







>豆瓣电影
首先,找到豆瓣电影的分级评分页面,并初步分析页面结构:
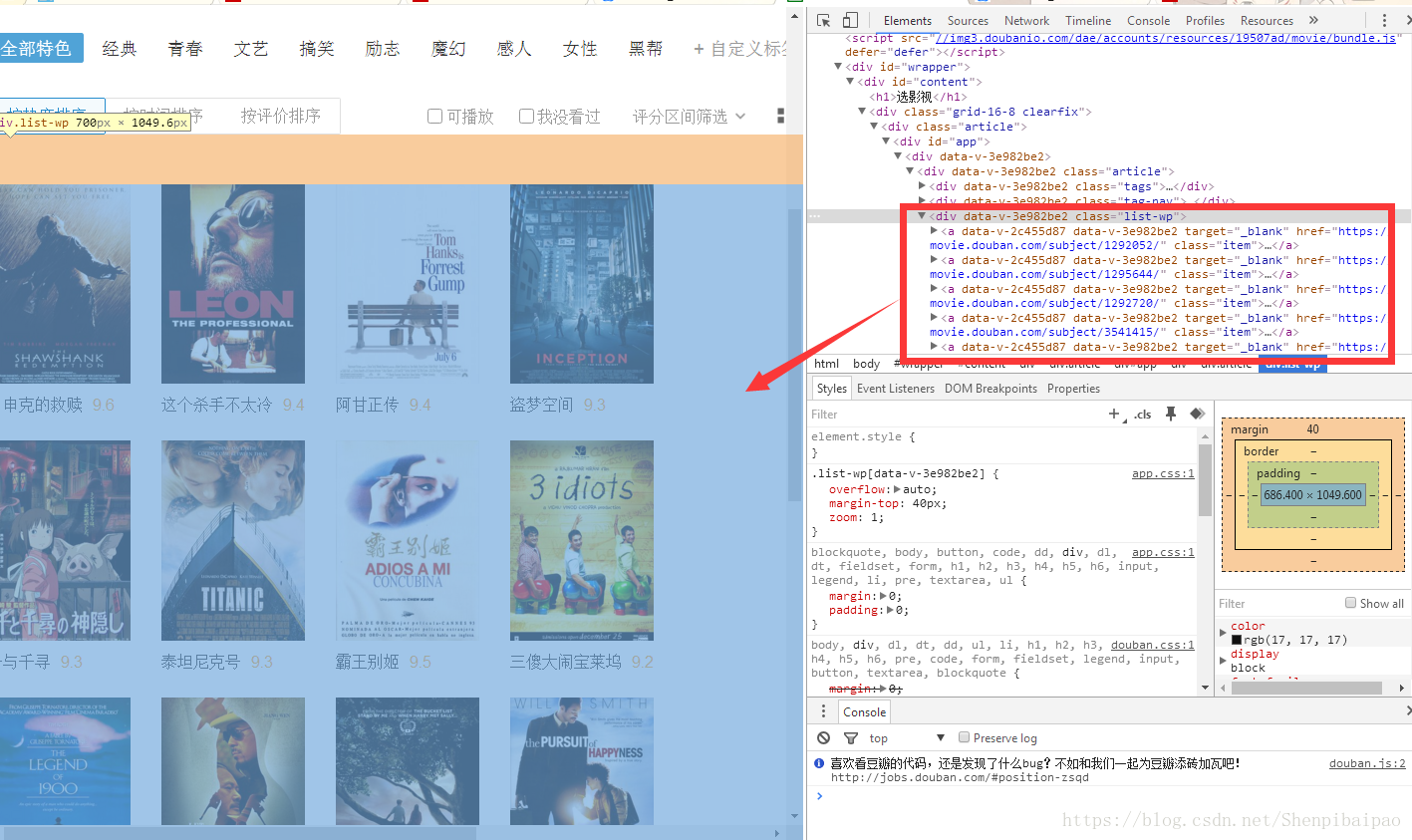
然而实际上,这个页面是动态加载的,我们需要按照在[爬虫02]中介绍的抓取网易歌单的方法,去分析API接口,直接抓取相关的json数据。按下键盘的F12打开浏览器控制台,根据之前的方法,可以很简单的找到、分析出它实际的HTTP API地址为:https://movie.douban.com/j/new_search_subjects。其参数表见下图:
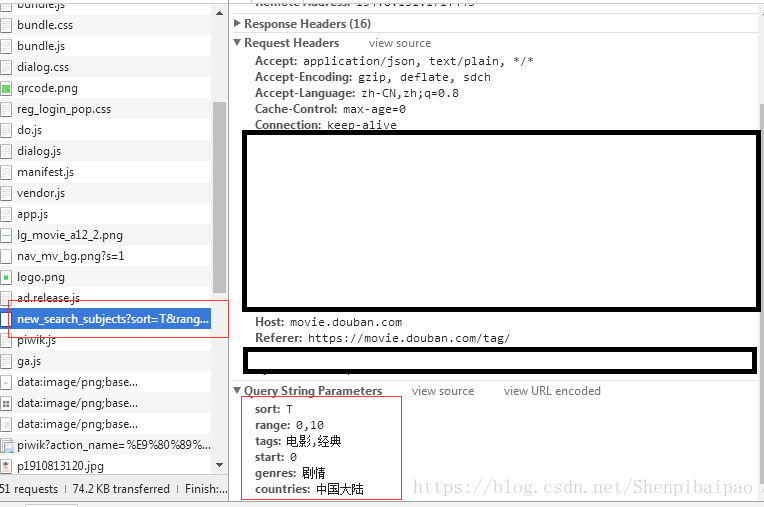
>爬虫代码
那么,就可以很简单的给出关于豆瓣爬虫类的代码了。而这其中比较需要注意的几点,就是关于页面编码的问题,在get_api_json()方法的最后两行:
# coding=utf-8
import requests
from bs4 import BeautifulSoup
import json
import urllib
# //MyBlog @See http://blog.csdn.net/shenpibaipao
class DoubanSpider:
# 这是各个url参数的值,其值的取值见豆瓣页面
__douban_url = 'https://movie.douban.com/j/new_search_subjects?'
__sort = 'T'
__star_range = '0,10'
__start = 0
__countries = ''
__genres = ''
__tags = ''
def __init__(self):
self.__douban_url = 'https://movie.douban.com/j/new_search_subjects?'
self.__sort = 'T'
self.__star_range = '0,10'
self.__start = 0
self.__countries = ''
self.__genres = ''
self.__tags = ''
@staticmethod
def get_api_json(bs):
json_data = '{}'
for _ in bs.select('p'):
json_data = json.dumps(_.string, sort_keys=True)
break
json_data = json.loads(json_data).encode('utf-8') # 直接loads会返回了unicode
return json.loads(json_data) # 返回成dict
