







目录
前面学习的:CNN便于处理位置相关性,对于时间维度的信号序列,使用RNN处理,在时间维度上共享权值;
无监督学习
监督学习,采用有标注的数据进行模型的训练;
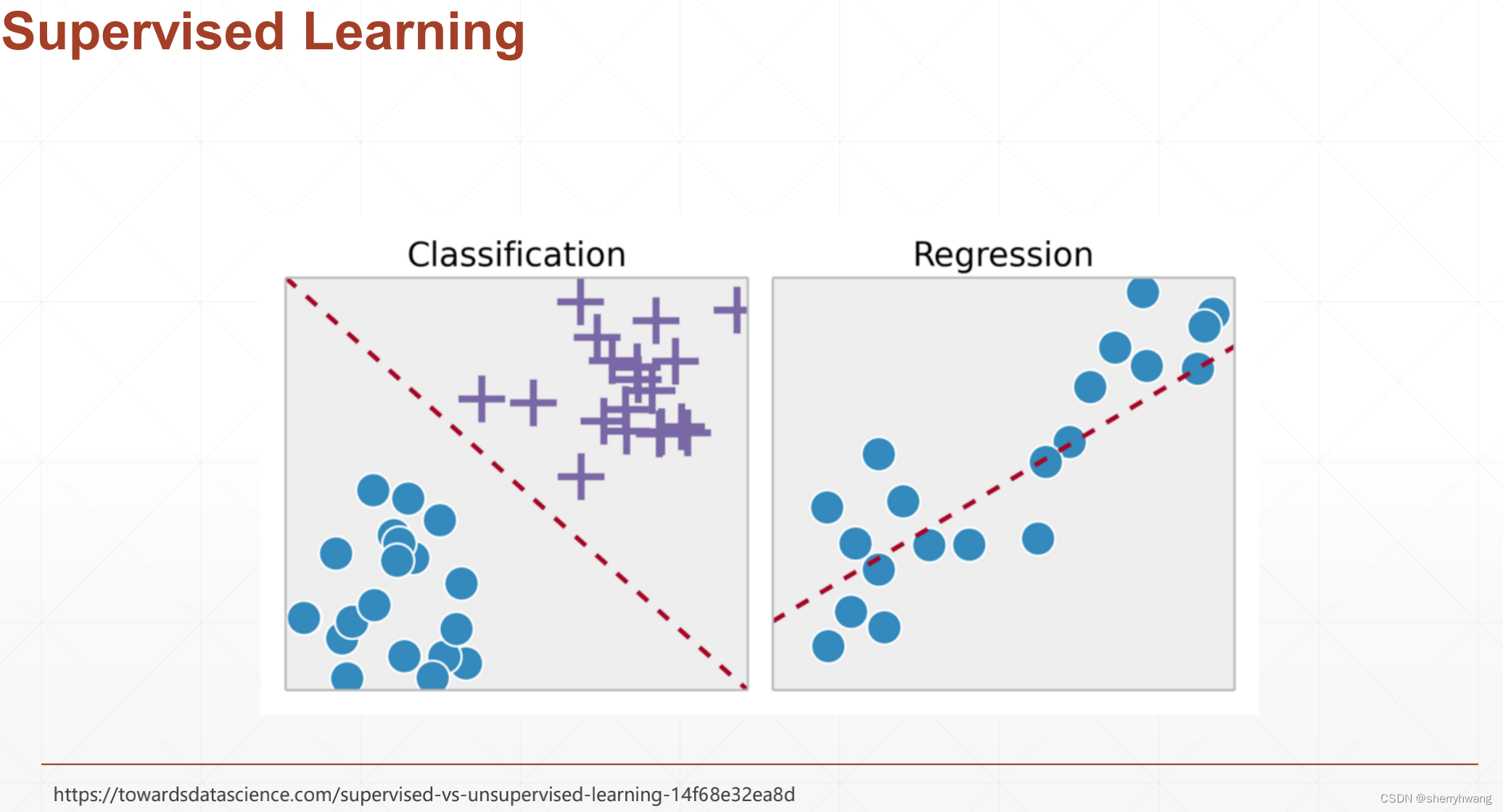
实际情况下,存在许多未标注的数据;

无监督学习的需求;
- 数据降维;
重建自己,中间的更低维变量就是降维后的数据; - 可视化;将高维数据投影到二维三维以可视化;
- 利用无监督数据;
- 压缩、去噪、超分辨率;

AutoEncoder
