杂性和内存访问效率低下时存在局限。因此,在 YOLO 框架中,基于 CNN 的模型往往在高推理速度至关重要的场景中优于基于注意力的系统。
区域注意力模块 ( A² )
YOLOv12 引入了一种简洁高效的区域注意力模块(Area Attention Module, A2)。该模块通过将特征图分割为多个区域,在保留大感受野的同时显著降低了传统注意力机制的计算复杂度。这一优化设计使模型能够在保持关键视觉信息的基础上提升速度与效率。
残差高效层聚合网络 (R-ELAN)
YOLOv12 采用残差高效层聚合网络(Residual Efficient Layer Aggregation Network, R-ELAN)来应对注意力机制引入的优化难题。相较于此前的 ELAN 架构,R-ELAN 的改进包括:
- 块级残差连接与缩放技术:通过引入残差结构和容量调整策略,确保训练过程的稳定性。
- 优化的特征聚合方法:重新设计特征融合方式,提升模型性能与计算效率。
架构优化亮点
-
FlashAttention 集成:通过引入 FlashAttention 技术,YOLOv12 有效缓解了注意力机制的内存访问瓶颈,优化了内存操作并加速推理。
-
移除位置编码:YOLOv12 剔除了位置编码设计,简化了模型结构,使其更加高效且简洁,同时不影响性能。
-
调整 MLP 扩展比率:将多层感知器(MLP)的扩展比率从 4 降至 1.2,优化注意力机制与前馈网络间的计算负载均衡,提升整体效率。
-
减少块深度:通过降低架构中堆叠块的数量,简化优化流程并显著提高推理速度。
-
高效卷积运算:YOLOv12 广泛采用卷积操作,充分发挥其计算效率优势,进一步提升性能并降低延迟。
YOLOv12 的技术架构
# YOLOv12 🚀, AGPL-3.0 license
# YOLOv12 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov12n.yaml' will call yolov12.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 465 layers, 2,603,056 parameters, 2,603,040 gradients, 6.7 GFLOPs
s: [0.50, 0.50, 1024] # summary: 465 layers, 9,285,632 parameters, 9,285,616 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 501 layers, 20,201,216 parameters, 20,201,200 gradients, 68.1 GFLOPs
l: [1.00, 1.00, 512] # summary: 831 layers, 26,454,880 parameters, 26,454,864 gradients, 89.7 GFLOPs
x: [1.00, 1.50, 512] # summary: 831 layers, 59,216,928 parameters, 59,216,912 gradients, 200.3 GFLOPs
# YOLO12n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 4, A2C2f, [512, True, 4]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 4, A2C2f, [1024, True, 1]] # 8
# YOLO12n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, A2C2f, [512, False, -1]] # 11
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, A2C2f, [256, False, -1]] # 14
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P4
- [-1, 2, A2C2f, [512, False, -1]] # 17
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 8], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 20 (P5/32-large)
