









ABSTRACT
虽然其规模巨大,但成功的深层人工神经网络可以获得训练和测试集非常小的性能差异。
传统知识认为这种小的泛化误差归功于模型的性能,或者是由于在训练的时候加入了正则化技术。
通过广泛的系统实验,我们展示了这些传统方法如何不能解释,而为什么大型神经网络能在实践中推广。具体来说,实验建立了用随机梯度方法训练的图像分类的最先进的卷积网络,能容易地拟合训练数据的随机标记。这种现象在质量上不受显式正则化的影响,即使我们用完全非结构化的随机噪声替换真实图像,也会发生这种现象。 我们用理论结构证实了这些实验结果,表明简单的深度两个神经网络一旦参数数量超过了实际数据点的数量,就已经具有完美的有限样本表达能力。
论文通过与传统模型的比较来解释我们的实验结果。
1 INTRODUCTION
如何区分泛化性好的与那些不好的神经网络呢?解决这个问题不仅可以有助于神经网络的解释性,还可以产生更原生和可靠的模型架构设计。
统计学习理论提出了一些能够控制泛化误差的不同复杂度方法。包括VC维度(Vapnik,1998),Rademacher复杂性(Bartlett&Mendelson,2003)和均匀稳定性(Mukherjee等,2002; Bousquet&Elisseeff,2002; Poggio等,2004)。当参数数量大时,理论认为需要某种正则化确保小的泛化误差,正则化也有可能是隐含的,例如早期停止训练。
1.1 CONTRIBUTIONS
在这项工作中,我们通过表明它不能区分具有完全不同的泛化性能的神经网络,从而使传统的泛化观点转化为问题。
1.1.1 Randomization tests.
论文方法论的核心是非参数统计学中众所周知的随机化测试的变体(Edgington&Onghena,2007)。
第一组实验: 用数据的副本训练了几个标准体系结构,其中真正的标签被随机标签替代。中心发现可以归结为:
Deep neural networks easily fit random labels.
更准确地说,当对真实数据进行完全随机标记的训练时,神经网络实现了0个训练误差。当然测试错误和随机预测差不多。
通过标签随机化,强制使模型的泛化误差大大地增加,而不改变模型,包括其大小、超参数和优化器。
论文在CIFAR10和ImageNet分类基准上训练的几种不同的标准体系。简单说明如下观点。
- 神经网络的有效容量足以记住整个数据集。
- 即使对随机标签进行优化仍然很容易。 事实上,与真实标签上的培训相比,培训时间只增加一个小的常数。
- 随机标签只是一个数据转换,使学习问题的所有其他属性不变。
扩展实验:通过完全随机的像素(例如,高斯噪声)来代替真实图像,并观察到卷积神经网络继续适应零训练误差的数据。表明卷积神经网络可以适应随机噪声。并在无噪声和完全噪声的情况下平滑地内插。随着噪声水平的提高,我们观察到广义误差的稳定恶化。 这表明神经网络能够捕获数据中的剩余信号,同时使用暴力来适应噪声部分。
1.1.2 The role of explicit regularization.
论文表明,正则化的显式形式,如weight decay, dropout, and data augmentation,没有充分解释神经网络的泛化误差。
显式正则化可以提高泛化性能,但既不必要也不足以控制泛化误差。
Explicit regularization may improve generalization performance, but is neither necessary nor by itself sufficient for controlling generalization error.
1.1.3 有限的样本表达 Finite sample expressivity.
论文用理论结构补充实验观察结果,表明一般大型神经网络可以表达训练数据的任何标签。展示了一个非常简单的两层ReLU网络,其中p = 2n + d参数可以表示任何尺寸为n的样品的任何标签。也可以使用一个深度k网络,其中每层只有O(n/k)个参数。
1.1.4 The role of implicit regularization.
在神经网络中,几乎总是选择运行随机梯度下降输出的模型。分析线性模型中,SGD如何作为隐式正则化器。对于线性模型,SGD总是收敛到一个小规模的解决方案。 因此,算法本身将解决方案隐含地规范化。
2 EFFECTIVE CAPACITY OF NEURAL NETWORKS
目标是了解前馈神经网络的有效模型能力。非参数随机化测试的方法:采用候选架构,并对真实数据和真实标签替换为随机标签的数据的副本进行训练。对于后者,实例和类标签之间不再有任何关系。因此,学习是不可能的。令人惊讶的是,多标准化结构的训练过程的几个属性在很大程度上不受标签变形的影响。
图像分类数据集:CIFAR10数据集(Krizhevsky&Hinton,2009)和ImageNet(Russakovsky等,2015)ILSVRC 2012数据集。
architecture:Inception V3 (Szegedy et al., 2016) architecture on ImageNet. Alexnet (Krizhevsky et al., 2012), and MLPs on CIFAR10
使用随机标签和像素 FITTING RANDOM LABELS AND PIXELS
实验使用一下几种情况:
- 真正的标签:原始数据集没有修改。
- 部分损坏的标签:独立的概率p,每个图像的标签被破坏为一个统一的随机类。
- 随机标签:所有标签都被替换为随机标签。
- 混洗像素:选择像素的随机排列,然后将相同的排列应用于训练和测试集中的所有图像。
- 随机像素:独立地对每个图像应用不同的随机排列。
- 高斯:高斯分布(与原始图像数据集具有匹配均值和方差)用于为每个图像生成随机像素。
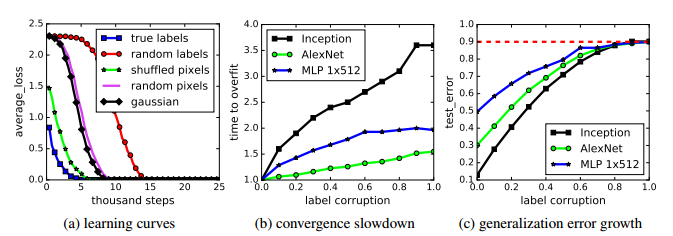
在CIFAR10上安装随机标签和随机像素。 (a)显示了各种实验设置的训练损失与培训步骤的衰减。 (b)显示了不同标签损坏率的相对收敛时间,随着标签噪声水平的增加,收敛时间的减慢。 (c)显示不同标签损坏下的测试错误(也是训练误差为0的泛化误差)。
令人惊讶的是,尽管随机标签完全破坏了图像和标签之间的关系,随机梯度下降具有不变的超参数设置可以优化权重以适合随机标签。 我们通过混洗图像像素进一步破坏图像的结构,甚至从高斯分布中完全重新采样随机像素。但是我们测试的网络仍然能够适应。
3 THE ROLE OF REGULARIZATION

