










文章目录
文件压缩
1 压缩模式
1.为什么要压缩
在Hive中对中间数据或最终数据做压缩,是提高数据吞吐量和性能的一种手段。对数据做压缩,可以大量减少磁盘的存储空间,比如基于文本的数据文件,可以将文件压缩40%或更多。同时压缩后的文件在磁盘间传输和I/O也会大大减少;当然压缩和解压缩也会带来额外的CPU开销,但是却可以节省更多的I/O和使用更少的内存开销。
2.压缩模式评价
- 压缩比
压缩比越高,压缩后文件越小,所以压缩比越高越好。 - 压缩时间
越快越好 - 已经压缩的格式文件是否可以再分割
可以分割的格式允许单一文件由多个Mapper程序处理,可以更好的并行化。
3.可分割
考虑存储在HDFS中的未压缩的文件,其大小为1GB,HDFS的块大小为128M,所以该文件将被存储为8块,将此文件用作输入的MapReduce作业会创建1个输入分片(split,也叫“分块”。对于block,我们统一称为“块”)每个分片都被作为一个独立map任务的输入单独进行处理。
2 压缩算法
1.压缩算法

- 常见的压缩格式

2.Hadoop编码/解码

3.设置压缩模式参数
-
Hive中间数据压缩
hive.exec.compress.intermediate
设置为true为激活中间数据压缩功能,在这个阶段,优先选择一个低CPU开销的算法mapred.map.output.compression.codec
具体的压缩算法的配置参数,SnappyCodec比较适合在这种场景中编解码器,该算法会带来很好的压缩性能和较低的CPU开销 -
Hive最终数据压缩
hive.exec.compress.output
用户可以对最终生成的Hive表的数据通常也需要压缩mapred.output.compression.codec
将hive.exec.compress.output参数设置成true后,然后选择一个合适的编解码器,如选择SnappyCodec
io.compression.codecs 为整体的io方式
而mapred.map.output.compression.codec为map的输出编码
mapred.output.compress为mapreduce结束后的编码
4.Hadoop压缩
- 配置压缩参数
mapreduce.output.fileoutputformat.compress
用于输出
mapreduce.map.output.compress
用于Mapper程序中间输出
mapreduce.output.fileoutputformat.compress.codec
为输出配置默认的编码解码器
mapreduce.map.output.compress.codec
Mapper程序中间输出配置默认的编码解码器
- 配置压缩方式
1. 打开压缩用于输出,在配置时添加下面几行:
Configuration cond = new Configuration();
Jon job = new Job(conf);
FileOutput.setCompressOutput(job,true);
FileOutput.setOutputCompressionClass(job,GzipCodec.class);
//使用Snappy的编码解码器
FileOutputFormat.setOutputCompressionClass(job,SnappyCodec.class)
- 打开压缩用于Mapper程序的中间输出,在配置时我们添加下面的几行
Configuration conf = new Configuration();
conf.setBoolean("mapreduce.map.output.compress",true);
conf.setClass("mapreduce.map.output.compress.codec",GzipCodec.class,CompressionCodec.class);
FileOutput.setCompressOutput(job,true);
FileOutput.setOutputCompressionClass(job,GzipCodec.class);
Job job = new Job(conf)
3 文件存储格式

1.行式存储
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快
- HDFS块内行存储
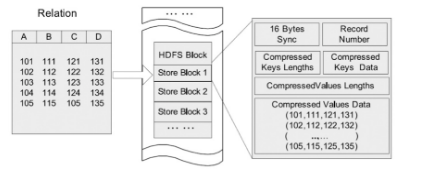
2.列式存储
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法
- HDFS块内列存储

4 Hive中的文件
- TEXTFILE
Hive默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
可结合Gzip、Bzip2、Snappy等使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作 - SEQUENCEFILE
SequenceFile是Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。这种二进制文件内部使用Hadoop 的标准的Writable 接口实现序列化和反序列化。它与Hadoop API中的MapFile 是互相兼容的。Hive 中的SequenceFile 继承自Hadoop API 的SequenceFile,不过它的key为空,使用value 存放实际的值, 这样是为了避免MR 在运行map 阶段的排序过程

