







 该博客探讨了联邦学习中Non-IID数据的生成方法,通过迪利克雷分布模拟不同程度的Non-IID情况,分析了数据量、本地迭代轮数、学习率等参数对性能的影响。提出了一种基于动量的解决方案,能有效缓解Non-IID导致的性能下降。研究基于CIFAR-10数据集,展示了动量更新在优化学习率方面的作用。
该博客探讨了联邦学习中Non-IID数据的生成方法,通过迪利克雷分布模拟不同程度的Non-IID情况,分析了数据量、本地迭代轮数、学习率等参数对性能的影响。提出了一种基于动量的解决方案,能有效缓解Non-IID导致的性能下降。研究基于CIFAR-10数据集,展示了动量更新在优化学习率方面的作用。
主要内容:
1、基于迪利克雷分布,提出了一种FL中Non-IID数据的生成方法;
2、对不同程度的Non-IID数据下,进行了较多的对比试验,研究客户端数据量、本地迭代轮数、学习率等参数对性能的影响;
3、提出了一种基于动量的解决方案,可以有效缓解Non-IID带来的性能下降。

论文地址:https://arxiv.org/pdf/1909.06335.pdf
01 Introduction 介绍
介绍了一下FL和Non-IID数据的背景知识,不清楚的小伙伴可以看之前的文章。
02 Related Work 相关工作
在FL中图像分类数据集的相关生成工作,一部分是在MNIST、CIFAR-10等数据集上进行划分,存在分布极端、划分数据池不够大等问题,不符合实际情况;另一部分工作就是使用
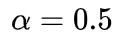
的Dirichlet分布来合成Non-IID数据集。作者主要是使用连续的 生成一系列分布,来研究超参数的设置和优化方案。
下图中2018那篇论文之前的文章分享给过,有兴趣的小伙伴可以看看:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









