







 SimMIM是微软亚研院提出的无监督学习方法,类似于MAE,用于图像建模。SimMIM通过随机mask图像区域并预测像素值,表明简单设计也能达到高效性能,尤其适合训练金字塔结构的模型如Swin Transformer。尽管其线性层解码器和处理所有tokens的编码器与MAE有所不同,但实验结果显示SimMIM在预训练和finetune后效果接近MAE,且具有更好的灵活性。
SimMIM是微软亚研院提出的无监督学习方法,类似于MAE,用于图像建模。SimMIM通过随机mask图像区域并预测像素值,表明简单设计也能达到高效性能,尤其适合训练金字塔结构的模型如Swin Transformer。尽管其线性层解码器和处理所有tokens的编码器与MAE有所不同,但实验结果显示SimMIM在预训练和finetune后效果接近MAE,且具有更好的灵活性。
自从何恺明的MAE(←点击蓝字查看文章详情)出来之后,基于MIM(Masked Image Modeling)的无监督学习方法越来越受到关注。这里介绍一篇和MAE同期的工作:SimMIM: A Simple Framework for Masked Image Modeling,研究团队是微软亚研院。
SimMIM和MAE有很多相似的设计和结论,而且效果也比较接近,比如基于ViT-B的模型无监督训练后再finetune可以ImageNet数据集达到83.8%的top1 accuray(MAE为83.6%)。不过相比MAE,SimMIM更加简单,而且也可以用来无监督训练金字塔结构的vision transformer模型如swin transformer等。目前SimMIM实现代码已经开源,本文将基于论文和源码对SimMIM方法进行解读。
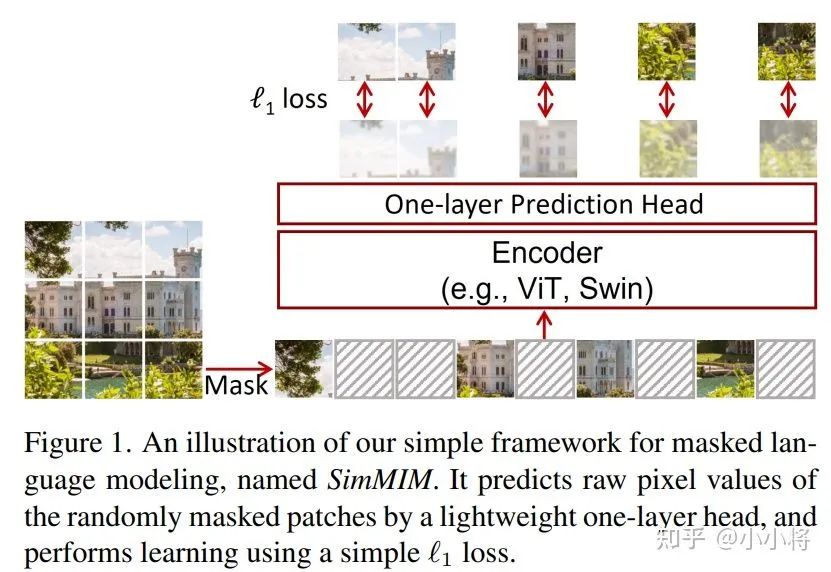
算法原理
SimMIM采用最简单的MIM方法:随机mask掉输入图像的一部分patch,然后通过encoder-decoder来预测masked patchs的原始像素值。算法原理图如上图所示,从设计方面和MAE基本一致。SimMIM的主要结论如下:
-
直接对图像采用简单的random mask是非常简单有效的方法;
-
直接回归原始的像素的RGB值不比BEiT采用的分类效果差;
-
decoder采用轻量级的设计(直接采用一个线性层)也能得到很好的效果;
这些结论也是在MAE论文中得到了验证。那么SimMIM和MAE的区别在哪里呢?主要有以下两点:
-
SimMIM的encoder同时处理visible tokens和masked tokens,而MAE的encoder只处理visible tokens;
-
SimMIM的decoder只采用一个线性层来回归像素值,而MAE的decoder采用transformer结构;
第2个差异带来的影响相对很小,因为两个论文都证明了decoder设计对性能影响较小。主要的差异点是第一个,MAE训练时只处理visible tokens一方面可以加速训练(减少了计算量),同时也可以减少pre-training和deploy之间的gap(deploy时输入是非masked的图像,无masked token),MAE实验也证明只处理visible tokens可以提升linear probing性能:73.5% vs 59.6%。
而SimMIM是处理所有的tokens,从实验结果上看也符合MAE的结论,SimMIM方法得到的ViT-B模型的linear probing只有56.7%,不过这不并不会影响finetune后的性能,关于这点MAE论文也论证了。不过SimMIM这样做带来的一个好处是可以用来训练其它非“同质结构”模型,比如swin transformer,由于它各个stage间要对patch进行merge操作,所以token并不是像ViT那样一成不变的。下面我们具体介绍SimMIM的各个部分,这里默认实验都是以Swin-B为encoder,为了减少实验成本,输入图像大小为192x192(原来是224),window size设置为6(原来是7),预训练epoch为100。
Masking Strategy
SimMIM的masking策略按照一定mask ratio随机mask掉一部分patch。在MAE中,masked patch size和ViT的patch size是一致的,比如ViT-B/16模型,masked patch size就要设计为16x16,然后用一个可学习的masked token来代替。但是对于SimMIM,其设计masked patch size不一定等于模型的patch size,比如ViT模型masked patch size可以是32x32,理论上mask patch size只要是ViT模型patch size的整数倍就可以,因此此时每个mask掉的patch可以整分成和模型patch一样大小的若干个patch。
对于金字塔结构的swin transformer,每个stage的patch size是不同的,比如第一个stage的patch size是4x4,而最后一个stage的patch size是32x32,此时设计的mask patch size只需要是第一个stage的patc
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 463
463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