Header通过头文件格式

Block-Compressed SequenceFile格式

- RCFILE
RCFile是Hive推出的一种专门面向列的数据格式。 它遵循“先按行划分,再垂直划分”的设计理念。

RCFile结合行存储查询的快速和列存储节省空间的特点:首先,RCFile保证同一行的数据位于同一节点,因此元组重构的开销很低;其次,像列存储一样,RCFile能够利用列维度的数据压缩,并且能跳过不必要的列读取 - ORCFILE(0.11以后出现)
hive/spark都支持这种存储格式,它存储的方式是采用数据按照行分块,每个块按照列存储,其中每个块都存储有一个索引。特点是数据压缩率非常高。 - PAEQUET
Parquet也是一种行式存储,同时具有很好的压缩性能;同时可以减少大量的表扫描和反序列化的时间
- 比较
-
磁盘空间占用大小比较
orc < parquet < textfile这个大小趋势适用于较大的数据,在数据量较小的情况下,可能会出现与之相悖的结论
-
查询语句运行时间大小比较
orc < parquet < textfile这个大小趋势适用于较大的数据,在数据量较小的情况下,可能会出现与之相悖的结论
- 总结
- TextFile默认格式,加载速度最快,可以采用Gzip进行压缩,压缩后的文件无法split,即并行处理
- SequenceFile压缩率最低,查询速度一般,将数据存放到sequenceFile格式的hive表中,这时数据就会压缩存储。三种压缩格式NONE,RECORD,BLOCK。是可分割的文件格式
- RCfile压缩率最高,查询速度最快,数据加载最慢
- 相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势
- 在hive中使用压缩需要灵活的方式,如果是数据源的话,采用RCFile+bz或RCFile+gz的方式,这样可以很大程度上节省磁盘空间;而在计算的过程中,为了不影响执行的速度,可以浪费一点磁盘空间,建议采用RCFile+snappy的方式,这样可以整体提升hive的执行速度。至于lzo的方式,也可以在计算过程中使用,只不过综合考虑(速度和压缩比)还是考虑snappy适宜
文件类型
- 文件格式说明
常见的hive文件存储格式包括以下几类:TEXTFILE、SEQUENCEFILE、RCFILE、ORC。其中TEXTFILE为默认格式,建表时默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理。SequenceFile、RCFile、ORC格式的表不能直接从本地文件导入数据,数据要先导入到TextFile格式的表中,然后再从TextFile表中用insert导入到SequenceFile、RCFile表中。
创建一个非压缩的表存储数据
hive> create database day0325;
OK
Time taken: 2.53 seconds
hive> use day0325;
OK
Time taken: 0.175 seconds
//创建表
hive> create table student(
> id int,
> name string,
> age int)
> row format delimited fields terminated by '\t'
> stored as textfile;
OK
Time taken: 1.682 seconds
//源数据
[yao@master data]$ cat student1.txt
1001 shiny 23
1002 cendy 22
1003 angel 23
1009 ella 21
1012 eva 24
//加载数据
hive> load data local inpath '/home/yao/data/student1.txt' into table student;
Loading data to table day0325.student
Table day0325.student stats: [numFiles=1, totalSize=67]
OK
Time taken: 4.314 seconds
1 textfile
- DEFLATE压缩
//创建表
hive> create table student_delfate(
> id int,
> name string,
> age int)
> row format delimited fields terminated by '\t'
> stored as textfile;
OK
Time taken: 0.228 seconds
//设置压缩类型
hive> set hive.exec.compress.output=true; //打开压缩功能
hive> set mapred.output.compress=true; //设置输出最终模式为压缩
hive> set mapred.output.compression.codec=org.apache.hadoop.io.compress.DefaultCodec; //设置以Default为压缩格式
//不能再用load等方式加载数据,只能以insert的方式加载数据
hive> insert overwrite table student_delfate select * from student;
//查看结果
hive> dfs -ls /user/hive/warehouse/day0325.db/student_delfate;
Found 1 items
-rwxr-xr-x 1 yao supergroup 64 2019-03-25 15:55 /user/hive/warehouse/day0325.db/student_delfate/000000_0.deflate
hive> dfs -cat /user/hive/warehouse/day0325.db/student_delfate/000000_0.deflate;
x3400⭎Ɍ«Ⲳ䰴00ዎ̋?cτ¼?%gjNN"§!chęZdp z //以16进制存储
//可以通过text的形式查看deflate表中的内容
hive> dfs -text /user/hive/warehouse/day0325.db/student_delfate/000000_0.deflate;
1001 shiny 23
1002 cendy 22
1003 angel 23
1009 ella 21
1012 eva 24
- GZIP压缩
//创建表
hive> create table student_gzip(
> id int,
> name string,
> age int)
> row format delimited fields terminated by '\t'
> stored as textfile;
OK
Time taken: 0.187 seconds
