






一. 基本介绍
需要的工程文件:rknn_toolkit2-1.3.0和rknpu2(具体下载方法以及介绍后面有介绍)
官方教程1:
官方教程2:
下载完rknn-toolkit SDK后,目录下会有Rockchip_Quick_Start_RKNN_SDK_V1.3.0_CN.pdf
非官方教程1:
非官方教程2:
rk3588对npu的再探索,yolov5使用rknn模型推理教程
RKNN模型:
RKNN是Rockchip NPU平台使用的模型类型,以.rknn后缀结尾的模型文件。用户可以通过RKNN SDK提供的工具将自主研发的算法模型转换成RKNN模型。如果已有以.rknn后缀结尾的模型文件,也就是属于Rockchip NPU平台适用的模型类型RKNN,就直接在Linux平台上通过交叉编译得到可执行文件, 然后将可执行文件及对应的库文件,.rknn后缀结尾的模型文件以及图片文件等输入资源拷贝至RK3588进行模型的运行。
非RKNN模型:
对于Ternsorflow, PyTorch等其他模型,想要在RK3588平台运行,需要先进行模型转换。可以在搭载Ubuntu18.04以及以上版本的PC上使用RKNN-Toolkit2工具将模型转化为RKNN格式,在按照前一类方法将其交叉编译后部署到开发板上。
总体开发流程(以pytorch框架开发,C++部署):
- 在PC端安装RKNN-Toolkit2工具(详见二)
- 使用pytorch搭建网络并训练,保存为.pth文件(不再详述)
- 在PC端使用torch.onnx.export()将.pth文件转化为.onnx文件,接下来使用RKNN-Toolkit2将.onnx文件转化为.rknn文件(详见三)
- 将板子连接PC,获取板子的ID号,连板测试模型的效果(非必须,详见四.2)
- 使用RKNN SDK提供的C接口API按照官方给定的调用流程(具体可以见rknpu2/doc/Rockchip_RKNPU_User_Guide_RKNN_API_V1.4.0_CN.pdf) 编写C语言代码,并相应修改CMakeLists.txt(详见五)
- 下载交叉编译器并编译步骤5得到的代码(详见四.3)
- 将编译得到的结果拷贝到板子上运行(详见四.3)
总体开发流程(以pytorch框架开发,python部署)
- 在PC端安装RKNN-Toolkit2工具
- 使用pytorch搭建网络并训练,保存为.pth文件
- 在PC端使用torch.onnx.export()将.pth文件转化为.onnx文件,接下来使用RKNN-Toolkit2将.onnx文件转化为.rknn文件
- 将板子连接PC,获取板子的ID号,连板测试模型效果(前四步与上面相同)
- 在板子上安装rknn-toolkit-lite,使用Python API编写python脚本对模型进行推理
二. 安装RKNN-Toolkit2(PC端)
RKNN-Toolkit2目前版本适用ubuntu18.04(x64)及以上,工具只能安装在PC上,暂不支持Windows, MacOS, Debian等操作系统。
注意PC是X86架构,板子是arm架构的。安装时轮子(.whl文件)的名字里有x86字样的是安装在PC端的(具体位置在rknn-toolkit2-1.3.0/packages下)。轮子名字里有aarch64字样的,是rknn-toolkit-lite,是官方为了在板端方便部署开发的工具(具体位置在rknn-toolkit2-1.3.0/rknn_toolkit_lite2/package下)。
总结来说,rknn-toolkit2适用于x86架构,要安装在PC端,功能下面有介绍。
rknn-toolkit2-lite适用于arm架构,要安装在板子上,是为了方便在板端使用python部署用的。
RKNN-Toolkit2工具功能介绍:
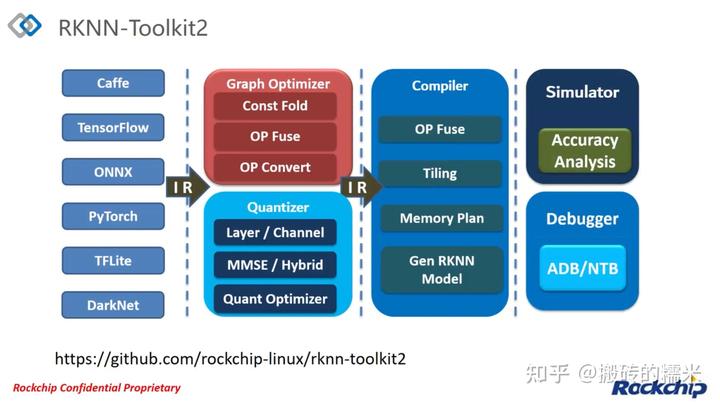
- 模型转换:支持Caffe, Tensorflow, Tensorflow Lite, ONNX, DarkNet, PyTorch等模型转化为RKNN模型,并支持RKNN模型导入导出。
- 量化功能:支持将浮点模型量化为定点模型,目前支持的量化方法为非对称量化,并支持混合量化功能。
- 模型推理:能够在PC上模拟NPU运行RKNN模型并获取推理结果,或将RKNN模型分发到指定的NPU设备上进行推理并获取推理结果。
- 性能评估:将RKNN模型分发到指定的NPU设备上运行,以评估模型在实际设备上运行时的性能。
- 内存评估:评估模型运行时内存的占用情况。使用该功能时,必须将RKNN模型分发到NPU设备中运行,并调用相关接口获取内存使用信息。
- 量化精度分析:该功能将给出模型量化前后每一层推理结果与浮点模型推理结果的余弦距离,以便于分析量化误差是如何出现的,为提高量化模型的精度提供思路
RKNN-Toolkit2-Lite功能介绍:
- RKNN-Toolkit-Lite2为Rockchip NPU平台(RK3566、RK3568、RK3588、RK3598S)提供Python编程接口,帮助用户部署RKNN模型并加速AI应用程序的实施。
step1.下载RKNN-Toolkit2
方法1:使用git clone
git clone https://github.com/rockchip-linux/rknn-toolkit2.git
方法2:使用百度网盘下载

下载得到的文件夹包含RK_NPU_SDK_1.2.0和RK_NPU_SDK_1.3.0, 我们使用1.3.0版本,其中RK_NPU_SDK_1.3.0/rknn_toolkit2-1.3.0文件夹中包含:
- doc: 快速入门手册,C语言API说明以及依赖安装文档
- docker:使用docker工具开发时所需资料(不用的话可以删掉)
- examples: caffe,darknet,onnx,pytorch,tensorflow,tflite转化为.rknn的例子以及一些常用功能举例
- packages: rknn_toolkit2的.whl安装文件
- rknn_toolkit_lite2: RKNN-Toolkit-lite的文档,示例以及安装包
step2.安装依赖
首先使用anaconda建立一个python3.6的环境(官方提供的也有python3.8的安装包,但是我安装之后在转换模型时遇到了版本相关的报错,所以建议安装python3.6版本):
conda create -n deploy python=3.6
安装rknn-toolkit2依赖:
sudo apt-get install libxslt1-dev zlib1g-dev libglib2.0 libsm6 libgl1-mesa-glx libprotobuf-dev gcc
cd rknn-toolkit2-1.3.0/doc
pip install -r requirements_cp36-1.3.0.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
如果报错BUG:ERROR: Cannot uninstall ‘certifi’. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall, 解决方案:
pip install certifi --ignore-installed
pip install certifi --ignore-installed -i https://pypi.tuna.tsinghua.edu.cn/simple
如果报错说没有匹配版本,则更新pip:
pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple
如果中途显示bfloat16安装失败,则手动安装一下numpy:
pip install numpy==1.16.6
step3.安装rknn-toolkit2(有时候会遇到版本不匹配问题,多试几次就好了)
cd rknn-toolkit2-1.3.0/packages
pip install rknn_toolkit2-1.3.0_11912b58-cp36-cp36m-linux_x86_64.whl
step4: 检查是否安装成功
conda activate deploy
python
from rknn.api import RKNN
如果没报错则为成功
三. Pytorch转RKNN模型(在PC端进行)
路线1:.pth --> .onnx --> .rknn
step1: .pth --> .onxx
step2: .onxx --> .rknn
示例1:1
import cv2
import numpy as np
from rknn.api import RKNN
import os
if __name__ == '__main__':
platform = 'rk3566'
exp = 'yolov5s'
Width = 640
Height = 640
MODEL_PATH = './onnx_models/yolov5s_rm_transpose.onnx'
NEED_BUILD_MODEL = True
# NEED_BUILD_MODEL = False
im_file = './dog_bike_car_640x640.jpg'
# Create RKNN object
rknn = RKNN()
OUT_DIR = "rknn_models"
RKNN_MODEL_PATH = './{}/{}_rm_transpose.rknn'.format(OUT_DIR,exp+'-'+str(Width)+'-'+str(Height))
if NEED_BUILD_MODEL:
DATASET = './dataset.txt'
rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], target_platform="rk3588")
# Load model
print('--> Loading model')
ret = rknn.load_onnx(MODEL_PATH)
if ret != 0:
print('load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=True, dataset=DATASET)
if ret != 0:
print('build model failed.')
exit(ret)
print('done')
# Export rknn model
if not os.path.exists(OUT_DIR):
os.mkdir(OUT_DIR)
print('--> Export RKNN model: {}'.format(RKNN_MODEL_PATH))
ret = rknn.export_rknn(RKNN_MODEL_PATH)
if ret != 0:
print('Export rknn model failed.')
exit(ret)
print('done')
else:
ret = rknn.load_rknn(RKNN_MODEL_PATH)
rknn.release()
示例2:
from rknn.api import RKNN
import os
if __name__ == '__main__':
platform = 'rk3588'
'''step 1: create RKNN object'''
rknn = RKNN()
'''step 2: load the .onnx model'''
rknn.config(target_platform='rk3588')
print('--> Loading model')
ret = rknn.load_onnx('actor_simple.onnx')
if ret != 0:
print('load model failed')
exit(ret)
print('done')
'''step 3: building model'''
print('-->Building model')
ret = rknn.build(do_quantization=False)
if ret != 0:
print('build model failed')
exit()
print('done')
'''step 4: export and save the .rknn model'''
OUT_DIR = 'rknn_models'
RKNN_MODEL_PATH = './{}/actor_simple.rknn'.format(OUT_DIR)
if not os.path.exists(OUT_DIR):
os.mkdir(OUT_DIR)
print('--> Export RKNN model: {}'.format(RKNN_MODEL_PATH))
ret = rknn.export_rknn(RKNN_MODEL_PATH)
if ret != 0:
print('Export rknn model failed.')
