







在当今的深度学习领域中,自动编码器(Autoencoder)是一种常见的无监督学习神经网络模型,用于学习有效的数据表示。自动编码器在许多领域都有广泛的应用,包括特征提取、降维、图像去噪、生成模型等。
自动编码器的基本原理
自动编码器的基本原理是通过将输入数据编码为隐含变量(也称为编码)然后解码回原始数据来重建输入。它由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器将输入数据映射到低维表示空间,解码器将这个低维表示映射回原始数据空间。
自动编码器的工作流程
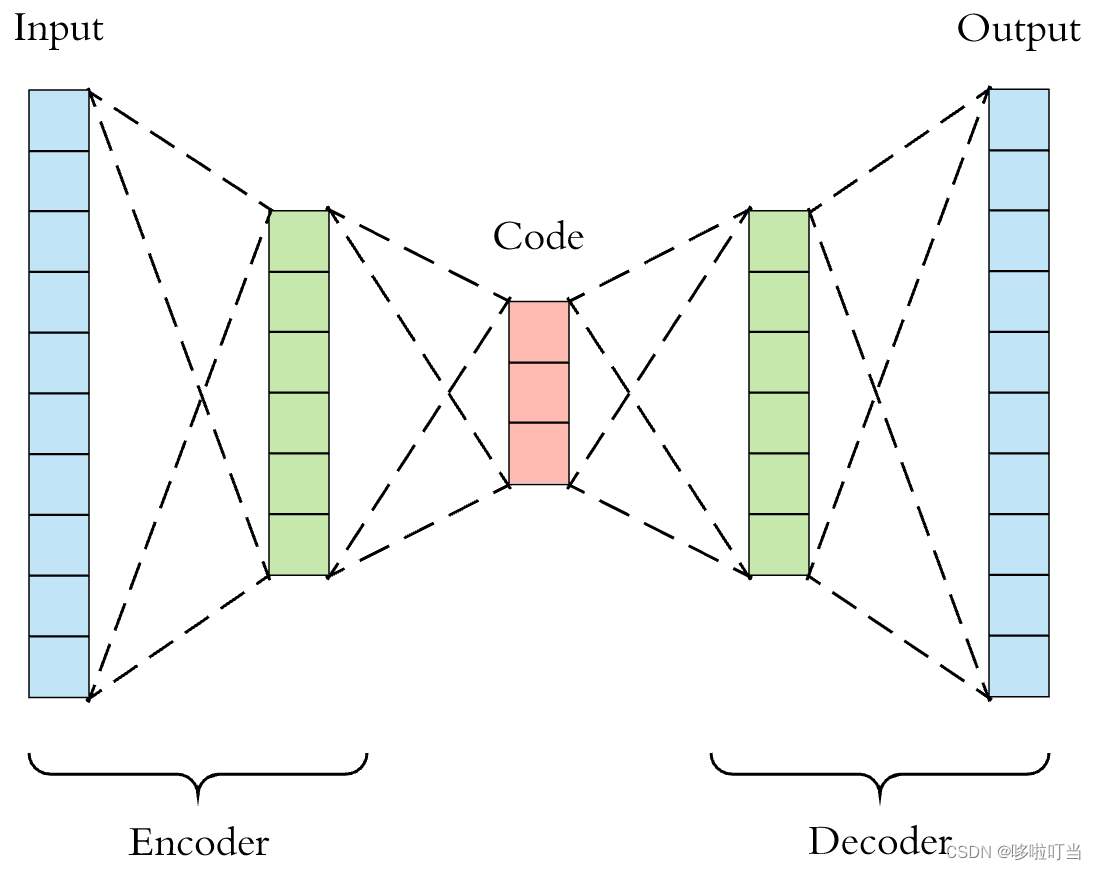
编码器Encoder
将输入数据(如图像、文本等)通过神经网络转换为低维表示,捕获输入数据中的关键特征。
解码器Decoder
解码器接收编码器生成的低维表示,并尝试从中重建原始输入数据。
训练过程
在训练过程中,自动编码器通过最小化重建误差(输入数据与解码器输出之间的差异)来学习数据的表示。
自动编码器的用途
自动编码器在以下几个方面具有广泛的应用:
1. 特征学习:通过学习数据的有用表示,自动编码器可以用于特征学习任务,有助于提高监督学习模型的性能。
2. 降维:自动编码器可以将高维数据映射到低维空间,从而实现数据的降维,有助于可视化和减少计算复杂度。
3. 图像去噪:通过训练自动编码器来学习对输入数据的干净表示,可以用于去除图像中的噪声。
4. 生成模型:通过改变自动编码器的架构,可以设计生成对抗网络(GAN)等生成模型。
自动编码器的变体
除了基本的自动编码器之外,还有一些变体:
稀疏自动编码器(Sparse Autoencoder)
稀疏自动编码器是一种自动编码器变体,旨在学习数据的稀疏表示。通过引入稀疏性约束,这种自动编码器使得中间层的表示中只有少数神经元是激活的,从而有效地捕获数据的关键特征。虽然中间维度通常比输入维度和输出维度高,但实际上有效维度是很少的,这有助于提取出数据中的重要信息。
在稀疏自动编码器中,优化目标通常包括最小化重建误差(例如均方误差)以及稀疏性约束。稀疏性约束可以通过L1正则化项或者其他稀疏性惩罚来实现,促使模型学习对输入数据进行稀疏编码。
去噪自动编码器(Denoising Autoencoder)
去噪自动编码器是一种特殊类型的自动编码器,用于从带有噪声的输入数据中还原干净数据。训练模型时,输入数据被加入不同形式的噪声(例如高斯噪声、dropout等),使得模型学会抵抗噪声的影响,在还原数据时更加鲁棒和准确。
通过训练去噪自动编码器,模型可以学习到数据中的真正模式,从而在应对真实世界数据中的噪声和缺失情况时表现更好。对于图像数据,去噪自动编码器也可以用于预测和填补图像中缺失的部分。
变分自动编码器(VAE)
变分自动编码器是一种结合了自动编码器和概率建模思想的模型,用于学习数据的潜在空间表示和生成新样本。在VAE中,我们假设一个潜在变量z的先验分布p(z),通过观察到的数据x来推断后验分布p(z|x)。然而,当z的维度很高时,精确计算后验分布p(z|x)的复杂度很高,因此需要设计一个近似分布q(z|x)来近似p(z|x)。
在训练过程中,VAE通过最大化数据的边际对数似然,同时最小化近似后验分布q(z|x)与先验分布p(z)之间的KL散度,从而学习到数据的潜在表示。VAE可以用于生成新样本,实现从一个潜在空间中采样并解码生成新的数据样本,具有很高的创造性和应用潜力。
在深度学习的探索中,自动编码器为我们提供了一种强大的工具,有助于学习数据的有用表示并推动各种领域的创新应用。

















 1505
1505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