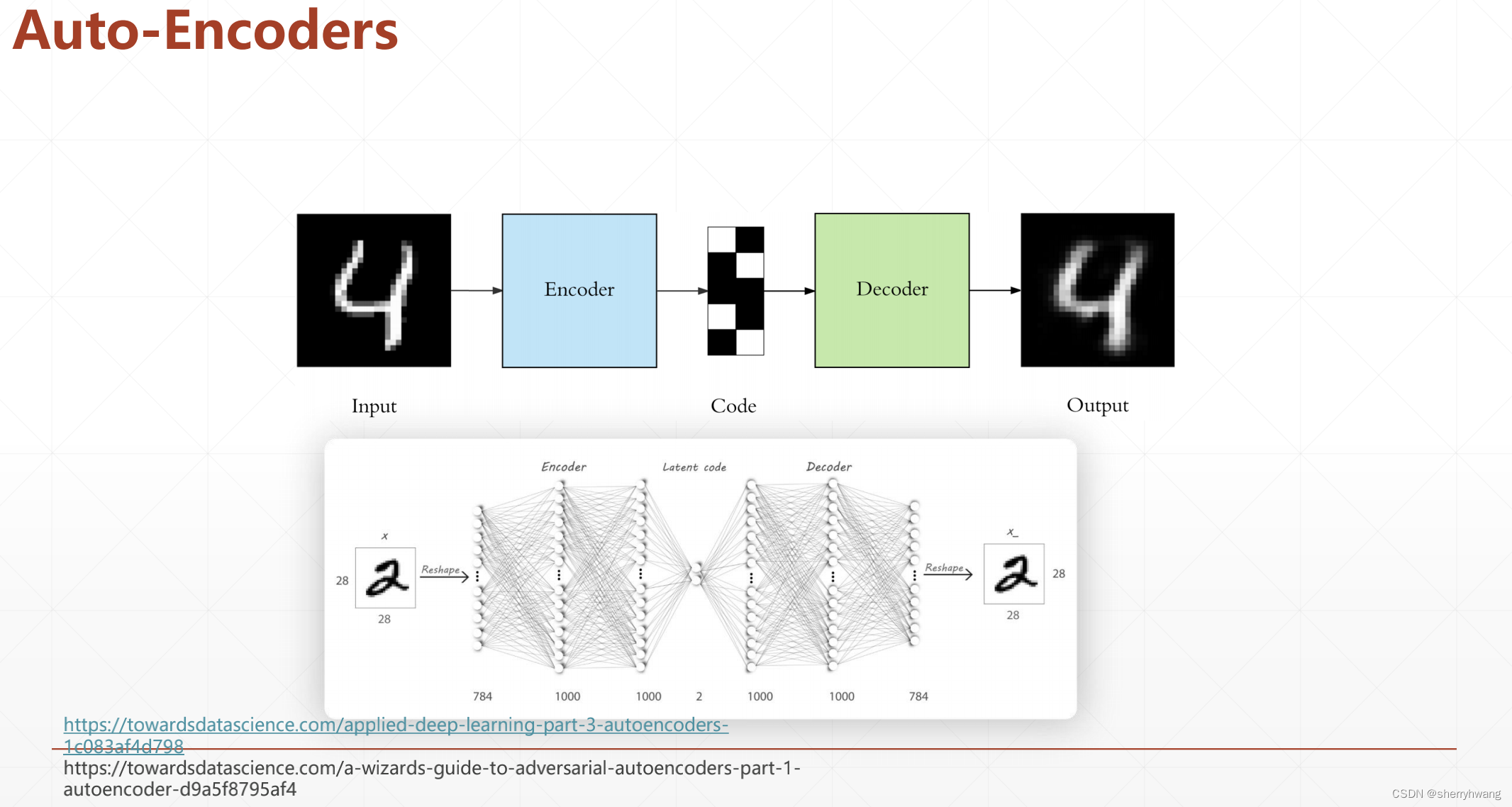
AE的训练;
MNIST数据的输入就是0和1,适合CE损失,也适合MSE损失;

PCA和Auto-Encoder
PCA是线性变换,可操作空间比较少;

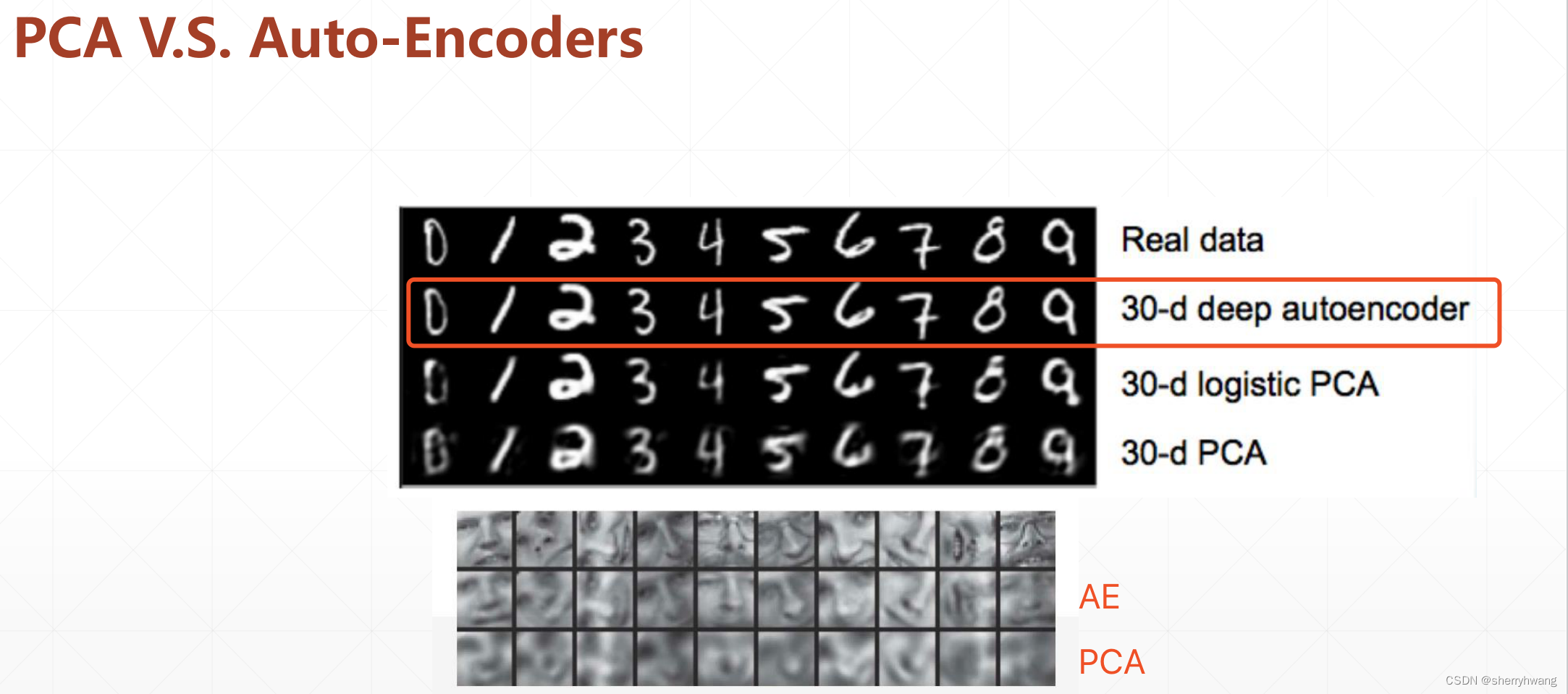
左图:利用PCA和AE将图像数据MNIST降到二维,可视化,左边降维后的数据区分不是特别好,而AE就区分得比较清晰;
右图:文本数据降维可视化;

denoising AutoEncoders 去噪自编码器