exit(ret)
print('done')
'''step 5: release the model'''
rknn.release()
路线2:.pth --> .rknn
四. 进行推理
共有四种方式,如下所示:
- 第一种是借助RKNN-Toolkit2的功能在模拟NPU上运行RKNN模型并获取推理结果(在PC端)
- 第二种是借助RKNN-Toolkit2的功能, 将板子与PC连接,将RKNN模型分发到指定的NPU设备进行推理并获取推理结果(网络推理在板端,脚本写在PC端)
- 第三种是调用RKNN SDK的C语言API进行测试代码编写,并使用交叉编译器进行编译,将得到的可执行文件拷贝到板子上运行(开发编译在PC端,运行在板端)
- 第四种是在板端安装rknn-toolkit2-lite工具,使用python脚本在板端推理(代码开发运行都在板端)
1.在PC上仿真运行(以官方代码举例)
RKNN-Toolkit2自带了一个模拟器,直接在PC上运行Demo即是将转换后的模型部署到仿真NPU上运行。
cd RKNN_SDK/RK_NPU_SDK_1.3.0/rknn-toolkit2-1.3.0/examples/tflite/mobilenet_v1
conda activate deploy
python test.py
2.板子连PC测试自己的RKNN模型(以自己的代码举例):
step1: 使用USB-typeC连接线连接板端typeC口以及电脑的USB口
step2: 安装adb
查看设备ID
如果没有板子的ID号,可能是数据线连接问题,尝试换条数据线试一下
step3: 更新板子的rknn_server和librknnrt.so
librknnrt.so: 是一个板端的runtime库
rknn_server: 是一个运行在板子上的后台代理服务,用于接收PC通过USB传输过来的协议,然后执行板端runtime接口,并返回结果给PC。
下载RKNPU工程:
git clone https://github.com/rockchip-linux/rknpu2
Linux
adb push rknpu2/runtime/RK3588/Linux/rknn_server/aarch64/usr/bin/rknn_server /usr/bin/
adb push rknpu2/runtime/RK3588/Linux/librknn_api/aarch64/librknnrt.so /usr/lib/
adb push rknpu2/runtime/RK3588/Linux/librknn_api/aarch64/librknn_api.so /usr/lib/
# 可以使用 "systemctl status rknn_server" 查看rknn_server服务是否处于运行状态
# 若没有运行,请在板子的串口终端运行rknn_server
chmod +x /usr/bin/rknn_server
/usr/bin/rknn_server
查看是否更新成功
adb shell
su
setenforce 0
pgrep rknn_server
查看到有rknn_server进程id,更新成功。
step4: 测试
from rknn.api import RKNN
import numpy as np
import env_class
import time
env = env_class
model = 'rknn_models/actor.rknn'
'''step 1: Initialize'''
rknn = RKNN()
'''step2: Load RKNN model'''
print('--> Load RKNN model')
ret = rknn.load_rknn(path=model)
if ret != 0:
print('Load RKNN model failed')
exit(ret)
print('done')
'''step3: Init runtime environment'''
print('--> Init runtime environment')
ret = rknn.init_runtime(target='RK3588', device_id='6b7458087c77686b')
if ret != 0:
print('Init runtime environment failed')
exit(ret)
print('done')
'''step4: Inference'''
for j in range(n_eval):
o, info = env.reset()
r = 0
d = False
ep_ret = 0
ep_len = 0
while not (d or (ep_len == 1000)):
o = np.expand_dims(o, axis=0).astype(np.float32)
time0 = time.time()
a = rknn.inference(inputs=[o])[0][0]
time1 = time.time()
print('The time spent is:', time1 - time0)
o, r, d, _ = env.step(a)
ep_ret += r
ep_len += 1
ep_return_list.append(ep_ret)
print('The rewards are:', ep_return_list)
'''step5: Release'''
rknn.release()
上面代码中target后面接的是板子的型号,device_id是通过abd deives得到的ID值
3. 在RK3588板子上调试
3.1 以官方代码举例
step1: 下载RKNPU2工程(在PC端)
git clone https://github.com/rockchip-linux/rknpu2.git
RKNPU工程说明:
1)doc:包含RKNN编译器支持的操作符说明,快速入门手册,以及C接口API说明
2)examples:
- 3rdparty: 一些第三方库文件
- librknn_api_android_demo: 安卓平台调用RKNN API示例
- rknn_api_demo: 关于零拷贝API的示例
- rknn_benchmark: 用于测试在不同NPU核上运行时间
- rknn_commen_test: 零拷贝API+通过模型路径加载模型
- rknn_internal_mem_reuse_demo: 展示了如何进行内存复用,使用零拷贝API
- rknn_mobilenet_demo: 零拷贝API+通过路径加载模型
- rknn_multiple_input_demo: 通用接口API+通过路径加载模型
- rknn_ssd_demo: 通用接口API+二进制方式加载模型
- rknn_yolov5_demo: 通用接口API+二进制方式加载模型
3)runtime: 包含动态链接库.so和头文件.h
其中我们所需要文件的在runtime/RK3588/Linux下
step2: 编译rknn_yolov5_demo(在PC端)
首先需要安装交叉编译器,方法如下:[2]
- 查看可以安装的版本

- 然后选择可以安装的版本进行安装, 例如选择gcc-9-aarch64-linux-gnu和g+±9-aarch64-linux-gnu
