







一、原理
1.1链式法则
引用
2个事件同时发生的概率:
P(a, b) = P(a | b) * P(b)
其中:P(a, b)表示 a和b事件同时发生的概率, P(a | b)是一个条件概率,表示在b事件发生的条件下,a发生的概率
3个事件的概率链式调用:
P(a, b, c) = P(a | b, c) * P(b, c)
= P(a | b, c) * P(b | c) * P©
推广到N个事件,概率链式法则长这样:
P(X1, X2, … Xn) = P(X1 | X2, X3 … Xn) * P(X2 | X3, X4 … Xn) … P(Xn-1 | Xn) * P(Xn)
那这个链式法则有什么用处呢?
要知道链式法则的用处,先要了解一下什么叫事件相互独立。事件相互独立就是:一个事件的发生与否,不会影响另外一个事件的发生。
当a和b两个事件互相独立时,有:
P(a | b) = P(a)
推广到3个事件就有下面这个公式:
P(a | b, c) = P(a | c)
其中:P(a | b, c)表示在b和c事件都发生的情况下,a事件发生的概率
既然a与b相互独立,那b就不是a是否发生的条件,a就只与c有关
1.2 re.split
二、代码
2.1 数据集
引用
对于将数据集转换为图片的代码参考了这位大佬
代码如下:
# 导入包
import struct
import numpy as np
from PIL import Image
class MnistParser:
# 加载图像
def load_image(self, file_path):
# 读取二进制数据
binary = open(file_path, 'rb').read()
# 读取头文件
fmt_head = '>iiii'
offset = 0
# 读取头文件
magic_number, images_number, rows_number, columns_number = struct.unpack_from(fmt_head, binary, offset)
# 打印头文件信息
print('图片数量:%d,图片行数:%d,图片列数:%d' % (images_number, rows_number, columns_number))
# 处理数据
image_size = rows_number * columns_number
fmt_data = '>' + str(image_size) + 'B'
offset = offset + struct.calcsize(fmt_head)
# 读取数据
images = np.empty((images_number, rows_number, columns_number))
for i in range(images_number):
images[i] = np.array(struct.unpack_from(fmt_data, binary, offset)).reshape((rows_number, columns_number))