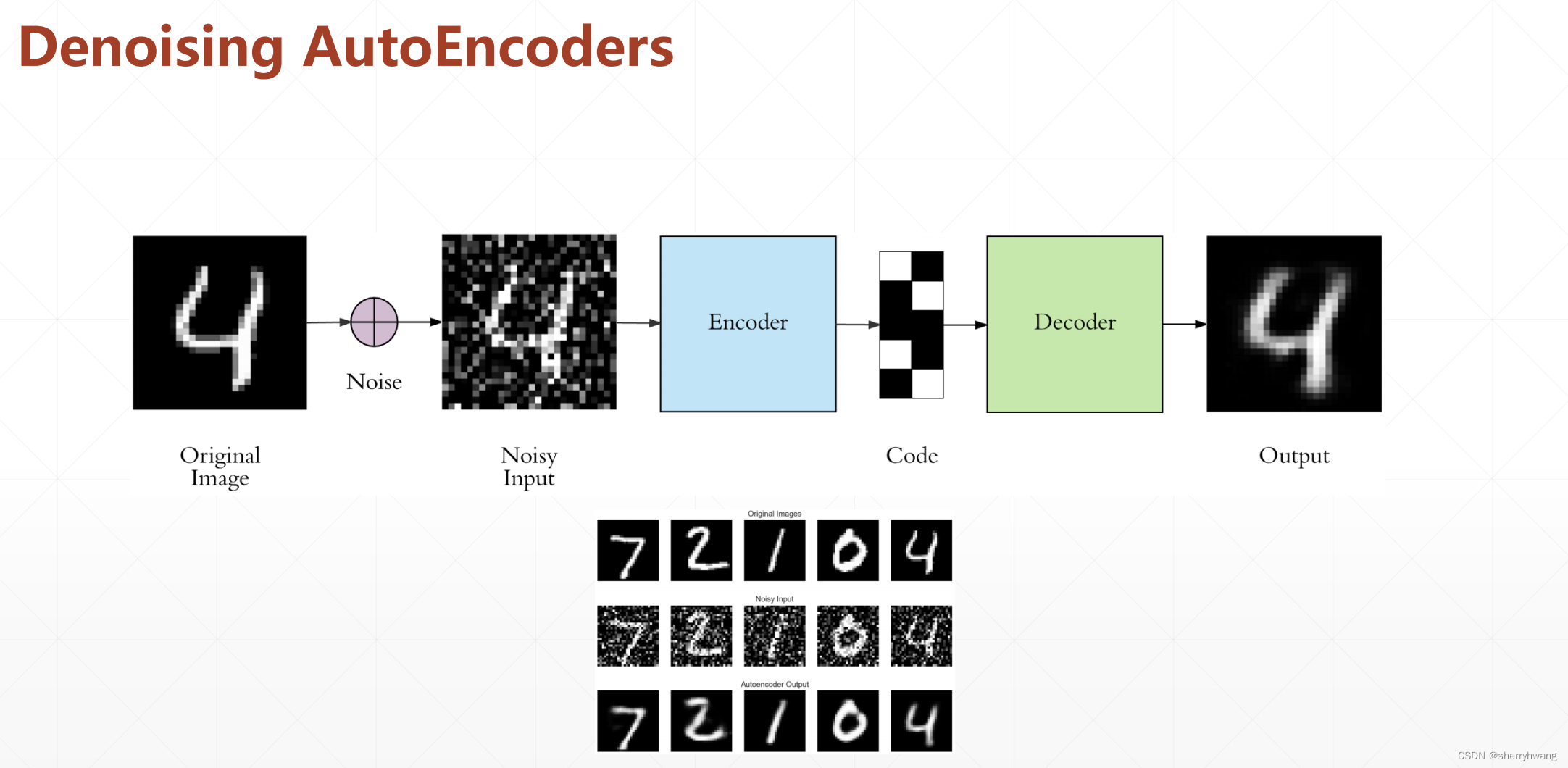
去噪自动编码器;
在输入数据上添加一个高斯噪声,使模型重构原始的数据,学习数据真正的分布;
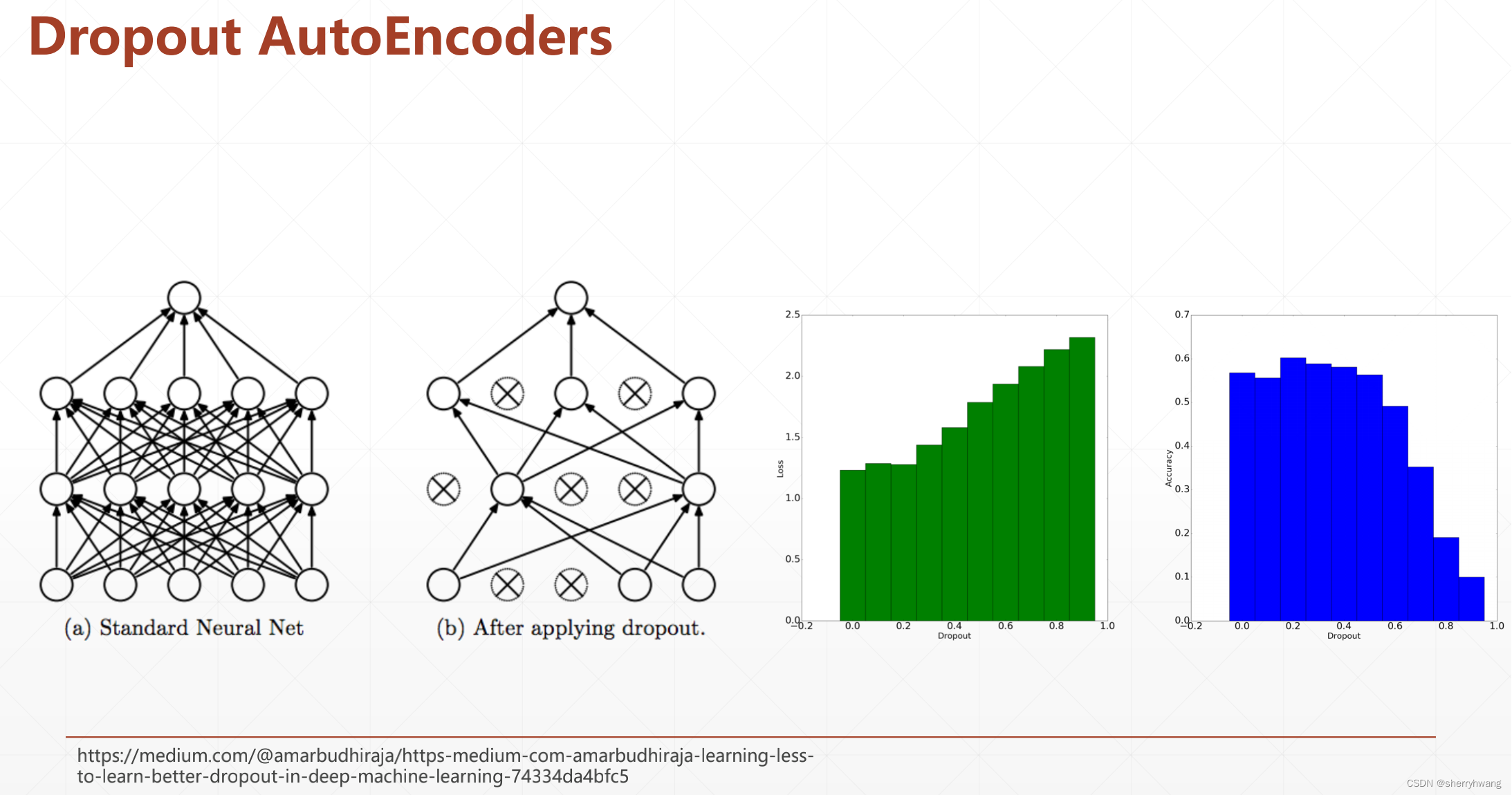
Dropout AutoEncoder
dropout=0,容易过拟合,所以acc可能不是最高的,dropout=1,欠拟合,acc比较低;
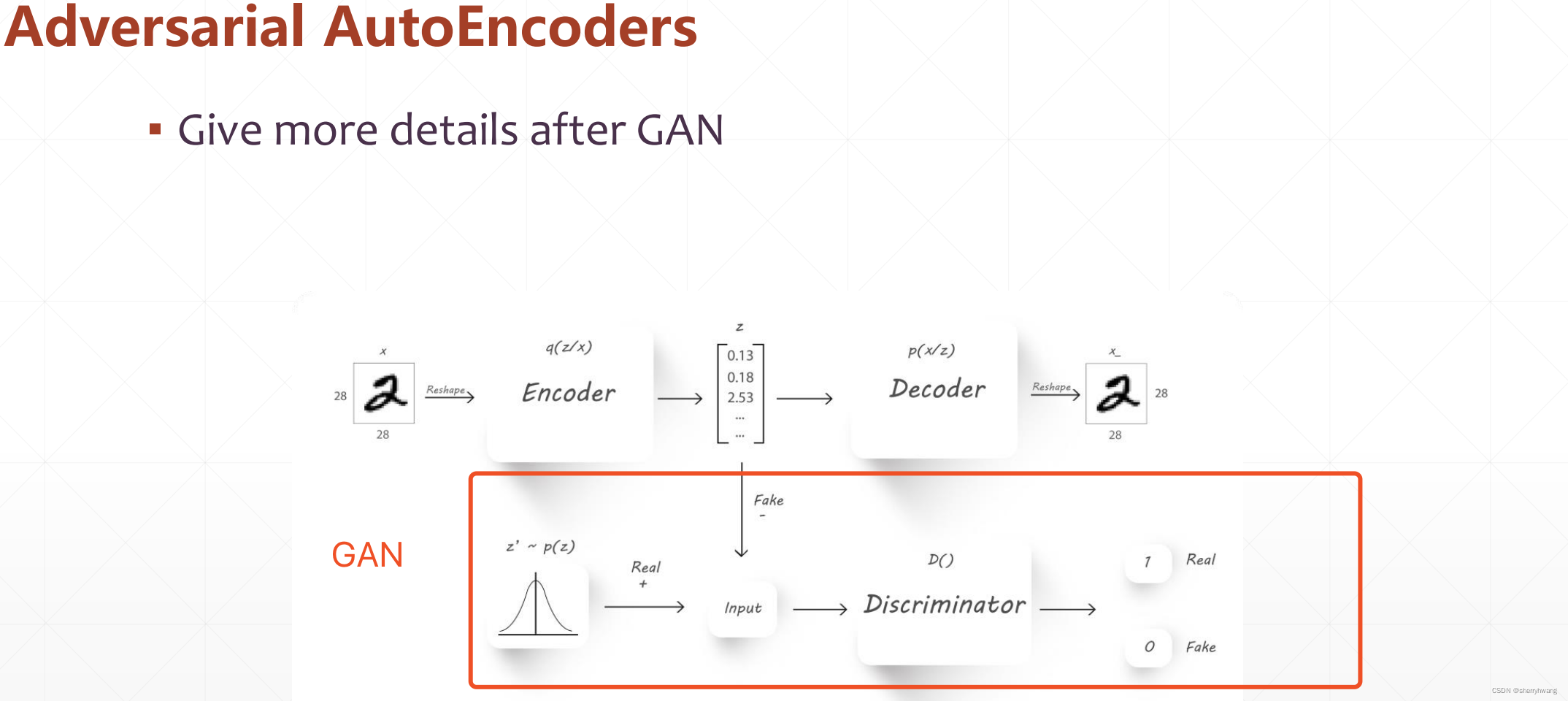
