






我是Beaten,今天分享用BeautifulSoup爬取小说
免责声明:本文仅用作交流分享,切勿用于商业用途!
本文以某趣阁为例,首先进行导包
import requests
from bs4 import BeautifulSoup
from requests import RequestException
import os
import chardet当然这些外部库如果你的本地环境没有,记得关掉代理后进行
pip install requests #本地环境
conda install requests #虚拟环境总之在这里你需要
pip install + 包名众所周知,爬虫一定缺不了我们的请求头,所以我们以玄幻小说-伏天氏为例,点开该页面以后我们我首先F12然后根据图片操作找到我们的user-agent,(记得F5刷新一下),这就得到了请求头,这个有大用,你切记!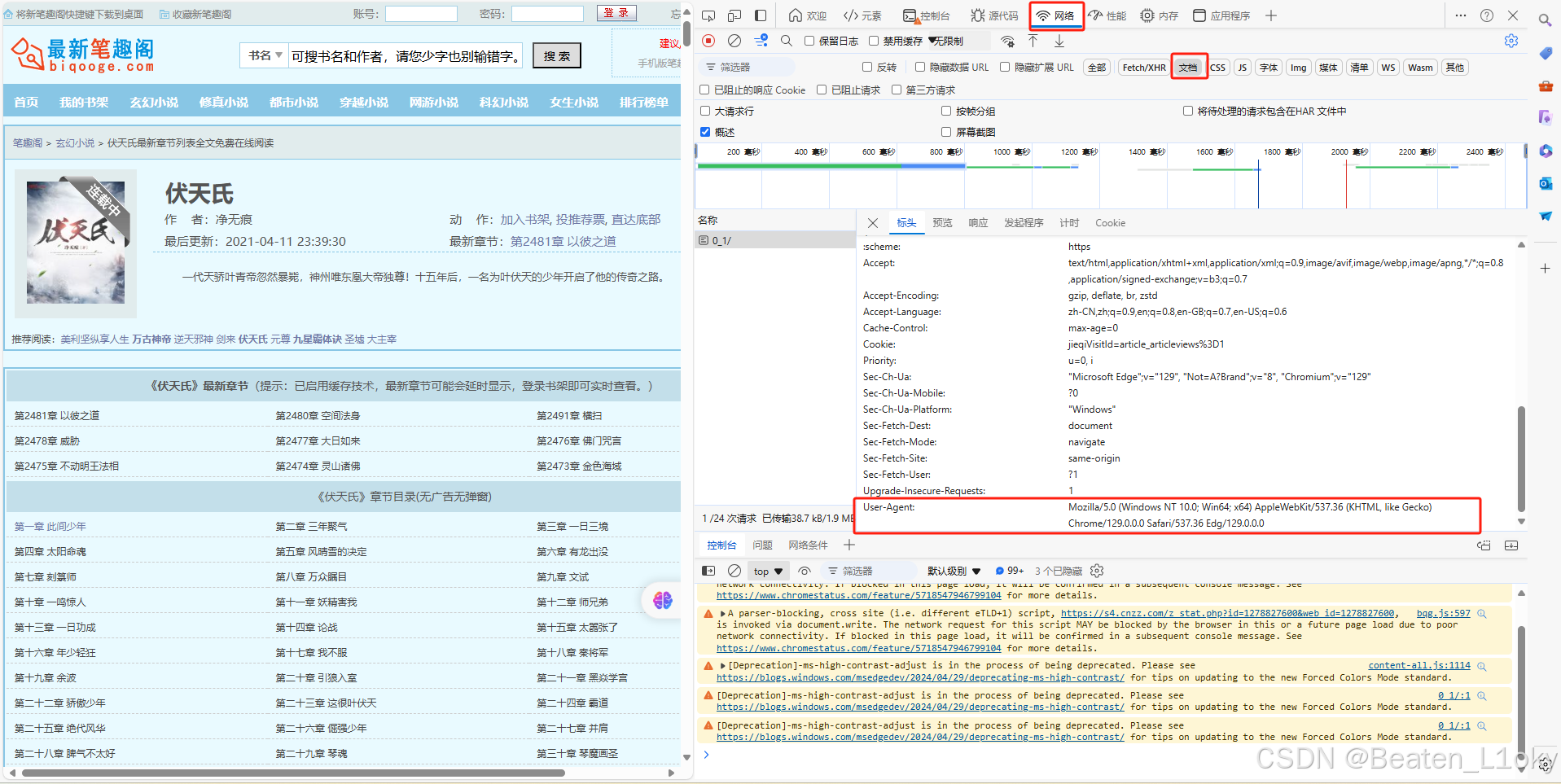
class Spider(object):
'''
此代码以伏天氏为例
'''
def __init__(self):
self.url = "https://www.biqooge.com/0_1/"#伏天氏,这里是要爬的书的网址
self.base_url = "https://www.biqooge.com/" #小说网站
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0"
}#刚刚复制的请求头
self.title = ""
self.output_path = r"E:\1.txt" #提前在本地建好txt文件
def get_pager_data(self):
try:
response = requests.get(self.url, headers=self.headers)
if response.status_code == 200:
# 自动检测编码
detected_encoding = chardet.detect(response.content)['encoding']
response.encoding = detected_encoding if detected_encoding else 'gbk' # 如果检测失败则默认使用GBK
'''事实上,该部分可以忽略掉,因为网站的编码是GBK
获取网站编码的方式:f12 -> 控制台 -> document.charset'''
return response.text
else:
print("请求失败,状态码:", response.status_code)
return None
except RequestException as e:
print("请求异常:", e)
return None
def parse_pager_index(self, html):
soup = BeautifulSoup(html, "lxml")
self.title = soup.select_one("#info h1").get_text() # 使用 select_one 更加明确
link_urls = soup.select("#list dd a")
# 确保只爬取包含 "第一章" 的链接
first_chapter_url = None
for link in link_urls:
if "第一章" in link.get_text():
first_chapter_url = link.get("href")