实验中大多数随机化测试都是在明确的正规化关闭的情况下执行的。
正如我们将看到的,在深度学习中,明确的正规化似乎发挥了不同的作用。 如附录中表2的底行所示,即使出现dropout and weight decay,InceptionV3仍然能够非常适合随机训练集。 虽然没有明确的正则化,weight decay打开情况下,在CIFAR10上,Inception和MLP都完全适合随机训练集。 然而,AlexNetweight decay开启无法收敛于随机标签。 为了调查正规化在深度学习中的作用,我们明确比较了深层网络学习与非正规化学习的行为。
使用了以下regularizers:
- Data augmentation:通过域特定的转换增加训练集。对于图像数据,常用的变换包括随机裁剪,亮度随机扰动,饱和度,色调和对比度。
- Weight decay: equivalent to a L2 regularizer
- Dropout:以给定的dropout概率随机屏蔽各层的每个元素的输出。 ImageNet的Inception V3仅在我们的实验中使用了退出。

Figure 2:隐性正则化对泛化性能的影响。 aug是数据增加,wd是重量衰减,BN是批量归一化。 阴影区域是累积最佳测试精度,作为提前停止的潜在性能增益的指标。 (a)当其他正则化不在时,提前停止可能有可能改善泛化。 (b)早期停止对CIFAR10不一定有帮助,但是批处理正则化稳定了训练过程并改进了泛化。
IMPLICIT REGULARIZATIONS
Early stopping早期停止被显示为隐含地规范了一些凸出的学习问题。
批量归一化(Batch normalization,Ioffe&Szegedy,2015)即在每个小批量内归一化层响应。
图2b比较了CIFAR10上的Inception的两个变体的学习曲线,所有的显式正则符都被关闭。归一化运营商有助于稳定学习动态,但对泛化绩效的影响只有3〜4%。
总而言之,我们对显式和隐性正则化者的观察一致地表明,正确的regularizers可以有助于提高泛化性能。然而,regularizers不太可能是泛华的根本原因,因为网络在所有正规者被删除之后继续表现良好。
4 FINITE-SAMPLE EXPRESSIVITY
Theorem 1. There exists a two-layer neural network with ReLU activations and 2n+d weights that
can represent any function on a sample of size n in d dimensions.
存在具有ReLU激活和2n + d权重的双层神经网络,其可以表示d维中尺寸为n的样本上的任何函数。
6 CONCLUSION
- 几个成功的神经网络架构的有效容量足够大,原则上足以记忆训练数据。
- 传统方法使用模型复杂度量度解决了大型人造神经网络的泛化能力。论文认为还没有发现一个精确的正式措施,在这些措施下,这些巨大的模式是简单的。
- 即使最终的模型不具有泛化性,优化仍然是经验上的容易的。这表明优化在经验上容易的原因肯定与真正的泛化原因不同。
来源
- Zhang C, Bengio S, Hardt M, et al. Understanding deep learning requires rethinking generalization[J]. 2016.
PDF下载:1611.03530.pdf
















 1409
1409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











