






这是一篇关于MySQL数据库,redo log,LSN,崩溃恢复,在线热备的长文,耐心读完,如果没有收获,可以捶我。
研发的童鞋每次对MySQL库表做重大操作之前,例如:
(1)修改表结构;
(2)批量修改或者删除数据;
都会向DBA申请进行数据库的备份。
画外音:又或者说,不备份直接操作啦?
那DBA童鞋是怎么进行MySQL备份的呢?
调研了几十个RD和QA,基本是3种答案:
(1)不太清楚;
(2)在线逻辑备份,mysqldump;
(3)离线物理备份(冷备),拷贝从库库文件;
那实际上,DBA是如何对MySQL进行库备份的呢?
现在基本上使用的是PXB方案。
今天,和大家说说MySQL备份的来龙去脉,以及内核原理。
在线逻辑备份,mysqldump是咋回事?
mysqldump是MySQL工具集中的一个工具,可以用来导出或备份数据。
mysqldump的产出物是一个包含了建表,插入数据的SQL语句集合,类似于这样:
-- MySQL dump 1.2.3
-- Host: localhost Database: test
-- Server version 4.5.6
CREATE TABLE t_user (
id int(11)NOT NULL unique,
name varchar(40) NOT NULL default '',
PRIMARY KEY (id)
);
INSERT INTO t_user VALUES (1,'shenjian');
INSERT INTO t_user VALUES (2,'zhangsan');
INSERT INTO t_user VALUES (3,'lisi');
因此,它才称为逻辑备份。
使用mysqldump进行备份的优点是:可以在线进行,不影响数据库对线上持续提供服务。
缺点也显而易见:相比物理备份拷贝库文件,备份和恢复都要慢非常多。
离线物理备份,拷贝从库库文件又是咋回事?
为了提高备份效率,缩短备份时间,这也就引发了第二种方案,直接物理备份库文件。
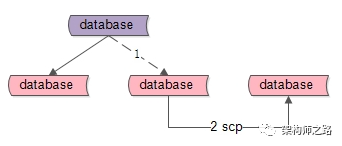
如上图所示,数据库集群设置为左侧的1主2从架构,离线物理备份是如何实施的呢?
(1)第一步,将一个从库从集群里摘下并下线,此时离线库文件不会再发生变化;
(2)第二步,scp拷贝库文件,即完成了库的物理备份;
(3)文件拷贝完成后,将从库挂回集群;
使用离线物理备份的优点是:备份和恢复都非常快。
缺点也显而易见:备份过程中从库无法对线上持续提供服务。
那么问题来了,有没有一种方案,又能够快速备份物理文件,又能够持续对线上提供服务呢?
这就是如今MySQL备份最流行的PXB方案。
什么是PXB?
PXB的全称是,Percona XtraBackup,官网是这么吹的:PXB是全世界唯一一款开源免费的,支持MySQL热备的,非阻塞备份工具。
画外音:Percona XtraBackup is the world’s only open-source, free MySQL hotbackup software that performs non-blocking backups tool.
那么,PXB是如何实现:
(1)保持数据库持续提供线上服务,库文件不断变化时;
(2)通过MySQL文件;
(3)来进行库文件物理热备份的呢?
为了把问题讲透,这就要从redo log,从LSN,从MySQL的故障恢复(crash-recovery)机制聊起。
一、redo log
为什么要有redo log?
事务提交后,必须将事务对数据页的修改刷(fsync)到磁盘上,才能保证事务的ACID特性。
这个刷盘,是一个随机写,随机写性能较低,如果每次事务提交都刷盘,会极大影响数据库的性能。
随机写性能差,有什么优化方法呢?