break
if first_chapter_url:
detail_html = self.get_detail_data(first_chapter_url)
if detail_html:
self.parse_detail_index(detail_html)
else:
print("无法获取第一章的内容")
else:
print("未找到第一章的链接")
def get_detail_data(self, link_url):
try:
full_url = self.base_url + link_url
response = requests.get(full_url, headers=self.headers)
if response.status_code == 200:
# 自动检测编码
detected_encoding = chardet.detect(response.content)['encoding']
response.encoding = detected_encoding if detected_encoding else 'gbk'
return response.text
else:
print("获取详细内容请求失败,状态码:", response.status_code)
return None
except RequestException as e:
print("获取详细内容请求异常:", e)
return None
def parse_detail_index(self, html):
soup = BeautifulSoup(html, "lxml")
bookname = soup.select_one(".bookname h1").get_text() # 获取章节标题
content = soup.select_one("#content").get_text().replace('\xa0', "").strip() # 获取章节内容,并去除不可见字符和多余的空白
print(f"正在保存章节:{bookname}")
self.save_detail_data(bookname, content)
def save_detail_data(self, bookname, text):
# 创建指定路径的文件夹,如果不存在的话
os.makedirs(os.path.dirname(self.output_path), exist_ok=True)
# 网站是GBK编码,写入txt会乱码,所以这里使用UTF-8编码,当然我的txt是UTF-8
with open(self.output_path, "w", encoding="utf-8", errors='ignore') as f:
f.write(f"{bookname}\n")
f.write(text)
def run(self):
html = self.get_pager_data()
if html:
self.parse_pager_index(html)
#在运行前需要关闭代理
def main():
spider = Spider()
spider.run()
if __name__ == '__main__':
main()
今天的分享就到这里,欢迎小伙伴在评论区交流!

















 1823
1823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