//设置压缩类型
hive> set hive.exec.compress.output=true;
hive> set mapred.output.compress=true;
hive> set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; //设置以Gzip为压缩格式
hive> insert overwrite table student_gzip select * from student;
//查看结果
hive> dfs -ls /user/hive/warehouse/day0325.db/student_gzip;
Found 1 items
-rwxr-xr-x 1 yao supergroup 76 2019-03-25 16:10 /user/hive/warehouse/day0325.db/student_gzip/000000_0.gz
hive> dfs -cat /user/hive/warehouse/day0325.db/student_gzip/000000_0.gz; 3400⭎Ɍ«Ⲳ䰴00ዎ̋?cτ¼?%gjNN"§!chęZdp3 'C
hive> dfs -text /user/hive/warehouse/day0325.db/student_gzip/000000_0.gz;1001 shiny 23
1002 cendy 22
1003 angel 23
1009 ella 21
1012 eva 24
//上传到linux系统上查看
hive> dfs -get /user/hive/warehouse/day0325.db/student_gzip/000000_0.gz /home/yao/data
[yao@master data]$ cat 000000_0.gz 3400⭎Ɍ«Ⲳ䰴00ዎ̋?cτ¼?%gjNN"§!chęZdp3 'C
[yao@master data]$ gzip -d 000000_0.gz
[yao@master data]$ cat 000000_0
1001 shiny 23
1002 cendy 22
1003 angel 23
1009 ella 21
1012 eva 24
- BZIP2压缩
//创建表
hive> create table student_bzip2(
> id int,
> name string,
> age int)
> row format delimited fields terminated by '\t'
> stored as textfile;
OK
Time taken: 0.076 seconds
//设置压缩类型
hive> set hive.exec.compress.output=true;
hive> set mapred.output.compress=true;
hive> set mapred.output.compression.codec=org.apache.hadoop.io.compress.BZip2Codec;
//设置以BZip2为压缩格式
//加载数据
hive> insert overwrite table student_bzip2 select * from student;
//查看结果
hive> dfs -ls /user/hive/warehouse/day0325.db/student_bzip2;
Found 1 items
-rwxr-xr-x 1 yao supergroup 83 2019-03-25 16:19 /user/hive/warehouse/day0325.db/student_bzip2/000000_0.bz2
hive> dfs -cat /user/hive/warehouse/day0325.db/student_bzip2/000000_0.bz2;
I0| .AY& P¦M¦ ҍHzjR,i०pa$¥¥v9¼
ԸUԁ¾Ȣ툧
hive> dfs -text /user/hive/warehouse/day0325.db/student_bzip2/000000_0.bz2;
1001 shiny 23
1002 cendy 22
1003 angel 23
1009 ella 21
1012 eva 24
2 sequencefile
- DEFLATE压缩
//创建表
hive> create table student_seq_deflate(
> id int,
> name string,
> age int)
> row format delimited fields terminated by '\t'
> stored as sequencefile;
OK
Time taken: 0.107 seconds
//设置压缩类型
hive> set hive.exec.compress.output=true;
hive> set mapred.output.compress=true;
hive> set mapred.output.compression.codec=org.apache.hadoop.io.compress.DefaultCodec;
//加载数据
hive> insert overwrite table student_seq_deflate select * from student;
//查看结果
hive> dfs -ls /user/hive/warehouse/day0325.db/student_seq_deflate;
Found 1 items
-rwxr-xr-x 1 yao supergroup 297 2019-03-25 16:30 /user/hive/warehouse/day0325.db/student_seq_deflate/000000_0 //不带后缀了,因为它本身就是二进制文件
hive> dfs -cat /user/hive/warehouse/day0325.db/student_seq_deflate/000000_0;
SEQ"org.apache.hadoop.io.BytesWritableorg.apache.hadoop.io.Text*org.apache.hadoop.io.compress.DefaultCodecՃ¸Ƹs
Կ¯x᳴00⭎Ɍ«Ⲳnrx᳴00ዎ̋©Ⲳ̃Zx᳴00卌KOΡ42¯Px0°㍍ȉⲲǂ薄xᴴ04ክKⲲ⃨
hive> dfs -text /user/hive/warehouse/day0325.db/student_seq_deflate/000000_0;
1001 shiny 23
1002 cendy 22
1003 angel 23
1009 ella 21
1012 eva 24
- GZIP压缩
//创建表
hive> create table student_seq_gzip(
> id int,
> name string,
> age int)