架构设计中有两个常见的优化方法:
(1)先写日志(write log first),将随机写优化为顺序写;
(2)将每次写优化为批量写;
这两个优化,数据库都用上了。
第一个优化,将对数据的修改先顺序写到日志里,这个日志就是redo log。
第二个优化,就是redo log的三层架构:
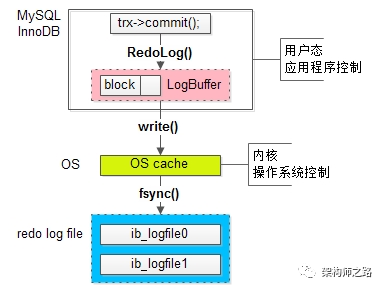
(1)log buffer:应用层缓冲;
(2)OS cache:操作系统缓存;
(3)redo log file:物理文件;
画外音:此处不是本文的重点,不再展开详述。
假如某一时刻,数据库崩溃,还没来得及将数据页刷盘,数据库重启时,会重做redo log里的内容,以保证已提交事务对数据的影响被刷到磁盘上。
一句话,redo log是为了保证已提交事务的ACID特性,同时能够提高数据库性能的技术。
二、redo log的格式
逻辑上,MySQL以行(row)为单位管理数据;物理上,MySQL以页(page)为单位管理数据,MySQL的缓冲池(buffer)机制,也是以页为单位管理数据,事务提交之后,不用每次都随机写落盘刷新数据页,而是通过顺序写redo log来提高性能,那么redo log是直接保存等待刷盘的数据页吗?
如果redo log直接保存待刷盘的数据页,存在这样的问题,假如某个SQL语句只修改了一行记录里的一个属性,例如:
update set sex=1 where name='shenjian'
物理上,其实只修改了1个字节,难道redo log要将这个属性所在的一页数据(16K)全部保存下来吗?
完全不用,redo log只需要记录:
(1)某个数据页中(page num);
(2)某个某个偏移位置(offset);
(3)某个类型的数据(type);
(4)改成了什么值(value);
如此一来,redo log既能够实现以页为单位顺序刷盘数据,又极大缩小了日志大小,其性能又进一步的增加了。
update set sex=1 where name='shenjian'
仍以这个SQL为例,假设它修改了第1234页,偏移量为5678处,1个字节的数据,这个字节的sex由0改成了1,那么,很容易想到redo log是类似于这样的一个结构:

如此一来,当数据库崩溃的时候,如果缓冲池中的数据没有来得及刷盘,就可以通过redo log,把第1234页,偏移量为5678处的1个字节改为1,以此来恢复数据。
当然,MySQL会通过一系列的数据结构对redo log来进行管理,最小单位的redo log是一个512字节的数据块(block),这个数块由12字节的header,508字节的body,4字节的trailer组成,body里保存的就是上述数据页如何进行修改的记录。
记录redo log的文件有若干个,每个都固定大小,循环使用。
画外音:为了使得行文通俗易懂,本文尽量没有提及Mini-Transaction(mtr)的概念。
三、LSN
要聊redo log,要聊故障恢复,LSN是一个绕不开的概念。
什么是LSN?
LSN,Log Sequeue Number,直译过来叫日志序列号,是InnoDB中,随着日志的写入,一个只增不减的8字节序列号。
听上去叫日志序列号,但LSN并不只存在redo log中,它还存储在数据页里。
画外音:缓冲池中的数据页,磁盘上的数据页都存储了LSN。
数据页(page)里存储的LSN,可以用来标记数据页的“版本号”,记录该数据页最后一次被修改的日志序列的位置。
举个例子,假设逻辑上连续执行了两个事物,且都已经提交:
trx1:
update set sex=0 where name='shenjian'
redolog lsn=1000
trx2:
update set sex=1 where name='shenjian'
redolog lsn=1001
画外音:lsn增加了。
又假设,第一个事务trx1已经刷盘,而第二个事务trx2还没有刷盘,只写了redo log。
画外音:最近一次刷盘的页,即最近一次检查点(checkpoint),也是通过LSN来记录的,它也会被写入redo log里。
这两个事务修改的是同一个数据页,很容易想到:
磁盘数据页上的LSN=1000
而redo log里有两条记录:
第一条,redo log lsn=1000
第二条,redo log lsn=1001
为了提高数据库性能,数据库基本都是使用WAL(Write Ahead Log)的方式,先写日志再刷盘,所以很容易能够想到,磁盘数据页里的LSN,会小于最新redo log中的LSN。
画外音:此时,redo log中记录的checkpoint也是1000。
LSN有什么用呢?