Adversarial AutoEncoder 对抗自编码器
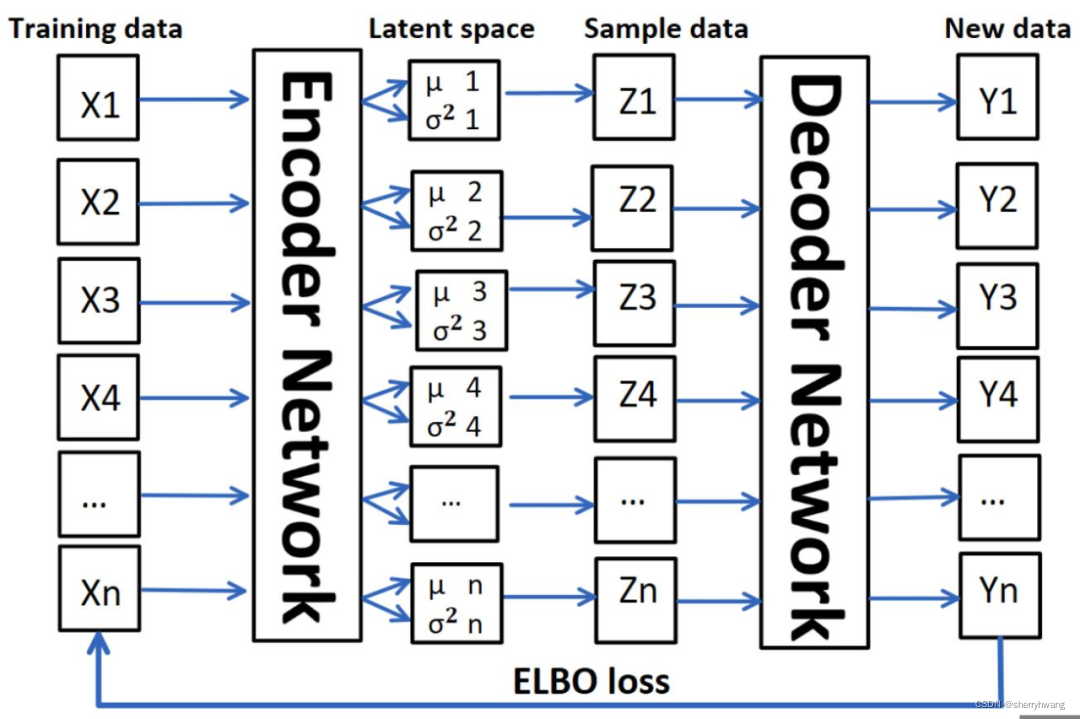
Variational AutoEncoder 变分自编码器
变分自动编码器;学习隐变量的空间分布(
N
i
N_i
Ni,
σ
i
2
\sigma_i^2
σi2);中间有一个从分布(
N
i
N_i
Ni,
σ
i
2
\sigma_i^2
σi2)采样的过程,根据采样出的具体隐变量重构输入。(如果控制n个分布的采样值,那么则可以重构自己想要的数据?)