> row format delimited fields terminated by '\t'
> stored as sequencefile;
OK
Time taken: 0.221 seconds
//设置压缩类型
hive> set hive.exec.compress.output=true;
hive> set mapred.output.compress=true;
hive> set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
//加载数据
hive> insert overwrite table student_seq_gzip select * from student;
//查看结果
hive> dfs -ls /user/hive/warehouse/day0325.db/student_seq_gzip;
Found 1 items
-rwxr-xr-x 1 yao supergroup 354 2019-03-25 16:33 /user/hive/warehouse/day0325.db/student_seq_gzip/000000_0
hive> dfs -cat /user/hive/warehouse/day0325.db/student_seq_gzip/000000_0;
SEQ"org.apache.hadoop.io.BytesWritableorg.apache.hadoop.io.Text'org.apache.hadoopᴴ04ክKⲲl1Ness.GzipCodec¯\ݏ®]³᳴00⭎Ɍ«ⲲýFs᳴00ዎ̋©Ⲳ¥¯¥᳴00卌KOΡ42_ڠ0°㍍ȉⲲ
hive> dfs -text /user/hive/warehouse/day0325.db/student_seq_gzip/000000_0;
1001 shiny 23
1002 cendy 22
1003 angel 23
1009 ella 21
1012 eva 24
3 RCFILE
//创建表
hive> create table student_rcfile_gzip(
> id int,
> name string,
> age int)
> row format delimited fields terminated by '\t'
> stored as rcfile;
OK
Time taken: 0.134 seconds
//设置压缩类型
hive> set hive.exec.compress.output=true;
hive> set mapred.output.compress=true;
hive> set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
//加载数据
hive> insert overwrite table student_rcfile_gzip select * from student;
//查看结果
hive> dfs -ls /user/hive/warehouse/day0325.db/student_rcfile_gzip;
Found 1 items
-rwxr-xr-x 1 yao supergroup 248 2019-03-25 16:41 /user/hive/warehouse/day0325.db/student_rcfile_gzip/000000_0
//不能通过-text来查看了
hive> dfs -text /user/hive/warehouse/day0325.db/student_rcfile_gzip/000000_0;
RCF'org.apache.hadoop.io.compress.GzipCodechive.io.rcfile.column.number3ӃĂ,?B뺂jxcU妢þ%ǂ??ꢾڇ?忦/+ψ̫LN̋©LˋỎΉIL-K \
4 ORCFILE
- ZLIB压缩
//创建表
hive> create table student_orcfile_zlib(
> id int,
> name string,
> age int)
> row format delimited fields terminated by '\t'
> stored as orcfile
> tblproperties("orc.compress"="ZLIB");
OK
Time taken: 0.202 seconds
//导入数据
hive> insert overwrite table student_orcfile_zlib select * from student;
//查看结果
hive> dfs -ls /user/hive/warehouse/day0325.db/student_orcfile_zlib;
Found 1 items
-rwxr-xr-x 1 yao supergroup 432 2019-03-25 16:47 /user/hive/warehouse/day0325.db/student_orcfile_zlib/000000_0
//不能通过-text查看
hive> dfs -text /user/hive/warehouse/day0325.db/student_orcfile_zlib/000000_0;
ORC P1
А 晆NP@㓧be!1V%.ׄ¼?ע̼J -
*0`ᣧ`㤸¯ᠢP@UI51/=5Gµ8#3¯RB(aFCN.,.*0⣣``ᤂьѠIBL3KHiF 8f?7ͬ?ńL0,ƫX¨ ~㳣b
͔Ɏ¡%` ?㢠x¨ƅ?$a¡ુª$ā#ŌɄ,Úc¡
!3³hV+Ԇ+~V!NK??¸X?X32?⻀ꛚt"
(B0?RChive
5 Parquet
- snappy
hive> create table student_parquet_snappy(
> id int,
> name string,
> age int)
> row format delimited fields terminated by '\t'
> stored as parquet;
OK
Time taken: 0.087 seconds
hive> set hive.exec.compress.output=true;
hive> set mapred.compress.map.output=true; //对中间结果进行压缩
hive> set mapred.output.compress=true; //对最终结果进行压缩
hive> set mapred.output.compression=org.apache.hadoop.io.compress.SnappyCodec; //设置中间结果的压缩类型
hive> set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec; //设置最终结果的压缩类型