它和MySQL的故障恢复(crash-recovery)机制紧密相关。
四、InnoDB故障恢复(crash-recovery)
这里的故障恢复,是指MySQL非正常退出,然后再次启动之前,要恢复数据一致性的操作。
画外音:可能直译叫崩溃恢复更准确一些。
InnoDB的崩溃恢复过程是怎么样的?
主要分为四个步骤:
第一步,redo log操作:保证已提交事务影响的最新数据刷到数据页里。
第二步,undo log操作:保证未提交事务影响的数据页回滚。
第三步,写缓冲(change buffer)合并。
画外音:不是今天的重点,关于写缓冲的概念,详见《写缓冲(change buffer),这次彻底懂了!》。
第四步,purge操作。
画外音:InnoDB的一种垃圾收集机制,使用单独的后台线程周期性处理索引中标记删除的数据,也不是今天的重点,未来可以详细讲。
第一个步骤中,redo log操作是如何恢复最新的数据页的呢?
(1)从redo log中读取checkpoint lsn,它记录的是最后一次刷盘的页,对应日志的LSN;
(2)如果redo log中记录的日志LSN小于checkpoint,说明相关数据已经被刷盘,不用额外操作;
(3)如果redo log中记录的日志LSN大于checkpoint,说明相关数据只写了redo log,没来得及刷盘,就需要对相关数据页重做日志,例如:

将第1234页,偏移量为5678处的1个字节改为1,以此来恢复数据。
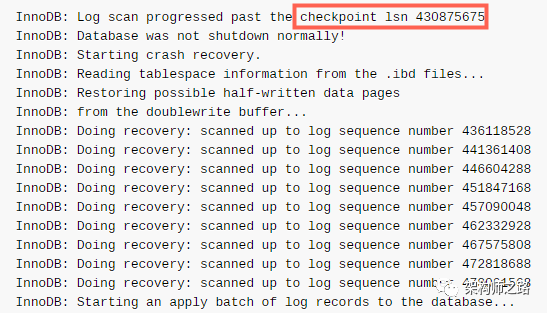
崩溃恢复过程中,MySQL的启动日志更形象的说明了这一点:
(1)先找到checkpoint;
(2)然后不断的扫描大于checkpoint的redo log,不断的恢复数据;
画外音:redo log的LSN可以看到恢复的进程。
多说一句,redo log还有两个特性:
第一,幂等性,同一条redo log执行多次,不影响数据的恢复。
第二,崩溃恢复时,从比checkpoint更早的LSN开始执行恢复,也不影响数据最终的一致性,因为一个数据页,最终一定会被更大值的LSN日志恢复到最新的数据上来;
五、PXB在线热备原理
不知不觉写了几千字,差点忘了缘起的问题。
PXB是如何实现:
(1)保持数据库持续提供线上服务,库文件不断变化时;
(2)通过MySQL文件;
(3)来进行库文件物理热备份的呢?
通过上面大把的铺垫,这个问题的回答就容易了。
首先,PXB启动一个线程,并不断监听并复制redo log的增量到另外的文件,不能直接备份redo log的原因是,redo log循环使用的,PXB则必须记录下checkpoint LSN之后的所有redo log。
然后,PXB启动另一个线程,然后开始复制数据文件,复制数据文件过程可能会比较长,整个过程中数据文件可能在不停的修改,导致数据不一致。但没有关系,所有的修改都已经记录在了第一步中,额外记录的redo log里。
画外音:务必注意,备份redo log的线程,必须在开始备份数据文件之前启动,之后结束。
最后,通过备份的数据文件,重放redo log,执行类似于MySQL崩溃恢复过程中的动作,就能够使得数据文件恢复到能保证一致性的checkpoint检查点。
画外音:PXB还可以对非MySQL,非InnoDB进行在线热备,这里就不展开了。
是不是很神奇啊!
这是一篇关于MySQL数据库,redo log,LSN,崩溃恢复,在线热备的长文,耐心读完,如果没有收获,可以捶我。
MySQL内核相关文章:
都看到这里了,不来个三连吗?谢转!















 355
355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