sudo apt-get install gcc-9-aarch64-linux-gnu
sudo apt-get install g++-9-aarch64-linux-gnu
- 安装依赖
sudo apt --fix-broken install
- 安装一个没有版本号的gcc和g++
sudo apt-get install gcc-aarch64-linux-gnu
sudo apt-get install g++-aarch64-linux-gnu
- 查看版本
aarch64-linux-gnu-g++ -v
aarch64-linux-gnu-gcc -v
然后就可以进行编译了
cd rknpu2/examples/rknn_yolov5_demo/
./build-linux_RK3588.sh
编译后的结果会放在install目录下,将install里所有的文件,包含RKNN模型,库文件和可执行文件等,使用adb命令或者直接复制等方法拷贝至开发板。
step3: 在开发板上测试(在板端)
cd到install/rknn_yolov5_demo_Linux/目录下,然后输入指令
./rknn_yolov5_demo ./model/RK3588/yolov5s-640-640.rknn ./model/bus.jpg
推理结束后可以查看得到的目标检测结果
3.2 参考官方代码,我们实现了一个简单的MLP的部署流程
step1: 参考上面的介绍安装交叉编译器
step2: 新建一个文件夹用来放置代码,例如名为rknn_model_test。在该文件夹下新建include文件夹,里面放置rknn_api.h(该头文件在rknpu2/runtime/RK3588/Linux/librknn_api/include下)。新建lib文件夹,里面放置librknnrt.so文件(该动态库文件包含在rknpu2/runtime/RK3588/Linux/librknn_api/aarch64下)。新建model文件夹,放入之前生成的xxx.rknn模型。
step3: 编写rknn_model.cpp(以通用API接口为例,代码中所用到的API下文中都有介绍)
#include "rknn_api.h"
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <memory.h>
#include <fstream>
#include <iostream>
const int state_dim = 34;
const int act_dim = 12;
using namespace std;
static unsigned char *load_model(const char *filename, int *model_size)
{
FILE *fp = fopen(filename, "rb");
if (fp == nullptr)
{
printf("fopen %s fail!\n", filename);
return NULL;
}
fseek(fp, 0, SEEK_END);
int model_len = ftell(fp);
unsigned char *model = (unsigned char *)malloc(model_len);
fseek(fp, 0, SEEK_SET);
if (model_len != fread(model, 1, model_len, fp))
{
printf("fread %s failed!\n", filename);
free(model);
return NULL;
}
*model_size = model_len;
if (fp)
{
fclose(fp);
}
return model;
}
float input_data[state_dim] = {1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0,
1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0,
1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0,
1.0, 1.0, 1.0, 1.0};
int main(int argc, char **argv)
{
int ret = 0;
int model_len = 0;
unsigned char *model = nullptr;
rknn_context ctx = 0;
const char *model_path = argv[1];
// load RKNN Model
printf("Loading model ...\n");
model = load_model(model_path, &model_len);
printf("rknn_init ...\n");
ret = rknn_init(&ctx, model, model_len, 0, NULL);
if (ret < 0)
{
printf("rknn_init fail! ret=%d\n", ret);
}
// Get Model Input Ouput Info
rknn_input_output_num io_num;
ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));
if (ret != RKNN_SUCC)
{
printf("rknn_query fail! ret=%d\n", ret);
return -1;
}
printf("model input num:%d, output num: %d\n", io_num.n_input, io_num.n_output);
// Set Input data
rknn_input inputs[1];
memset(inputs, 0, sizeof(inputs));
inputs[0].index = 0;
inputs[0].buf = input_data;
inputs[0].size = state_dim * sizeof(float);
inputs[0].pass_through = 0;
inputs[0].type = RKNN_TENSOR_FLOAT16;
inputs[0].fmt = RKNN_TENSOR_NHWC;
ret = rknn_inputs_set(ctx, io_num.n_input, inputs);
if (ret < 0)
{
printf("rknn_input_set fail! ret=%d\n", ret);
return -1;
}
// Run
printf("rknn_run\n");
ret = rknn_run(ctx, nullptr);
if (ret < 0)
{
printf("rknn_run fail! ret=%d\n", ret);
return -1;
}
// Get output
rknn_output outputs[io_num.n_output];
memset(outputs, 0, sizeof(outputs));
for (int i = 0; i < io_num.n_output; i++)