hive> set io.compression.codecs=org.apache.hadoop.io.compress.SnappyCodec; //整体的io的压缩类型
//
hive> insert overwrite table student_parquet_snappy select * from student;
//查看结果
hive> dfs -ls /user/hive/warehouse/day0325.db/student_parquet_snappy;
Found 1 items
-rwxr-xr-x 1 yao supergroup 442 2019-03-25 16:57 /user/hive/warehouse/day0325.db/student_parquet_snappy/000000_0
hive> dfs -text /user/hive/warehouse/day0325.db/student_parquet_snappy/000000_0;
PAR144, ?灖焪鄱?``, shinyangelshinycendyangelellaeva44, LH
hive_schema%id
%name%%age
<id
vv<?灖&~
name
¦¦&~<shinyangel&¤age
vv&¤<
(parquet-mr version 1.6.0䏁R1
6 AVRO
- GZIP压缩
//创建表
hive> create table student_avro_gzip(
> id int,
> name string,
> age int)
> row format delimited fields terminated by '\t'
> stored as avro;
OK
Time taken: 0.228 seconds
//设置压缩类型
hive> set hive.exec.compress.output=true;
hive> set mapred.output.compress=true;
hive> set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
//插入数据
hive> insert overwrite table student_avro_gzip select * from student;
// 查看结果
hive> dfs -ls /user/hive/warehouse/day0325.db/student_avro_gzip;
Found 1 items
-rwxr-xr-x 1 yao supergroup 365 2019-03-25 17:13 /user/hive/warehouse/day0325.db/student_avro_gzip/000000_0
hive> dfs -text /user/hive/warehouse/day0325.db/student_avro_gzip/000000_0;
{"id":{"int":1001},"name":{"string":"shiny"},"age":{"int":23}}
{"id":{"int":1002},"name":{"string":"cendy"},"age":{"int":22}}
{"id":{"int":1003},"name":{"string":"angel"},"age":{"int":23}}
{"id":{"int":1009},"name":{"string":"ella"},"age":{"int":21}}
{"id":{"int":1012},"name":{"string":"eva"},"age":{"int":24}}
文件存储情况
[yao@master product]$ hadoop fs -ls /user/hive/warehouse/day0325.db/*
Found 1 items
-rwxr-xr-x 1 yao supergroup 67 2019-03-25 15:47 /user/hive/warehouse/day0325.db/student/student1.txt
Found 1 items
-rwxr-xr-x 1 yao supergroup 365 2019-03-25 17:13 /user/hive/warehouse/day0325.db/student_avro_gzip/000000_0
Found 1 items
-rwxr-xr-x 1 yao supergroup 83 2019-03-25 16:19 /user/hive/warehouse/day0325.db/student_bzip2/000000_0.bz2
Found 1 items
-rwxr-xr-x 1 yao supergroup 64 2019-03-25 15:55 /user/hive/warehouse/day0325.db/student_delfate/000000_0.deflate
Found 1 items
-rwxr-xr-x 1 yao supergroup 76 2019-03-25 16:10 /user/hive/warehouse/day0325.db/student_gzip/000000_0.gz
Found 1 items
-rwxr-xr-x 1 yao supergroup 432 2019-03-25 16:47 /user/hive/warehouse/day0325.db/student_orcfile_zlib/000000_0
Found 1 items
-rwxr-xr-x 1 yao supergroup 442 2019-03-25 16:57 /user/hive/warehouse/day0325.db/student_parquet_snappy/000000_0
Found 1 items
-rwxr-xr-x 1 yao supergroup 210 2019-03-25 17:11 /user/hive/warehouse/day0325.db/student_rcfile_gzip/000000_0
Found 1 items
-rwxr-xr-x 1 yao supergroup 297 2019-03-25 16:30 /user/hive/warehouse/day0325.db/student_seq_deflate/000000_0
Found 1 items
-rwxr-xr-x 1 yao supergroup 354 2019-03-25 16:33 /user/hive/warehouse/day0325.db/student_seq_gzip/000000_0
相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势。















 1379
1379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









