






.pth文件信息
-
- 网络模型 (net)/模型状态字典 (state_dict)
存储模型参数的主要部分。它包含了模型的所有可学习参数,如卷积层的权重和偏置、全连接层的参数等。
-
- 优化器 (optimizer)
优化器状态包括了一些用于更新模型参数的中间变量,如动量、梯度等。可以继续使用相同的优化器从之前的训练状态继续优化模型。
-
- 其他数据
包含一些其他辅助信息,如模型的训练次数、评估指标等,可通过以下代码自定义。
checkpoint = {
'state_dict': net.state_dict(),
'optimizer': optimizer.state_dict(),
'epoch': epoch,
'max_test_acc': max_test_acc
}
if save_max:
torch.save(checkpoint, os.path.join(out_dir, 'checkpoint_max.pth'))查看.pth文件
import torch
pthfile = r'your path'
# 加载 .pth 文件,指定在CPU环境下进行
model= torch.load(pthfile, torch.device('cpu'))
# 查看整个.pth
# print(model)
# 查看网络模型
state_dict = model['state_dict']
# print(state_dict)
for name, param in state_dict.items():
# 查看各层的tensor
print(f"{name}: {param.shape}")
如果保存模型时没有将状态字典保存为 state_dict 会报错:KeyError:'state_dict'。
可以直接 print(model) 查看整个模型的字典或查看模型的checkpoint确定键的名字,然后修改state_dict = model['xxxx']
仅查看net部分并存入csv
import torch
import csv
def save_model_params_to_csv(model, csv_file_path, flatten_flag):
"""
将模型 net 的参数保存到 CSV 文件中,flatten_flag决定是否要展开tensor
"""
with open(csv_file_path, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
# 遍历模型的所有参数
for name, param in model.items():
# 获取参数的形状
param_shape = param.shape
if flatten_flag == 0:
# 将参数转换为 numpy 数组
param_values = param.detach().cpu().numpy()
# 在 CSV 文件中写入参数名称和形状
writer.writerow([name] + list(param_shape))
# 输出通道为行, 输入通道为列
for row in param_values:
writer.writerow(row.tolist())
else:
# tensor展开
param_values = param.detach().cpu().numpy().flatten()
writer.writerow([name] + list(param_shape))
# 将每个维度的数据单独写入一行
for value in param_values:
writer.writerow([value])
# 增加一个空行作为分隔
writer.writerow([])
if __name__ == '__main__':
# .pth文件的路径
pthfile = r'your path'
# csv 保存路径
csv_file_path = r'your path'
# 加载.pth文件
model = torch.load(pthfile, torch.device('cpu'))
# 仅提取state_dict部分
state_dict = model['state_dict']
# print(state_dict )
for name, param in state_dict.items():
print(f"{name}: {param.shape}")
# 保存net参数到 CSV 文件
flatten = 0
save_model_params_to_csv(state_dict , csv_file_path, flatten)
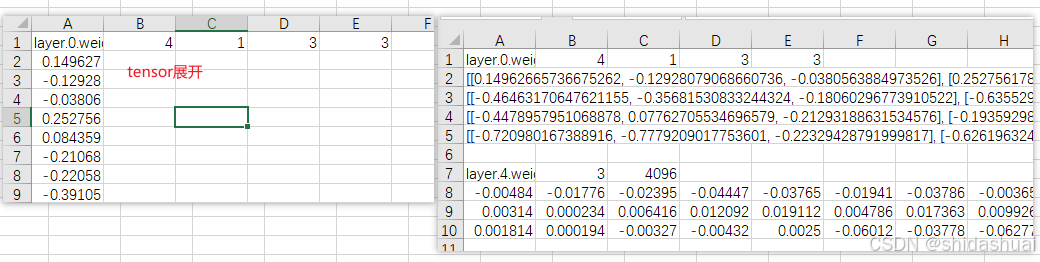
网络是1层卷积和1层全连接的SNN
layer0 是卷积层,tensor=[4,1,3,3],分别表示输出通道为4,输入通道为1(灰度图),卷积核是3x3。
layer4 是全连接层,tensor=[3,4096]
权重保留N位小数
可根据需要将保留N位有效数字,再调用存csv函数即可保存
import torch
from collections import OrderedDict
def get_model_weights(net, effective_num):
"""
从模型 net 中读取所有权重,并以 OrderedDict 的形式返回,权重保留effective_num位小数
"""
weights = OrderedDict()
for name, param in net.items():
# 将权重四舍五入到effective_num位小数
weights[name] = torch.round(param.data * effective_num) / effective_num
return weights
if __name__ == '__main__':
pthfile = r'your path'
model = torch.load(pthfile, torch.device('cpu'))
state_dict = model['state_dict']
# 模型权重保留两位小数
effective_num = 2
effective_num = 10 ** effective_num
model_weights = get_model_weights(state_dict , effective_num)
print(model_weights)
# save_model_params_to_csv(model_weights, csv_file_path, flatten)
















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