x->(
N
i
N_i
Ni,
σ
i
2
\sigma_i^2
σi2)->sample(i)->reconstruction(i)
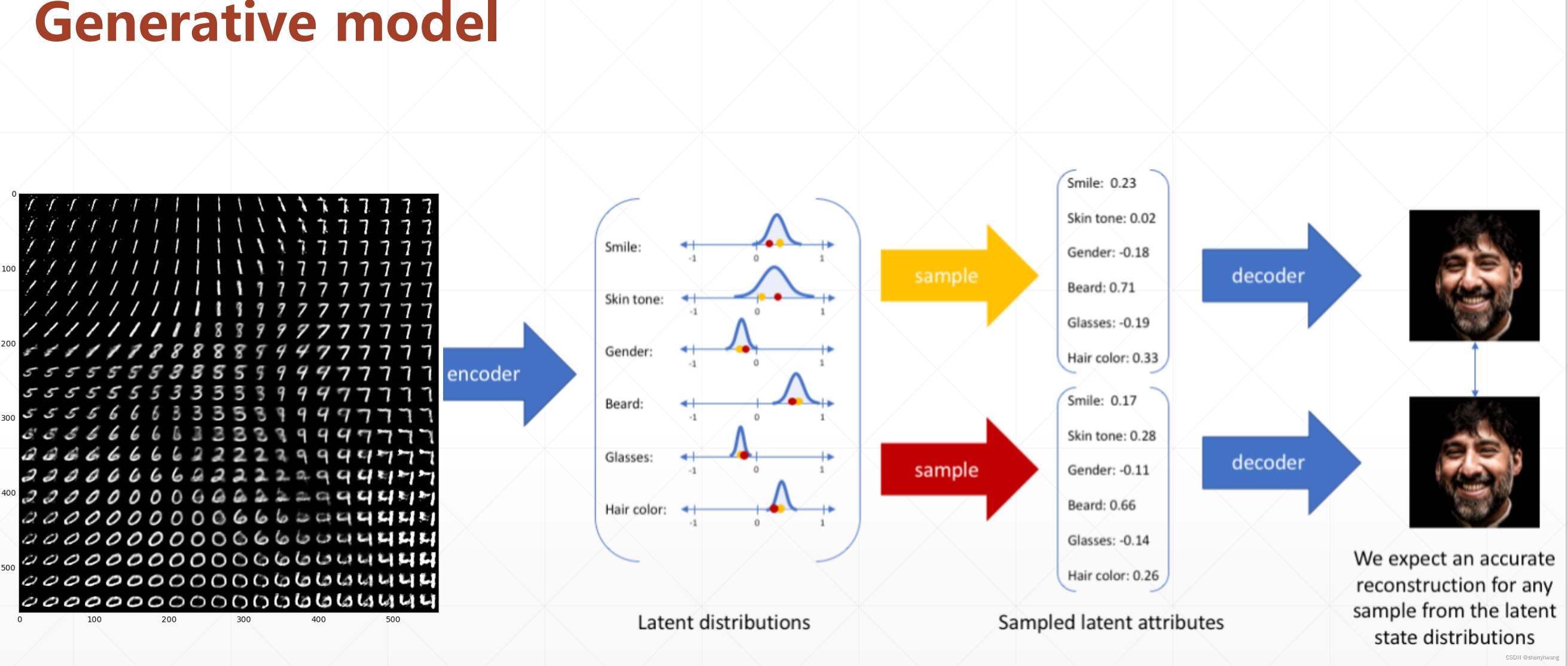
编码器计算每个输入数据的低维均值μ和方差,然后从隐变量空间采样,得到Z={Z1,Z …,Zn},通过解码器生成新数据Y ={Y1,Y2…,Yn}。

损失函数包含两部分,一个是autoencoder的重建误差,一个是
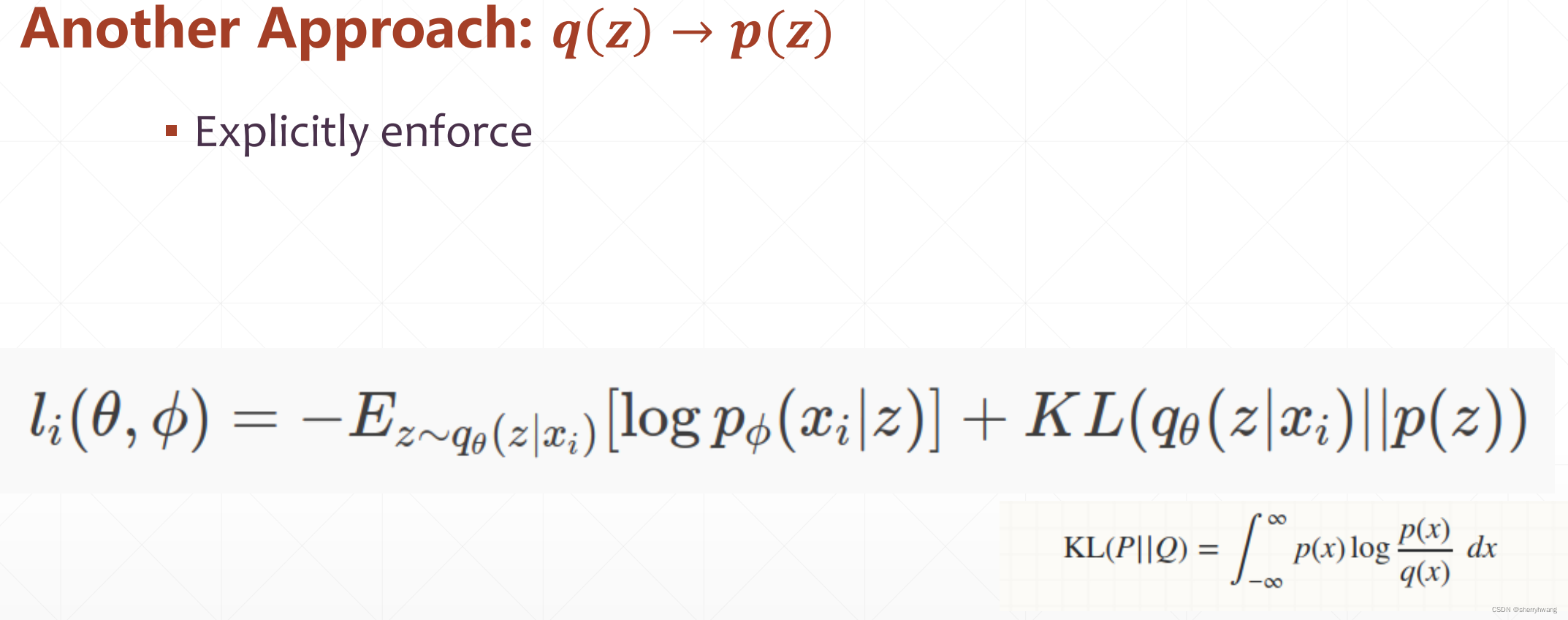

AE重建误差:

KL散度:
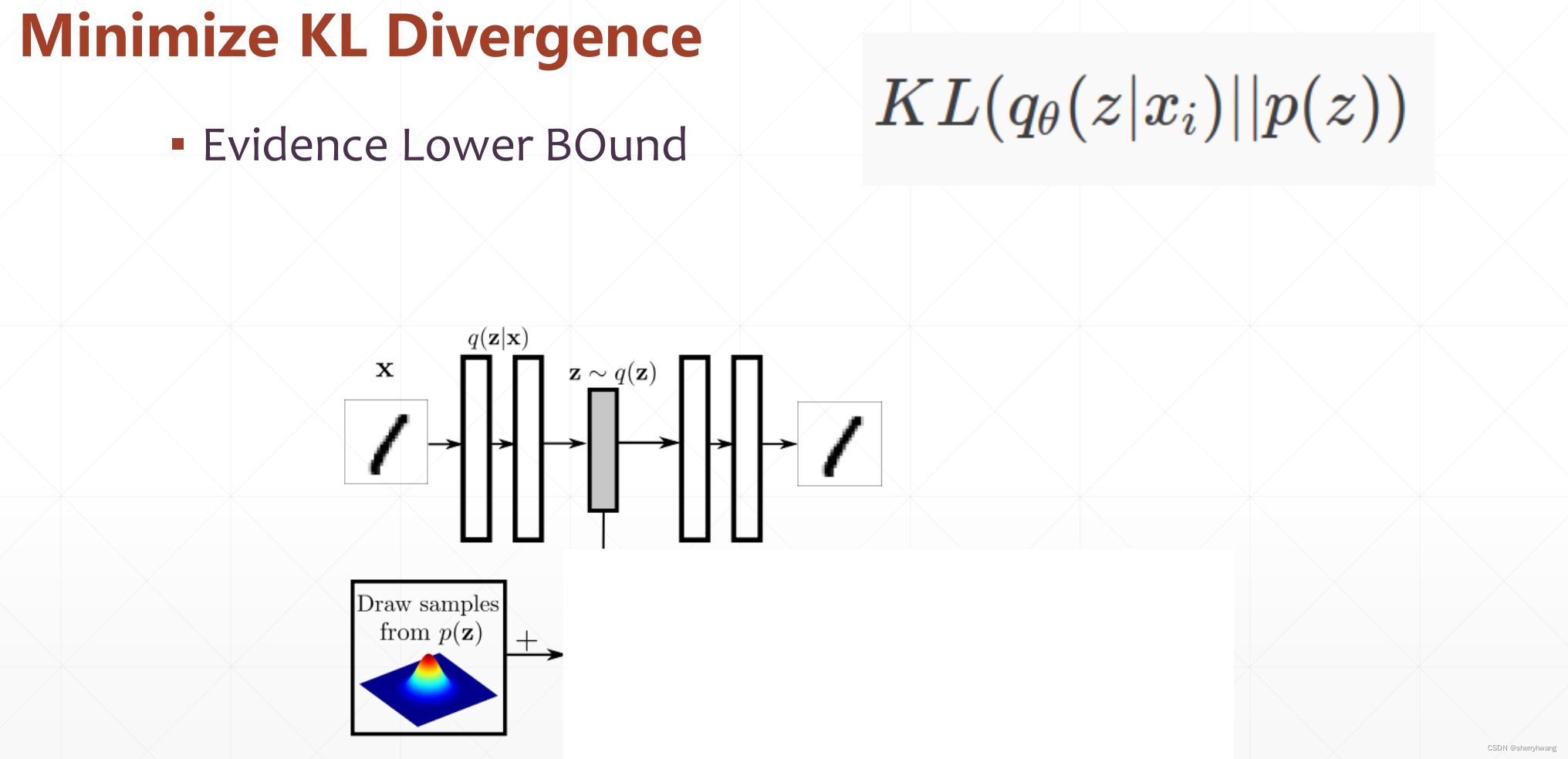
假如z和目标分布都是正态分布,KL散度计算如下:
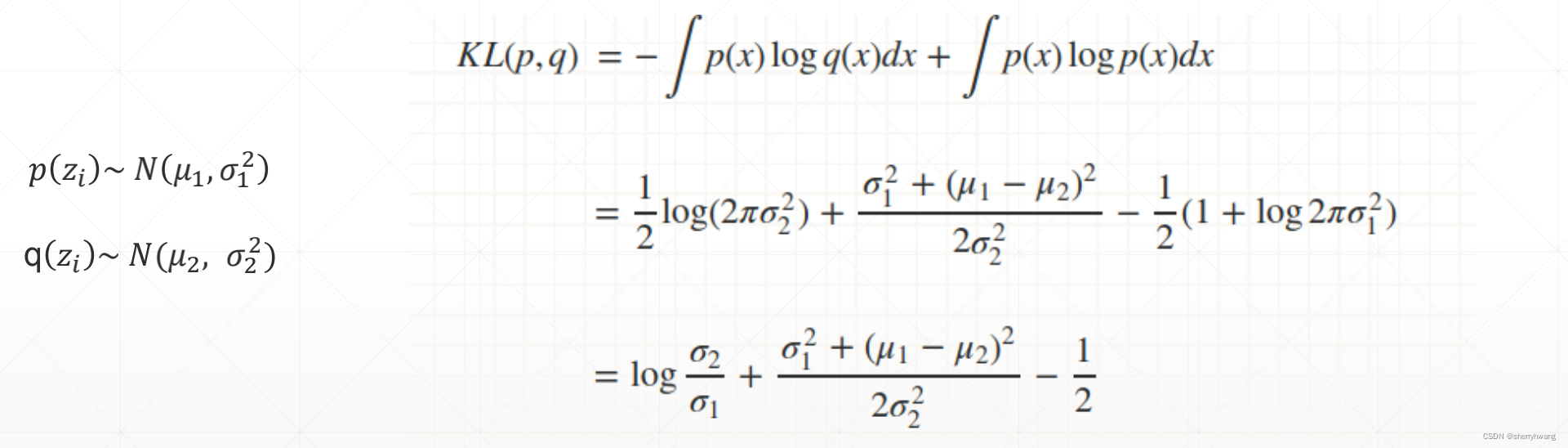
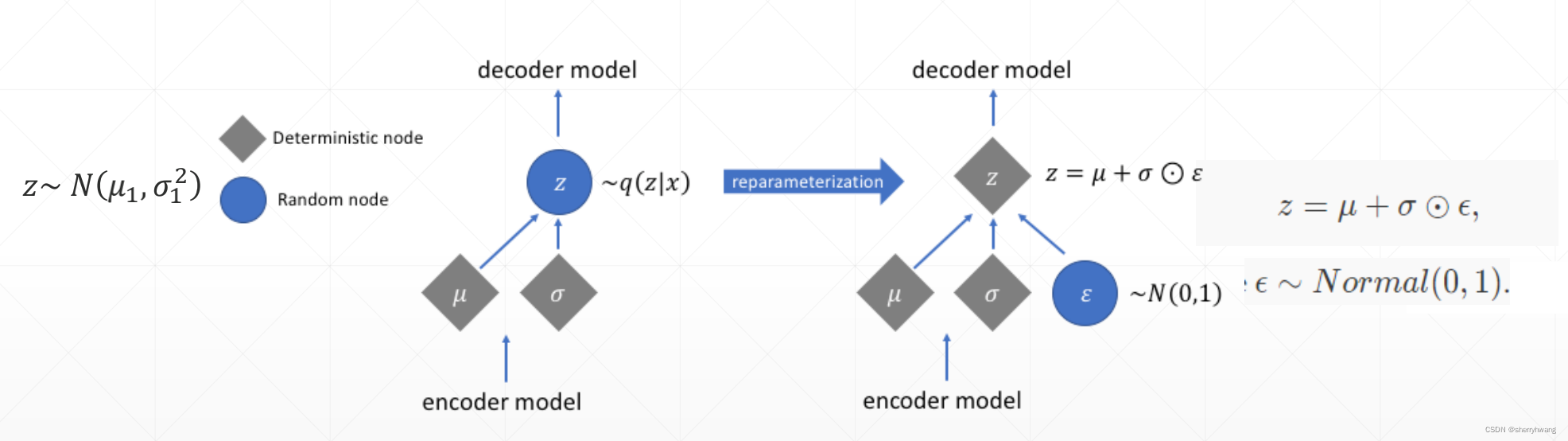
Reparameterization VAE的隐变量的重参数化
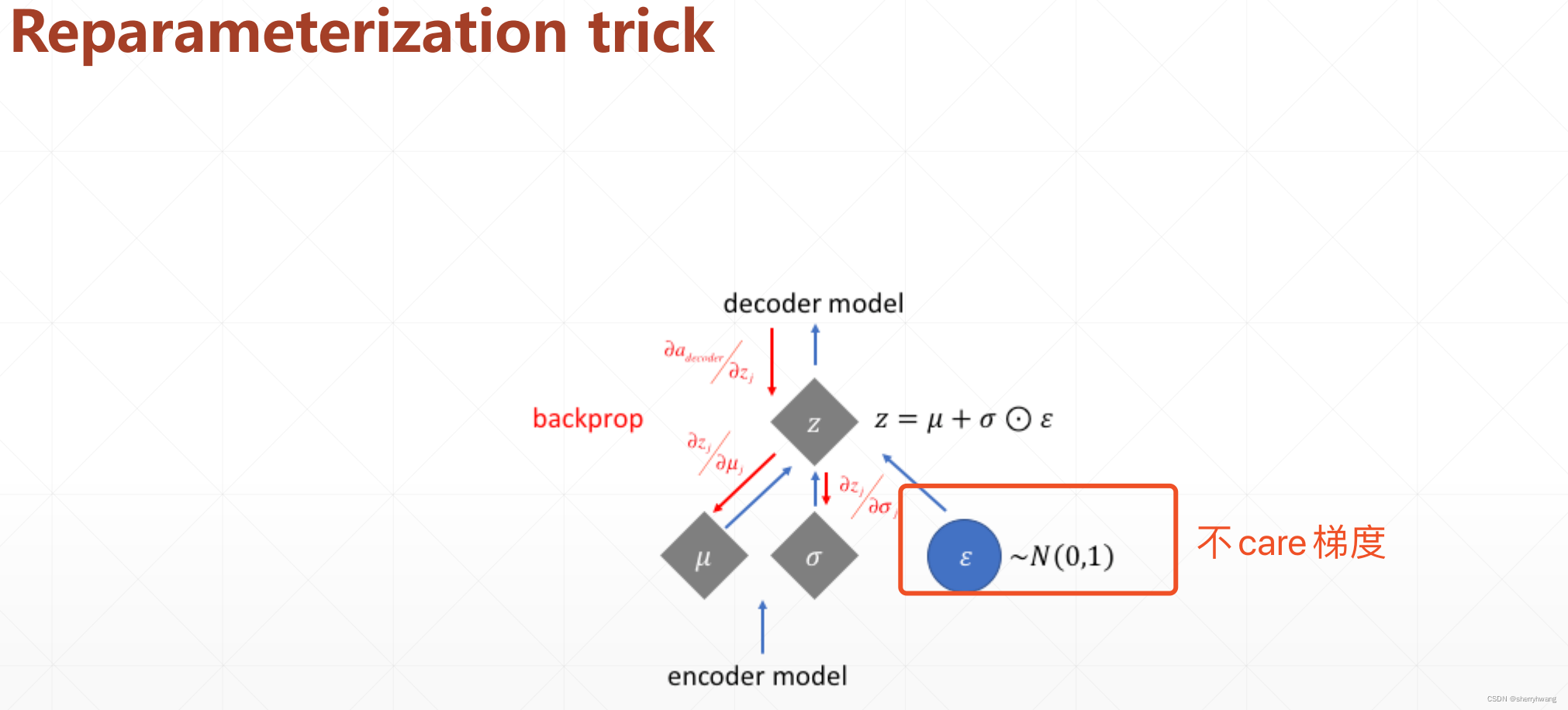
AE 编码器生成每个输入数据的一一对应的确定的隐变量;而VAE生成每个输入数据对应的隐变量是一个均值和方差(代表了一个分布),它代表了一个分布(隐变量空间),因此从这个分布重建输入数据的时候,需要采样数;这个采样过程是不可微的,因此需要reparameterization这个技巧,将采样数据重新参数化,使得这个采样样本可以参与网络的梯度计算中来。具体过程如下:
VAE生成模型
假设encoder中间生成两个隐变量的空间分布(
N
0
N_0
N0,
σ
0
2
\sigma_0^2
σ02)和(
N
1
N_1
N1,
σ
1
2
\sigma_1^2
σ12),即encoder输出
N
0
N_0
N0,
σ
0
\sigma_0
σ0和
N
1
N_1
N1,
σ
1
\sigma_1
σ1四个数值,从这两个分布中随机采样得到
h
0
h_0
h0和
h
1
h_1
h1,根据不同
h
0
h_0
h0和
h
1
h_1
h1可以得到不同的生成数据;
同理可以生成n个空间分布(
N
i
N_i
Ni,
σ
i
2
\sigma_i^2
σi2),从n个空间分布中随机采样n个隐变量,生成不同的数据;

AutoEncoder实战
ae.py:
import torch
import torch.nn as nn
class AutoEncoder(nn.Module):
def __init__(self) -> None:
super().__init__()
# [b, 784]
self.encoder = nn.Sequential(
nn.Linear(784,256),
nn.ReLU(inplace=True),
nn.Linear(256,64),
nn.ReLU(inplace=True),
nn.Linear(64,20),
nn.ReLU(inplace=True)
)
self.decoder = nn.Sequential(
nn.Linear(20,64),
nn.ReLU(inplace=True),
nn.Linear(64,256),
nn.ReLU(inplace=True),
nn.Linear(256,784),
nn.Sigmoid(),
)
def forward(self, x):
x = x.flatten(1)
x = self.encoder(x)
x = self.decoder(x)
x = x.view(-1,1,28,28)
return x
mian.py
from random import shuffle
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
