







决定认真学习Andrew Ng的机器学习课程,我想写下来既可以给自己日后一个参考,也可以有个动力,同时帮助理解吧,总之,希望自己坚持下去!
一、introduction
1、what is machine learning
对一个计算机程序而言,给它一个任务T和性能度量方式P,通过对经验E的反馈使得P对T的度量结果得到改进,就说该程序从经验E中学习了。
主要分为有监督学习和无监督学习。
2、有监督学习
用房价预测的例子来引出有监督学习的概念,很直观。
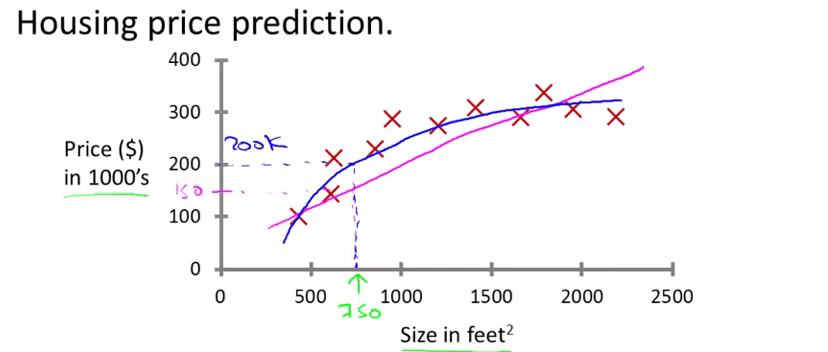
红叉为已经给出的房价和面积的坐标值,根据这些已知的数据,我们如何通过机器学习来实现给出面积就推测出房价。紫色的线是画出了一个最接近的直线,蓝色是二 次曲线,如何选择曲线来拟合是后面需要讨论的问题,这里只是一个有监督学习的例子。
从而引出有监督学习的定义:我们给出一个数据集来显示“正确答案”,如这里给出的房价,然后根据这个数据集来预测或得到更多的“正确答案”
上面这个例子也叫做回归问题:预测一个连续的数值,将其作为输出,如这里的房价。
下面课程中给出了另一种有监督学习问题——分类问题。以肿瘤问题为例:
蓝色表示良性,红色表示恶性,当然预测值也可以有多个(>2),如0,1,2,3
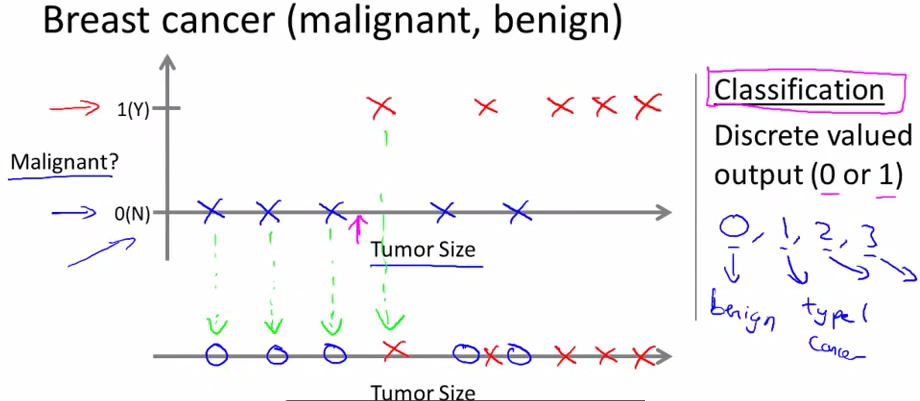
上面这个例子中只用到了一个特征值,就是肿瘤大小,我们也可以有多个特征值,如肿瘤大小和患者年龄:

如果有无限个特征量呢? 支持向量机可以处理无限个特征量的情况
关于分类和回归的区别,我在知乎上看到“走刀口”大大有一个比较直观地解释,这里分享过来,如果有不适之处,我马上删掉。
分类和回归的区别在于输出变量的类型。
定量输出称为回归,或者说是连续变量预测;
定性输出称为分类,或者说是离散变量预测。
举个例子:
预测明天的气温是多少度,这是一个回归任务;
预测明天是阴、晴还是雨,就是一个分类任务。
3. 无监督学习
在课程开头老师对比了有监督学习和无监督学习的数据,想说的应该是,对于分类问题,输入的数据集有特征值,有标签,我们需要做的就是找到两者之间的关系(直线,曲线。。。),我们根据这个关系来根据新给的特征值预测标签数据。如果训练集中的数据有标签,则为有监督学习(如良性0,恶性1);没有标签的话就是无监督学习,也就是说数据集没有提供“正确答案”。无监督学习也即聚类。
无监督学习的例子:Google news 的分类问题,将相同主题的链接放到一起;DNA分组;社交网络分析;市场划分;天文数据分析等等
后面又给了一个鸡尾酒聚会的例子,这个我没有太get到它的用意。















 88
88











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









