







查看任何 LLM 教程,建议的用法包括调用 API、向其发送提示并使用响应。
假设你希望 LLM 生成感谢信,可以执行以下操作:
import openai
recipient_name = "John Doe"
reason_for_thanks = "helping me with the project"
tone = "professional"
prompt = f"Write a thank you message to {recipient_name} for {reason_for_thanks}. Use a {tone} tone."
response = openai.Completion.create("text-davinci-003", prompt=prompt, n=1)
email_body = response.choices[0].text虽然这对于 PoC 来说很好,但使用将 LLM 视为另一个文本到文本(或文本到图像/音频/视频)API 的架构进行生产会导致应用程序在风险、成本和延迟方面设计不足。
解决方案不是走向另一个极端,每次都通过微调 LLM 和添加护栏等方式过度设计你 的应用程序。与任何工程项目一样,目标是针对每个用例的具体情况找到复杂性、适用性、风险、成本和延迟之间的适当平衡。在本文中,我将描述一个可帮助您实现这种平衡的框架。
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
0、LLM 应用程序架构的框架
这是我建议你用来决定 GenAI 应用程序或代理的架构的框架。我将在后面的部分中介绍下图中显示的八种替代方案。
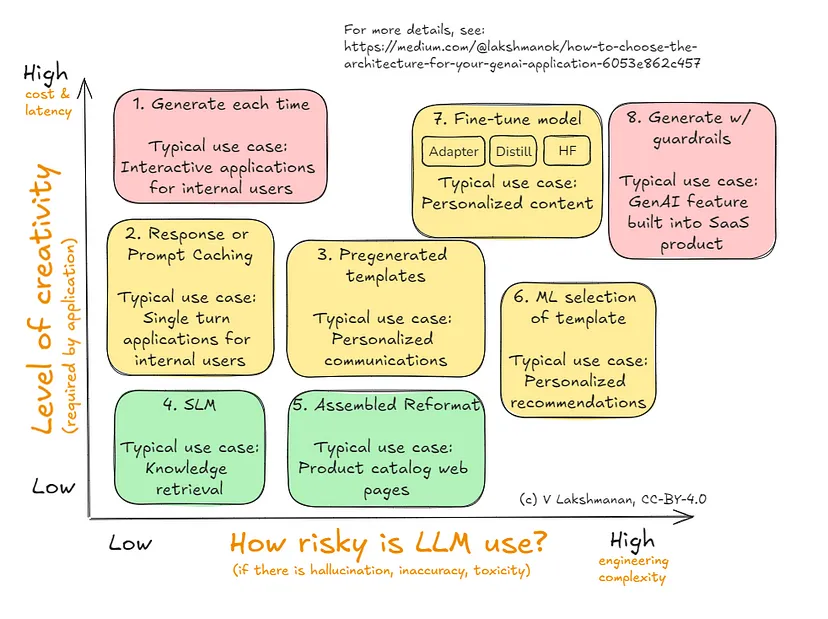
为你的 GenAI 应用程序选择正确的应用程序架构
此处的轴(即决策标准)是风险和创造力。对于你要使用 LLM 的每个用例,首先确定您需要从 LLM 获得的创造力以及用例带来的风险量。这可以帮助你缩小适合您的选择范围。
请注意,是否使用 Agentic Systems 是一个完全正交的决定 - 当任务太复杂而无法通过单个 LLM 调用完成或任务需要非 LLM 功能时,使用 Agentic Systems。在这种情况下,你可以将复杂任务分解为更简单的任务并在代理框架中协调它们。本文向您展示了如何构建 GenAI 应用程序(或代理)来执行其中一项简单任务。
0.1为什么第一个决策标准是创造力
为什么创造力和风险作为一个轴? LLM 是一种非确定性技术,如果你不需要所创建内容具有那么多独特性,那么 LLM 带来的麻烦会比其价值更大。
例如,如果你要生成一堆产品目录页面,它们到底需要有多大的不同?你的客户希望获得有关产品的准确信息,并且可能并不真正关心所有 SLR 相机页面是否都以相同的方式解释 SLR 技术的优势——事实上,一定程度的标准化可能更有利于便于比较。在这种情况下,你对 LLM 的创造力要求很低。
事实证明,减少非确定性的架构也会减少对 LLM 的总调用次数,因此也有降低使用 LLM 的总体成本的副作用。由于 LLM 调用比典型的 Web 服务慢,因此这也有减少延迟的良好副作用。这就是为什么 y 轴是创造力,以及为什么我们在该轴上也有成本和延迟。

说明性:按创造力排序的用例
你可以查看上图中列出的说明性用例,并讨论
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