from ae import AutoEncoder
import visdom
def main():
mnist_train = datasets.MNIST('data/',train=True, download=True, transform=transforms.Compose([
transforms.ToTensor()]
))
mnist_test = datasets.MNIST('data/',train=False, download=True, transform=transforms.Compose([
transforms.ToTensor()]
))
train_loader = DataLoader(mnist_train, batch_size = 32, shuffle=True)
test_loader = DataLoader(mnist_test, batch_size = 32, shuffle=False)
x,y = iter(train_loader).next()
print(x.shape)
device = torch.device('cpu')
model = AutoEncoder().to(device)
criteon = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr = 1e-3)
vis = visdom.Visdom()
for epoch in range(1000):
for batch_idx, (x,y) in enumerate(train_loader):
x,y = x.to(device), y.to(device)
x_hat = model(x)
loss = criteon(x_hat, x)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch, 'loss:', loss.item())
x,y = iter(test_loader).next()
with torch.no_grad():
x_hat = model(x)
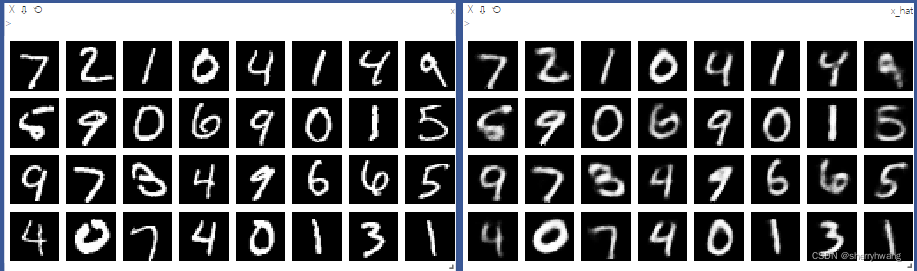
vis.images(x, nrow = 8, win = 'x-ae', opts = dict(title = 'x'))
vis.images(x_hat, nrow = 8, win = 'x-hat', opts = dict(title = 'x_hat'))
if __name__ == '__main__':
main()
visdom可视化结果:
Variational AutoEncoder实战
vae. 使中间变量逼近0-1正态分布;
import torch
import torch.nn as nn
import numpy as np
class VarAutoEncoder(nn.Module):
def __init__(self) -> None:
super().__init__()
# [b, 784] -> u: [b, 10] sigma: [b 10]
self.encoder = nn.Sequential(
nn.Linear(784,256),
nn.ReLU(inplace=True),
nn.Linear(256,64),
nn.ReLU(inplace=True),
nn.Linear(64,20),
nn.ReLU(inplace=True)
)
self.decoder = nn.Sequential(
nn.Linear(10,64),
nn.ReLU(inplace=True),