- [[14, 17, 20], 1, Detect, [nc]] # Detect(P3, P4, P5)
区域注意力模块

在计算机视觉领域,为了应对传统注意力机制的高计算成本,YOLOv12 引入了局部注意力机制,如 Shift Window、Criss-Cross 和 Axial Attention。这些方法通过将全局注意力转换为局部注意力,降低了计算复杂度。然而,由于感受野的缩小,它们在推理速度和检测精度上仍存在一定局限。
YOLOv12 提出了一种简洁高效的区域注意力模块(Area Attention Module, A2)。该模块将分辨率为 (H,W)(H,W) 的特征图分割为 LL 个大小为 (H/L,W) 或 (H,W/L) 的子区域。与显式窗口划分不同,A2 模块通过简单的 reshape 操作实现分区。
这一设计将感受野缩减至原始大小的 1/41/4,但相较于其他局部注意力机制,仍能维持较大的感受野范围。同时,A2 模块将传统注意力机制的计算复杂度从 (n²hd)/2 降低至 (2n²hd),显著提升了计算效率,且未对检测精度造成明显影响。
残差高效层聚合网络 (R-ELAN)
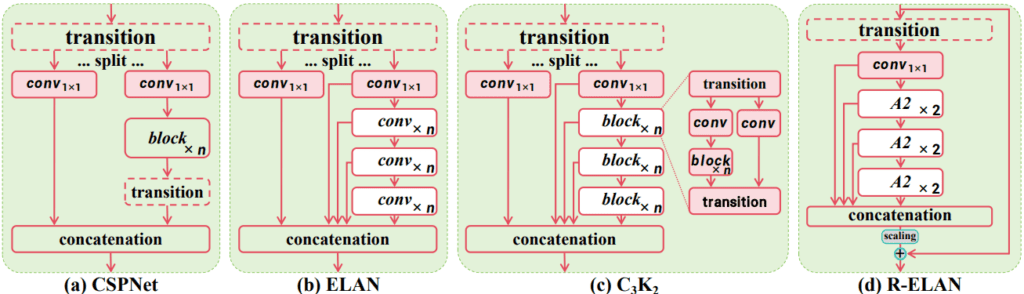
ELAN
在早期的 YOLO 模型中使用了高效的层聚合网络 (ELAN) 来改进特征聚合。
ELAN 的工作原理:
- 拆分 1×1 卷积层的输出。
- 通过多个模块处理这些拆分。
- 在应用另一个 1×1 卷积以对齐最终维度之前连接输出。
ELAN 的问题:
- 梯度阻塞:由于缺少从输入到输出的残余连接,导致不稳定。
- 优化挑战:注意力机制和架构可能导致收敛问题,即使使用 Adam 或 AdamW 优化器,L 和 X 尺度模型也无法收敛或保持不稳定。
R-ELAN
-
剩余连接:引入从输入到输出的残差快捷键,并带有缩放因子(默认为 0.01)以提高稳定性。
-
层缩放类比: 类似于 Deep Vision Transformer 中使用的层缩放,但避免了将层缩放应用于每个区域注意力模块而导致的速度减慢。
YOLOv12 安装指南
YOLOv12 不支持仅 CPU 的环境,主要是因为它需要 FlashAttention,而 FlashAttention 不支持仅 CPU 的环境,因此安装需要 CUDA。请确保在你的系统上正确配置了 CUDA。
-
克隆仓库
git clone https://github.com/sunsmarterjie/yolov12.git cd yolov12 -
验证 CUDA 版本:确认系统的 CUDA 版本兼容。
nvcc -V
-
安装 PyTorch 和 TorchVision
pip install torch==2.2.2 torchvision==0.17.2 --index-url https://download.pytorch.org/whl/cu121 -
安装其他依赖项
# 安装 flash-attn v2.7.3 并使用禁用构建隔离的标志。它在注意力操作期间提高了内存效率,但需要 CUDA。 pip install flash-attn==2.7.3 --no-build-isolation # 安装 requirements.txt 文件中列出的所有其他必要依赖项。 pip install -r requirements.txt -
训练模型
from ultralytics import YOLO model = YOLO('yolov12s.yaml') results = model.train(data=f'/path/to/dataset/data.yaml', epochs=100)
YOLOv11 与 YOLOv12比较
| 特性 | YOLOv11 | YOLOv12 |
|---|---|---|
| 主干网络 | 基于 Transformer | 优化的混合架构,集成区域注意力 (Area Attention) |
| 检测头 | 动态自适应 | 增强型 FlashAttention 处理 |
| 训练方法 | 无非极大值抑制 (NMS-free) 训练 | 高效标签分配技术 |
| 优化技术 | 部分自注意力 (Partial Self-Attention) | 残差高效层聚合网络 (R-ELAN) 配合内存优化 |
| 平均精度均值 (mAP) | 61.5% | 40.6% |
| 推理速度 | 60 FPS | 1.64 毫秒延迟 (T4 GPU) |
| 计算效率 | 高 | 更高 |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