{
outputs[i].want_float = 1;
}
ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL);
if (ret < 0)
{
printf("rknn_outputs_get fail! ret=%d\n", ret);
}
/*------------------------------------------*/
cout << "The results are" << endl;
float *actions = (float *)(outputs[0].buf);
for (int i = 0; i < act_dim; i++)
{
cout << actions[i] << " ";
}
/*------------------------------------------*/
// release outputs
ret = rknn_outputs_release(ctx, io_num.n_output, outputs);
// destory
if (ctx > 0)
{
rknn_destroy(ctx);
}
if (model)
{
free(model);
}
return 0;
}
或者rknn_model.cpp(以零拷贝接口为例):
#include "rknn_api.h"
#include <float.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/time.h>
const int batch_size = 1;
const int state_dim = 34;
const int act_dim = 12;
using namespace std;
static inline int64_t getCurrentTimeUs()
{
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec * 1000000 + tv.tv_usec;
}
static void dump_tensor_attr(rknn_tensor_attr *attr)
{
printf(" index=%d, name=%s, n_dims=%d, dims=[%d, %d, %d, %d], n_elems=%d, size=%d, fmt=%s, type=%s, qnt_type=%s, "
"zp=%d, scale=%f\n",
attr->index, attr->name, attr->n_dims, attr->dims[0], attr->dims[1], attr->dims[2], attr->dims[3],
attr->n_elems, attr->size, get_format_string(attr->fmt), get_type_string(attr->type),
get_qnt_type_string(attr->qnt_type), attr->zp, attr->scale);
}
/*-------------------------------------------
Main Functions
-------------------------------------------*/
int main(int argc, char *argv[])
{
char *model_path = argv[1];
rknn_context ctx = 0;
int loop_count = 1;
// Load RKNN model
int model_len = 0;
int ret = rknn_init(&ctx, &model_path[0], 0, 0, NULL);
if (ret < 0)
{
printf("rknn_init fail! ret=%d\n", ret);
}
// Get sdk and driver version
rknn_sdk_version sdk_ver;
ret = rknn_query(ctx, RKNN_QUERY_SDK_VERSION, &sdk_ver, sizeof(sdk_ver));
if (ret != RKNN_SUCC)
{
printf("rknn_query fail! ret=%d\n", ret);
return -1;
}
printf("rknn_api/rknnrt version: %s, driver version: %s\n", sdk_ver.api_version, sdk_ver.drv_version);
// Get Model Input Output Info
rknn_input_output_num io_num;
ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));
if (ret != RKNN_SUCC)
{
printf("rknn_query fail! ret=%d\n", ret);
return -1;
}
printf("model input num: %d, output num: %d\n", io_num.n_input, io_num.n_output);
printf("input tensors:\n");
rknn_tensor_attr input_attrs;
memset(&input_attrs, 0, sizeof(rknn_tensor_attr));
input_attrs.index = 0;
ret = rknn_query(ctx, RKNN_QUERY_INPUT_ATTR, &(input_attrs), sizeof(rknn_tensor_attr));
if (ret < 0)
{
printf("rknn_init error! ret=%d\n", ret);
return -1;
}
input_attrs.type = RKNN_TENSOR_FLOAT32;
input_attrs.size = input_attrs.size_with_stride = input_attrs.n_elems * sizeof(float);
dump_tensor_attr(&input_attrs);
printf("output tensors:\n");
rknn_tensor_attr output_attrs;
memset(&output_attrs, 0, sizeof(rknn_tensor_attr));
output_attrs.index = 0;
ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs), sizeof(rknn_tensor_attr));
if (ret != RKNN_SUCC)
{
printf("rknn_query fail! ret=%d\n", ret);
return -1;
}
output_attrs.type = RKNN_TENSOR_FLOAT32;
output_attrs.size = output_attrs.size_with_stride = output_attrs.n_elems * sizeof(float);