nn.Linear(64,256),
nn.ReLU(inplace=True),
nn.Linear(256,784),
nn.Sigmoid(),
)
def forward(self, x):
batchsz = x.size(0)
x = x.flatten(1)
h_mu_sigma = self.encoder(x) #[b, 20] uncluding mean and sigma
mu, sigma = h_mu_sigma.chunk(2, dim = 1) #将h_mu_sigma在dim=1的维度上拆成两个tensor
# reparameterize trick, epison~N(0,1)
h = mu + sigma * torch.rand_like(sigma) #生成可导的sample h
kld = 0.5 * torch.sum(
torch.pow(mu, 2) +
torch.pow(sigma,2) -
torch.log(1e-8 + torch.pow(sigma, 2)) -1
) / batchsz #h分布与0-1正态分布之间的KL loss
x_hat = self.decoder(h)
x_hat = x_hat.view(-1,1,28,28)
return x_hat, kld
main.py
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
from ae import AutoEncoder
from vae import VarAutoEncoder
import visdom
def main():
mnist_train = datasets.MNIST('data/',train=True, download=True, transform=transforms.Compose([
transforms.ToTensor()]
))
mnist_test = datasets.MNIST('data/',train=False, download=True, transform=transforms.Compose([
transforms.ToTensor()]
))
train_loader = DataLoader(mnist_train, batch_size = 32, shuffle=True)
test_loader = DataLoader(mnist_test, batch_size = 32, shuffle=False)
x,y = iter(train_loader).next()
print(x.shape)
device = torch.device('cpu')
model = VarAutoEncoder().to(device)
criteon = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr = 1e-3)
vis = visdom.Visdom()
for epoch in range(1000):
for batch_idx, (x,y) in enumerate(train_loader):
x,y = x.to(device), y.to(device)
x_hat, kld = model(x)
loss = criteon(x_hat, x)
if kld is not None:
elbo = - loss - 1.0 * kld
loss = -elbo
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch, 'loss:', loss.item())
x,y = iter(test_loader).next()
