







 本文提出视觉注意网络(VAN),通过大核注意力(LKA)模型结合卷积和自注意力的优点,解决CNN和Transformer的局限。VAN在图像分类、目标检测等任务上超越SOTA,并探讨了未来改进方向。
本文提出视觉注意网络(VAN),通过大核注意力(LKA)模型结合卷积和自注意力的优点,解决CNN和Transformer的局限。VAN在图像分类、目标检测等任务上超越SOTA,并探讨了未来改进方向。
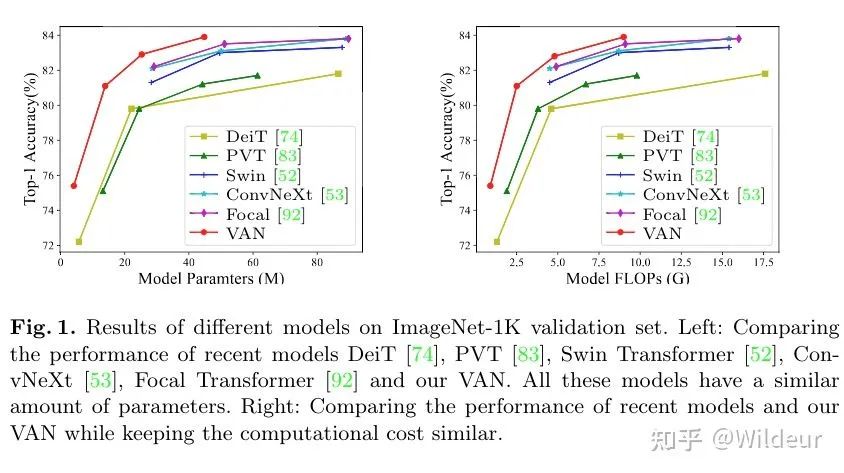
在本文中,提出了一种新的大核注意力large kernal attention(LKA)模型, LKA吸收了卷积和自我注意的优点,包括局部结构信息、长程依赖性和适应性。同时,避免了忽略在通道维度上的适应性等缺点。作者进一步介绍了一种基于LKA的新型神经网络,即视觉注意网络(VAN)。VAN在图像分类、目标检测、实例分割、语义分割方面,都”远远超过了”SOTA的CNN和视觉transformer。

原文地址:https://arxiv.org/abs/2202.09741
相关工作
CNN
学习特征表示(feature representation)很重要, CNN因为使用了局部上下文信息和平移不变性,极大地提高了神经网络的效率。在加深网络的同时,网络也在追求更加轻量化。本文的工作与MobileNet有些相似,把一个标准的卷积分解为了两个部分:一个depthwise conv,一个pointwise conv。本文把一个卷积分解成了三个部分:depthwise conv, depthwise and dilated conv 和pointwise conv。我们的工作将更适合高效地分解大核
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 761
761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