dump_tensor_attr(&output_attrs);
float input_data[batch_size][state_dim] = {1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0,
1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0,
1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0,
1.0, 1.0, 1.0, 1.0};
// create input tensor memory
rknn_tensor_mem *input_mems;
input_mems = rknn_create_mem(ctx, input_attrs.size);
// create output tensor memory
rknn_tensor_mem *output_mems;
output_mems = rknn_create_mem(ctx, output_attrs.size);
// Set input tensor memory
ret = rknn_set_io_mem(ctx, input_mems, &input_attrs);
if (ret < 0)
{
printf("rknn_set_io_mem fail! ret=%d\n", ret);
return -1;
}
ret = rknn_set_io_mem(ctx, output_mems, &output_attrs);
if (ret < 0)
{
printf("rknn_set_io_mem fail! ret=%d\n", ret);
return -1;
}
// copy input data to input tensor memory
memcpy(input_mems->virt_addr, input_data, sizeof(input_data));
// Run
printf("Begin perf ...\n");
for (int i = 0; i < loop_count; ++i)
{
int64_t start_us = getCurrentTimeUs();
ret = rknn_run(ctx, NULL);
int64_t elapse_us = getCurrentTimeUs() - start_us;
if (ret < 0)
{
printf("rknn run error %d\n", ret);
return -1;
}
printf("%4d: Elapse Time = %.2fms, FPS = %.2f\n", i, elapse_us / 1000.f, 1000.f * 1000.f / elapse_us);
}
// print the result
float *buffer = (float *)(output_mems->virt_addr);
for (int i = 0; i < act_dim; i++)
{
printf("%f", buffer[i]);
}
// Destroy rknn memory
rknn_destroy_mem(ctx, input_mems);
rknn_destroy_mem(ctx, output_mems);
// Destroy
rknn_destroy(ctx);
return 0;
}
step4: 编写CMakeLists.txt
cmake_minimum_required(VERSION 3.10)
project(rknn_test)
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS}")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11")
include_directories(${CMAKE_SOURCE_DIR}/include)
add_executable(rknn_test rknn_model.cpp)
set(RKNN_RT_LIB ${CMAKE_SOURCE_DIR}/lib/librknnrt.so)
target_link_libraries(rknn_test ${RKNN_RT_LIB})
# install target and libraries
set(CMAKE_INSTALL_PREFIX ${CMAKE_SOURCE_DIR}/install/rknn_test_${CMAKE_SYSTEM_NAME})
install(TARGETS rknn_test DESTINATION ./)
install(PROGRAMS ${RKNN_RT_LIB} DESTINATION lib)
install(DIRECTORY model DESTINATION ./)
step5:编写build-linux_RK3588.sh
set -e
TARGET_SOC="rk3588"
GCC_COMPILER=aarch64-linux-gnu
export LD_LIBRARY_PATH=${TOOL_CHAIN}/lib64:$LD_LIBRARY_PATH
export CC=${GCC_COMPILER}-gcc
export CXX=${GCC_COMPILER}-g++
ROOT_PWD=$( cd "$( dirname $0 )" && cd -P "$( dirname "$SOURCE" )" && pwd )
# build
BUILD_DIR=${ROOT_PWD}/build/build_linux_aarch64
if [[ ! -d "${BUILD_DIR}" ]]; then
mkdir -p ${BUILD_DIR}
fi
cd ${BUILD_DIR}
cmake ../.. -DCMAKE_SYSTEM_NAME=Linux -DTARGET_SOC=${TARGET_SOC}
make -j4
make install
cd -
step6: 编译,在终端输入
bash build-linux_RK3588.sh
step7: 运行
经过step6编译之后会生成build文件夹和install文件夹。install文件夹下包含生成的二进制文件,lib库和model文件夹(对应了CMakeLists.txt中的install指令)。将install文件夹拷贝到板子上,然后输入如下指令,赋予二进制文件权限:
接下来运行即可:
./rknn_test ./model/xxx.rknn
4. 在RK3588板子上调试(python)
step1: 在板子上安装rknn-toolkit-lite
tknn-toolkit-lite的官方手册在rknn-toolkit2-1.3.0/rknn_toolkit_lite2/docs下,官方说需要运行在Debian10/11(aarch64)操作系统,经验证ubuntu20.04和ubuntu22.04也可安装并使用。
ubuntu20.04的python版本是3.8,但是rknn-toolkit-lite需要的安装环境是python3.7或者python3.9。尝试过在系统路径安装python3.9,并将系统python3版本切换为python3.9, 安装后无法使用并且terminal也无法打开。安装miniconda并新建python3.9环境安装成功。