with torch.no_grad():
x_hat = model(x)
vis.images(x, nrow = 8, win = 'x-ae', opts = dict(title = 'x'))
vis.images(x, nrow = 8, win = 'x-hat', opts = dict(title = 'x_hat'))
from random import shuffle
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
from ae import AutoEncoder
from vae import VarAutoEncoder
import visdom
def main():
mnist_train = datasets.MNIST('data/',train=True, download=True, transform=transforms.Compose([
transforms.ToTensor()]
))
mnist_test = datasets.MNIST('data/',train=False, download=True, transform=transforms.Compose([
transforms.ToTensor()]
))
train_loader = DataLoader(mnist_train, batch_size = 32, shuffle=True)
test_loader = DataLoader(mnist_test, batch_size = 32, shuffle=False)
x,y = iter(train_loader).next()
print(x.shape)
device = torch.device('cpu')
model = VarAutoEncoder().to(device)
criteon = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr = 1e-3)
vis = visdom.Visdom()
for epoch in range(1000):
for batch_idx, (x,y) in enumerate(train_loader):
x,y = x.to(device), y.to(device)
x_hat, kld = model(x)
loss = criteon(x_hat, x)
if kld is not None:
elbo = - loss - 0.01 * kld
loss = -elbo
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch, 'loss:', loss.item(), 'kld loss:', 0.01*kld.item())
x,y = iter(test_loader).next()
with torch.no_grad():
x_hat, kld = model(x)
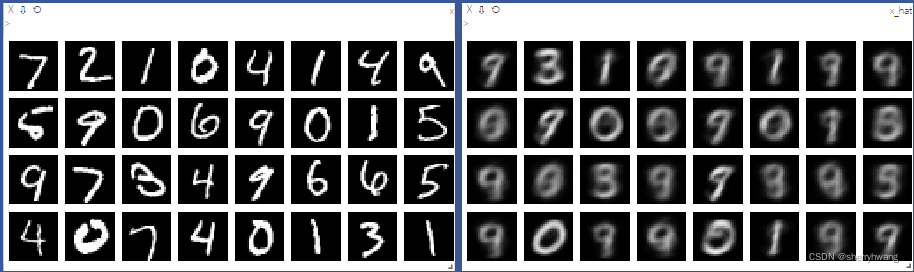
vis.images(x, nrow = 8, win = 'x-ae', opts = dict(title = 'x'))
vis.images(x_hat, nrow = 8, win = 'x-hat', opts = dict(title = 'x_hat'))
if __name__ == '__main__':
main()
VAE需要更多时间去训练。
visdom可视化:














 1741
1741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