offset = offset + struct.calcsize(fmt_data)
# 每1万张打印一次信息
if (i + 1) % 10000 == 0:
print('> 已读取:%d张图片' % (i + 1))
# 返回数据
return images_number, rows_number, columns_number, images
# 加载标签
def load_labels(self, file_path):
# 读取数据
binary = open(file_path, 'rb').read()
# 读取头文件
fmt_head = '>ii'
offset = 0
# 读取头文件
magic_number, items_number = struct.unpack_from(fmt_head, binary, offset)
# 打印头文件信息
print('标签数:%d' % (items_number))
# 处理数据
fmt_data = '>B'
offset = offset + struct.calcsize(fmt_head)
# 读取数据
labels = np.empty((items_number))
for i in range(items_number):
labels[i] = struct.unpack_from(fmt_data, binary, offset)[0]
offset = offset + struct.calcsize(fmt_data)
# 每1万张打印一次信息
if (i + 1) % 10000 == 0:
print('> 已读取:%d个标签' % (i + 1))
# 返回数据
return items_number, labels
# 图片可视化
def visualaztion(self, images, labels, path):
d = {0: 0, 1: 0, 2: 0, 3: 0, 4: 0, 5: 0, 6: 0, 7: 0, 8: 0, 9: 0}
for i in range(images.__len__()):
im = Image.fromarray(np.uint8(images[i]))
im.save(path + "%d_%d.png" % (labels[i], d[labels[i]]))
d[labels[i]] += 1
# im.show()
if (i + 1) % 10000 == 0:
print('> 已保存:%d个图片' % (i + 1))
# 保存为图片格式
def change_and_save():
mnist = MnistParser()
trainImageFile = './data/train-images.idx3-ubyte'
_, _, _, images = mnist.load_image(trainImageFile)
trainLabelFile = './data/train-labels.idx1-ubyte'
