







 本文深入探讨了xgboost作为boosting算法的工作原理,特别是其构建决策树的过程。通过贪心算法寻找最优分割点以降低目标损失,详细解释了分裂依据、时间复杂度以及如何处理缺失特征数据。此外,讨论了二阶导数在xgboost中的作用和优势,并指出xgboost支持多种目标损失函数。
本文深入探讨了xgboost作为boosting算法的工作原理,特别是其构建决策树的过程。通过贪心算法寻找最优分割点以降低目标损失,详细解释了分裂依据、时间复杂度以及如何处理缺失特征数据。此外,讨论了二阶导数在xgboost中的作用和优势,并指出xgboost支持多种目标损失函数。
两大集成学习的框架:bagging 和 boosting。xgboost 是属于boosting系列的算法。
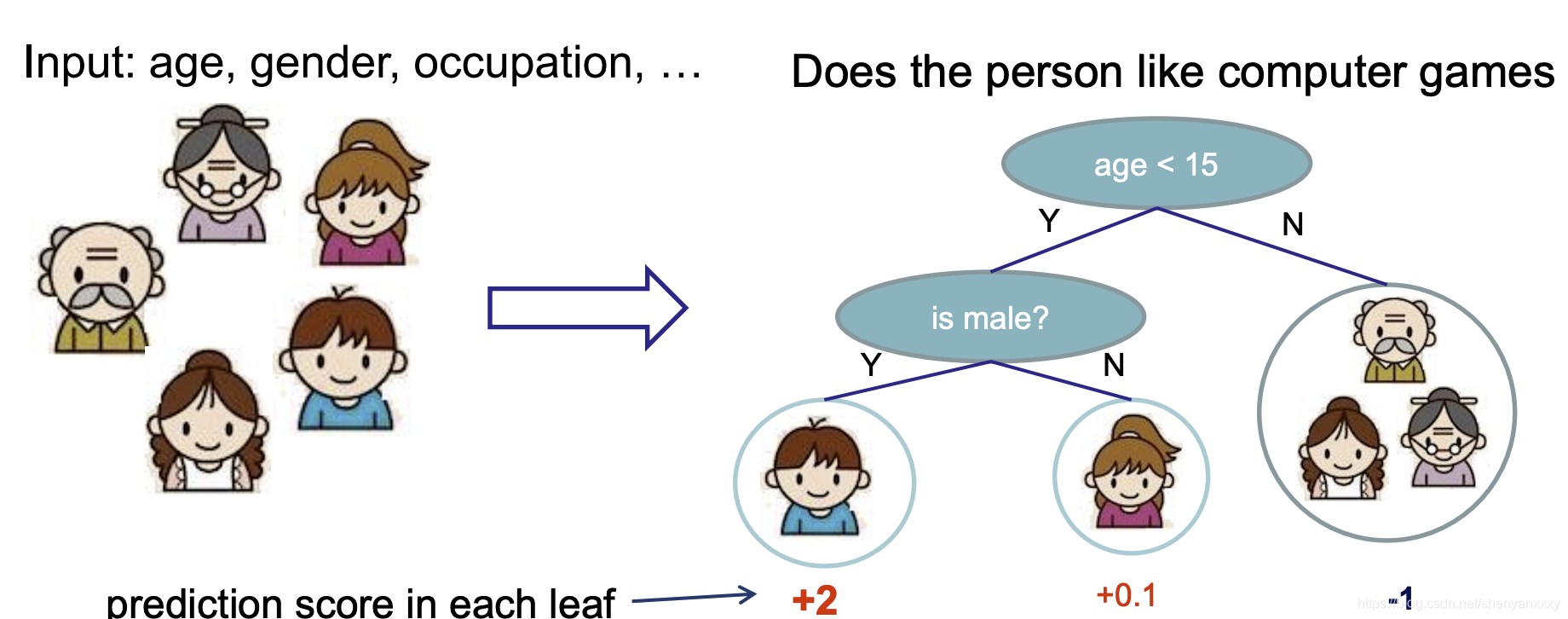
这篇文章主要介绍一下,xgboost 模型的训练过程。
从宏观来说,就是创建一棵树拟合目标函数,期望loss 最小,然后构建另外一个树来拟合前面所有树的残差。
那从每一棵树来说,它是如何构造一棵树的呢。具体的
从第0层开始,如果分裂能够比不分裂带来提升,那么就选择分裂,看一下。所以在分裂的过程当中就考虑了 normalization。
首先,1) 只有一个节点,这个节点是包含了所有的训练数据,也就是不分裂,只有一个叶子节点,那么这个叶子节点的分数应该是。
举个例子,下面这个图是从原始的无分裂的状态,分裂了两次之后的结果。
下面看xgboost 是根据什么来选择是否分裂的?xgboost 使用了贪心算法。其实是根据当前的每个feature的每个split 进行 object gain 评估。选择能够降低目前的object loss 最好的点,也就是Gain (收益)最大的点。
1) 遍历所有的feature 1....d
2) 遍历每个feature 的 split point,计算object gain。
3) 找到最大的split point,然后那个点就是当前最好的选择。如果所有的选择都只带来negative gain的ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6652
6652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