1)下载miniconda并安装
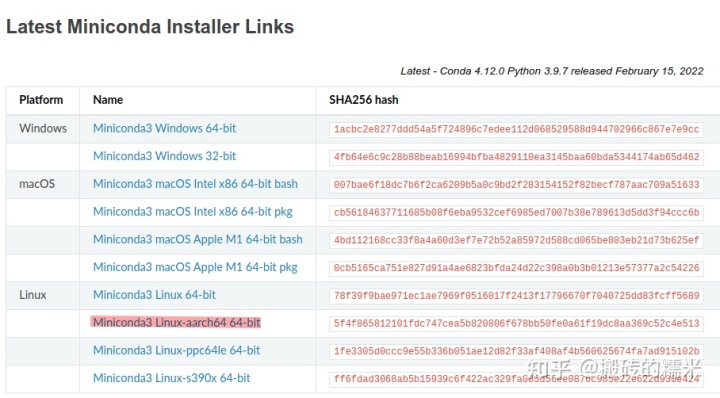
选择适用于aarch64架构的版本(如上图所示)。得到xxx.sh文件,新建终端,输入
bash Miniconda3-latest-Linux-aarch64.sh
然后一路回车+yes(需要输入两次)
完成后在终端输入
查看是否安装成功。
2)新建并激活python3.9环境
conda create -n rknnlite python=3.9
conda activate rknnlite
3)安装轮子
cd rknn-toolkit2-1.3.0/rknn_toolkit_lite2/packages
pip install rknn_toolkit_lite2-1.3.0-cp39-cp39-linux_aarch64.whl
4)测试
python
from rknnlite.api import RKNNLite
如果能够正常导入,则安装成功
step 2: 使用官方例子测试
conda activate rknnlite
cd rknn-toolkit2-1.3.0/rknn_toolkit_lite2/examples/inference_with_lite
python test.py
或者使用自己的代码测试:
import numpy as np
from rknnlite.api import RKNNLite
import env_class
import time
env = env_class()
model = 'rknn_models.rknn'
'''step1: Initialize'''
rknn_lite = RKNNLite()
'''step2: load RKNN model'''
print('--> Load RKNN model')
ret = rknn_lite.load_rknn(model)
if ret != 0:
print('Load RKNN model failed')
exit(ret)
print('done')
'''step3: Init runtime environment'''
print('--> Init runtime environment')
ret = rknn_lite.init_runtime(core_mask=RKNNLite.NPU_CORE_0)
if ret != 0:
print('Init runtime environment failed')
exit(ret)
print('done')
'''step4: Inference'''
for j in range(n_eval):
o, info = env.reset()
r = 0
d = False
ep_ret = 0
ep_len = 0
while not (d or (ep_len == 50)):
o = np.expand_dims(o, axis=0).astype(np.float32)
time0 = time.time()
a = rknn_lite.inference(inputs=[o])[0][0]
time1 = time.time()
print('The time spent is:', time1 - time0)
o, r, d, _ = env.step(a)
ep_ret += r
ep_len += 1
np.append(ep_return_list, ep_ret)
print('The rewards are:', ep_return_list)
'''step5: Release'''
rknn_lite.release()
可以看到RKNN(运行在PC端,进行连板推理)和RKNN-lite(运行在板端)的用法基本一样,都是先创建对象,然后导入RKNN模型,接下来初始化运行时环境,再进行推理,结束后释放对象。接口的用法也基本一样,唯一的不同在于初始化运行时的时候,连板推理需要指定设备和ID号,板端推理需要设置工作的核心(有0,1,2三个核可以选择)。
五. 板端代码开发(C++ API)
1.C接口API说明
在使用RKNN SDK之前,用户首先需要使用RKNN-Toolkit2工具将用户的模型转换为RKNN模型。
得到RKNN模型文件之后,用户可以选择使用C接口在RK3588平台开发使用。
对于RK3588, SDK库文件为rknpu/runtime/RK3588/Linux/librknn_api/aarch64下的librknnrt.so
2.API流程说明
RK3588上有两组API可以使用,分别是通用API接口和零拷贝流程API接口。
两组API的主要区别在于,通用接口API每次更新帧数据,需要将外部模块分配的数据拷贝到NPU运行时的输入内存。而零拷贝流程的接口会直接使用预先分配的内存(包括NPU运行时创建的或外部其他框架创建的,比如DRM框架),减少了内存拷贝的花销。
当用户输入数据只有虚拟地址时,只能使用通用API接口,当用户输入数据有物理地址或者fd时,两组接口都可以使用。
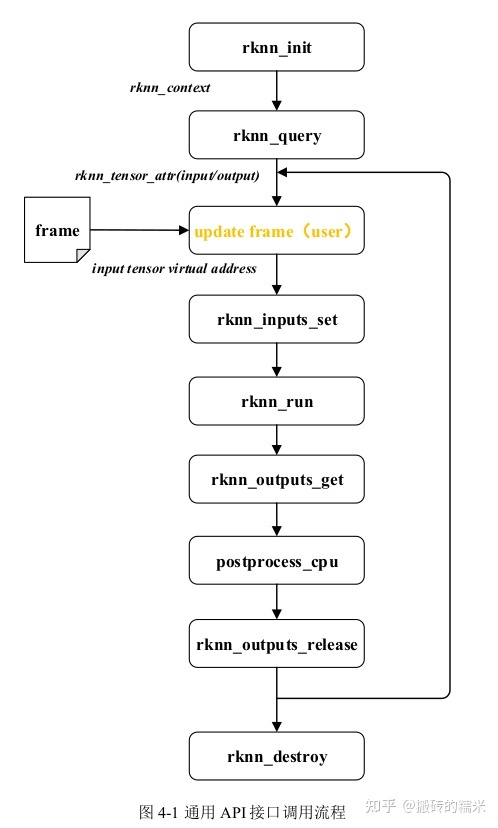
对于通用API接口,首先初始化rknn_input结构体,帧数据包含在该结构体中,使用RKNN_inputs_set函数设置模型输入,等待推理结束后,使用rknn_outputs_get函数获取推理的输出,进行后处理。在每次推理前,更新帧数据。通用API调用流程如下所示,黄色字体代表用户行为。
通用API接口示例代码可以参考:rknpu2/examples下
- rknn_multi_input_demo/src/main.cc
- rknn_ssd_demo/src/main.cc
- rknn_yolov5_demo/src/main.cc
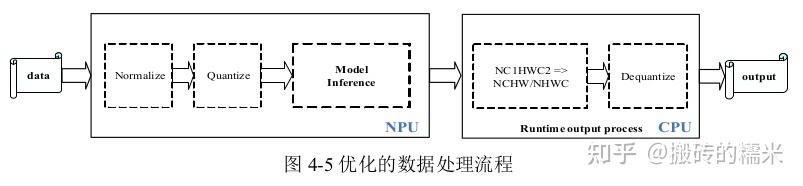
通用API接口内部存在以下两种处理流程:
1)int8量化模型且输入通道数是1或3或4
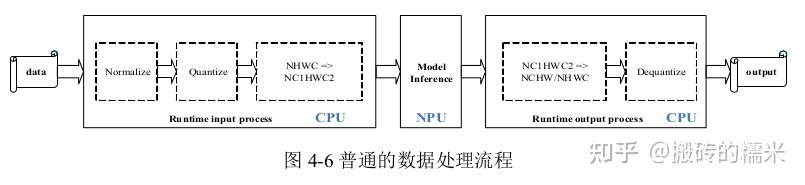
2)输入通道数是2或大于等于4的量化模型或非量化模型
============================== 手动分割线=======================================
对于零拷贝API接口,在分配内存后使用内存信息初始化rknn_tensor_memory结构体,在推理前创建并设置该结构体,并在推理后读取该结构体中的内存信息。根据用户是否需要自行分配模型的模块内存(输入/输出/权重/中间结果)和内存表示方式(文件描述符/物理地址等)差异,有下列三种典型的零拷贝调用流程:输入/输出内存由运行时分配(如下图所示);输入/输出内存由外部分配;输入/输出/权重/中间结果内存由外部分配。
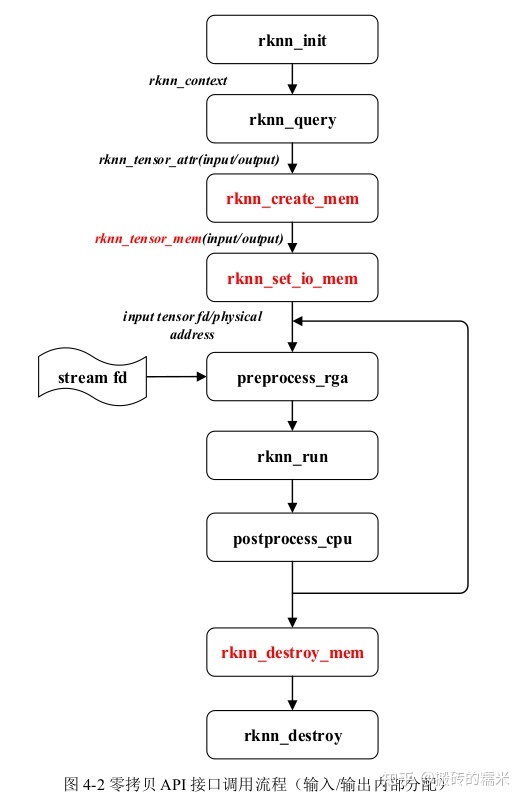
如上图所示,rknn_create_mem接口创建的输入/输出内存信息结构体包含了文件描述符成员和物理地址,RGA的接口使用到NPU分配的内存信息,preprocess_rga表示RGA的接口,steam_fd表示RGA的接口输入源的内存数据,postprocess_cpu表示处理后的CPU实现。