_, labels = mnist.load_labels(trainLabelFile)
mnist.visualaztion(images, labels, "./images/train/")
testImageFile = './data/train-images.idx3-ubyte'
_, _, _, images = mnist.load_image(testImageFile)
testLabelFile = './data/train-labels.idx1-ubyte'
_, labels = mnist.load_labels(testLabelFile)
mnist.visualaztion(images, labels, "./images/test/")
# 测试
if __name__ == '__main__':
change_and_save()
2.2 代码
三、错误
3.1image change中出现的问题
3.1.1 ModuleNotFoundError: No module named 'numpy
引用
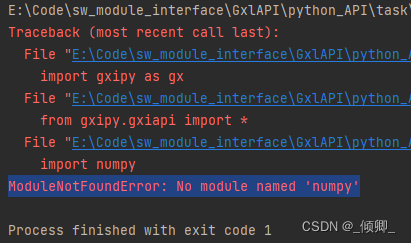
解决方案:打开PyCharm软件:File->Settings->Project->Python Interpreter->Add Interpreter->Add Local Interpreter->Virtualenv Enviroment -> Inherit global site-packages->OK ->
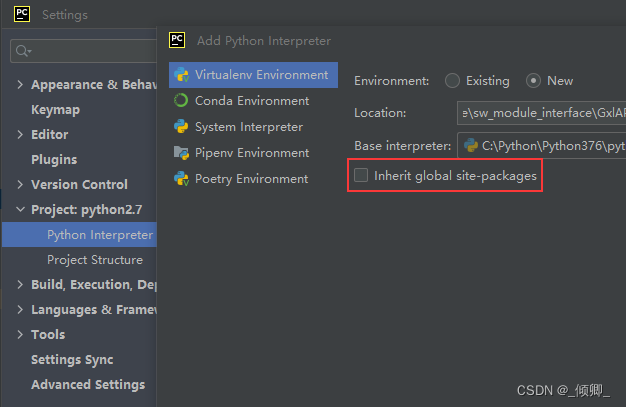
3.1.2 ImportError: DLL load failed while importing _multiarray_umath: 找不到指定的模块。
3.1中的问题按照上述步骤解决后,又出现了新的问题:
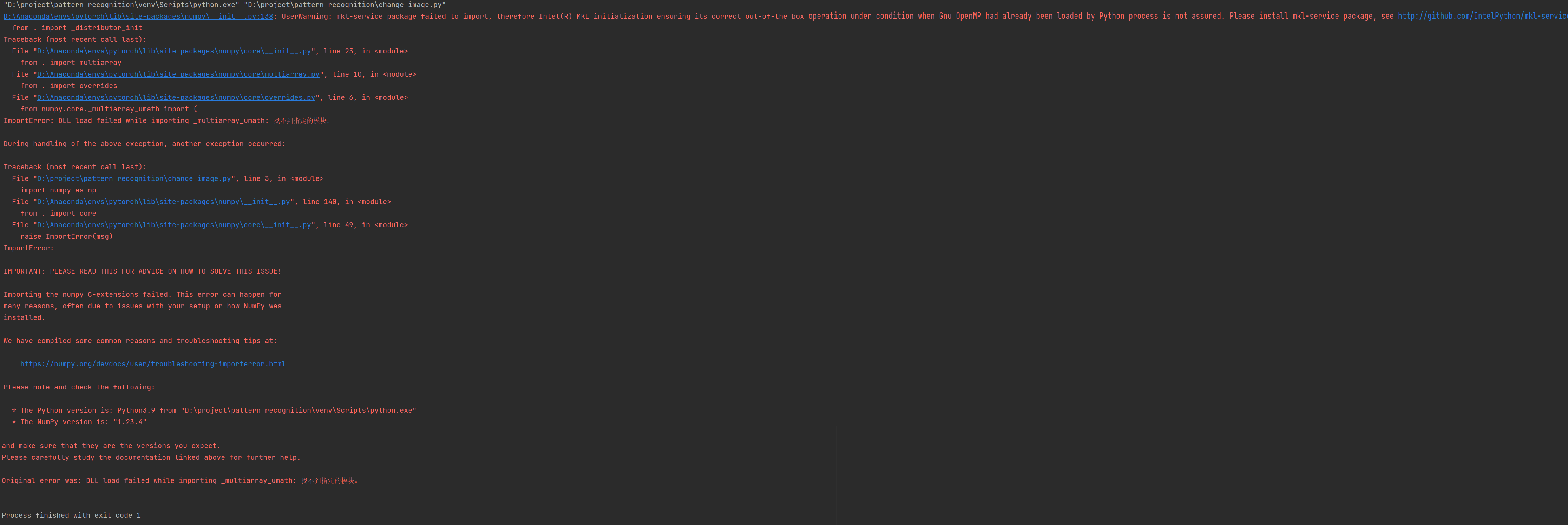
引用
按照这位大佬的描述,从下往上找到第一个不用“.”引入的库:
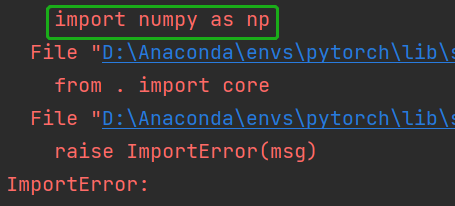
即numpy。然后卸载numpy,重新安装numpy。
然而,还是失败了。我原本安装的numpy是1.19.5,重新安装后是1.24.2,运行后报了一样的错误。而且系统提醒我这个版本的numpy与我其他的库也不匹配。

然后。。。然后。。。我就发现是我建工程的时候出现了问题。。。
解决方案:打开PyCharm软件:File->Settings->Project->Python Interpreter->Python Interpreter>选择base环境
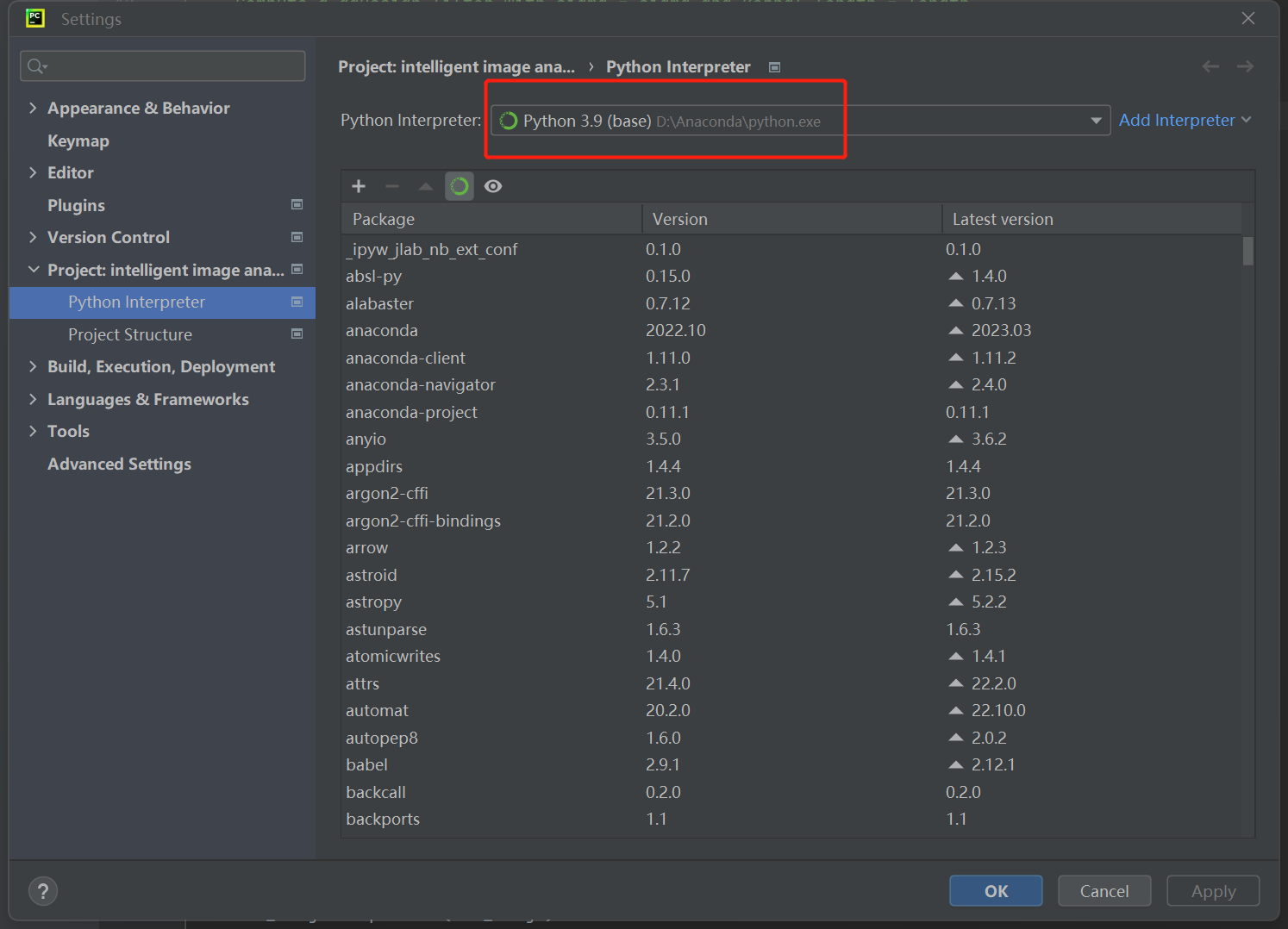
就好了。。。。。
没有系统学过python真的很要命。。。连个工程都不会建。。。。














 2512
2512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