def set_params(self, sort='T', star_range='0,10', tags='', start=0, genres='', countries=''):
self.__sort = sort
self.__star_range = star_range
self.__tags = tags
self.__start = start
self.__genres = genres
self.__countries = countries
def get_params(self):
param_dict = {
'sort': self.__sort,
'range': self.__star_range,
'tags': self.__tags,
'start': self.__start,
'genres': self.__genres,
'countries': self.__countries
}
return self.__douban_url+urllib.urlencode(param_dict) # 需要经过urlencode
def __next_page(self):
self.__start = self.__start + 20
def crawl(self):
session = requests.session()
bs = BeautifulSoup(session.get(self.get_params()).content, "lxml")
data = DoubanSpider.get_api_json(bs)
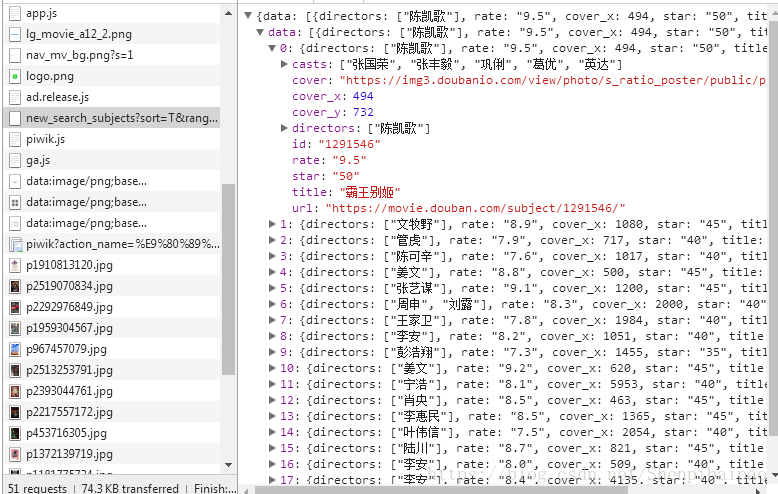
for i in data['data']: # 关于抓取内容的解析,见下图
cover_url = i['cover'] # 电影封面图片的地址,可在[爬虫03]中看到如何下载图片
url = i['url']
rate = i['rate']
star = int(i['star'])/10.0 # 5星制
directors = i['directors']
casts = i['casts']
title = i['title']
print title # 打印标题,这里的title是utf-8编码的下图是通过HTTP API获取到的JSON数据,所以分析时去头去尾(<html><p>json数据</p></html>),把json数据得到后解析成python dict对象,就可以很方便的得到相应的数据。














 4919
4919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