零拷贝API接口示例代码可以参考:rknpu2/examples下
- rknn_commen_test/src/main.cc
- rknn_mobilenet_demo/src/main.cc
零拷贝场景的使用条件如下:
1)输入通道数是1或3或4
2)RK356X输入的宽度是8像素对齐,RK3588和RV1106/RV1103输入宽度是16像素对齐
3)int8非对称量化模型
============================== 手动分割线=======================================
3.常用API(具体说明在rknpu2/doc/Rockchip_RKNPU_User_Guide_RKNN_API_V1.4.0_CN.pdf中)
(1) rknn_init: 初始化函数将创建rknn_context对象、加载RKNN模型以及根据flag和rknn_init_extend结构体执行特定的初始化行为。
rknn_context ctx;
int ret = rknn_init(&ctx, model_data, model_data_size, 0, NULL);
(2) rknn_set_core_mask: 指定函数的NPU核心,该函数仅支持RK3588平台。
rknn_context ctx;
rknn_core_mask core_mask = RKNN_NPU_CORE_0;
int ret = rknn_set_core_mask(ctx, core_mask);
(3) rknn_dup_context: 生成一个指向用一个模型的新context, 可用于多线程执行相同模型时的权重复用,支持RK3588芯片。
rknn_context ctx_in;
rknn_context ctx_out;
int ret = rknn_dup_context(&ctx_in, &ctx_out);
(4) rknn_destory: 将释放传入的rknn_context及其相关资源
rknn_context ctx;
int ret = rknn_destroy (ctx);
(5) rknn_query: 能够查询获取到模型输入输出信息、逐层运行时间、模型推理的总时间、SDK版本、内存占用信息、用户自定义字符串等信息。
- 查询SDK版本
- 查询输入输出tensor个数
- 查询通用tensor属性
- 查询输出tensor属性
- 查询模型推理的逐层耗时
- 查询模型推理的总耗时
- 查询模型的内存占用情况
- 查询模型里用户自定义字符串
- 查询原始输入tensor属性(用于零拷贝API接口)
- 查询原始输出tensor属性(用于零拷贝API接口)
(6) rknn_inputs_set: 设置模型的输入数据,该函数能够支持多个输入,其中每个输入是rknn_input结构体对象,在传入之前用户需要设置该对象。
(7) rknn_run: 执行一次推理,调用之前需要先通过rknn_inputs_set函数或者零拷贝的接口设置输入数据
ret = rknn_run(ctx, NULL);
(8) rknn_wait: 用于非阻塞模式推理,目前暂未实现。
(9) rknn_outputs_get: 获取模型推理的输出数据,该函数能够一次获取多个输出数据,其中每个输出是rknn_output结构体对象,在函数调用之前需要依次创建并设置每个rknn_output对象。
(10) rknn_outputs_release: 释放rknn_output_get函数得到的输出相关资源。
ret = rknn_outputs_release(ctx, io_num.n_output, outputs);
(11) rknn_create_mem_from_mb_blk: 目前暂未实现。
(12) rknn_create_mem_from_phys: 当用户要自己分配内存让NPU使用时,通过该函数可以创建一个rknn_tensor_mem结构体并得到它的指针,该函数通过传入物理地址、虚拟地址以及大小,外部内存相关的信息会赋值给rknn_tensor_mem结构体。
(13) rknn_create_mem_from_fd: 当用户要自己分配内存让NPU使用时,rknn_create_mem_from_fd函数可以创建一个rknn_tensor_mem结构体并得到它的指针,该函数通过传入文件描述符fd、偏移、虚拟地址以及大小,外部内存相关的信息会赋值给rknn_tensor_mem结构体。
(14) rknn_create_mem: 当用户要NPU内部分配内存时,rknn_create_mem函数可以创建一个rknn_tensor_mem结构体并得到它的指针,该函数通过传入内存大小,运行时会初始化rknn_tensor_mem结构体。
(15) rknn_destory_mem: 销毁rknn_tensor_mem结构体,用户分配的内存需要自行释放。
(16) rknn_set_weight_mem: 如果用户自己为网络权重分配内存,初始化相应的rknn_tensor_mem结构体后,在调用rknn_run前,通过rknn_set_weight_mem函数可以让NPU使用该内存。
(17) rknn_set_internal_mem: 如果用户自己为网络中间tensor分配内存,初始化相应的rknn_tensor_mem结构体后,在调用rknn_run之前,通过rknn_set_internal_mem函数可以让NPU使用该内存。
(18) rknn_set_io_mem: 如果用户自己为网络输入/输出tensor分配内存,初始化相应的rknn_tensor_mem结构体后,在调用rknn_run之前,通过rknn_set_io_mem函数可以让NPU使用该内存。
4.RKNN数据结构定义
(1) rknn_sdk_version: 用来表示RKNN SDK版本信息
(2) rknn_input_output_num: 表示输入输出tensor个数
(3) rknn_tensor_attr: 表示模型的tensor的属性
(4) rknn_perf_detail: 表示模型性能详情
(5) rknn_perf_run: 表示模型的总体性能
(6) rknn_mem_size: 表示初始化模型时的内存分配情况
(7) rknn_tensor_mem: 表示tensor的内存信息
(8) rknn_input: 表示模型的一个数据输入,用来作为参数传入给rknn_inputs_set函数
(9) rknn_output: 表示模型的一个输入输出,用来作为参数传入给rknn_outputs_get函数,在函数执行后,结构体将被赋值。
(10) rknn_init_extend: 表示初始化模型时的扩展信息。
(11) rknn_run_extend: 表示模型推理时的扩展信息。
(12) rknn_output_extend: 表示获取输出的扩展信息。
(13) rknn_custom_string: 表示转换RKNN模型时,用户设置的自定义字符串。
5.输入输出API详细说明
通过输入输出API: rknn_inputs_set, rknn_outputs_get
零拷贝输入输出API: rknn_create_mem, rknn_set_io_mem
六. 板端代码开发(Python API)
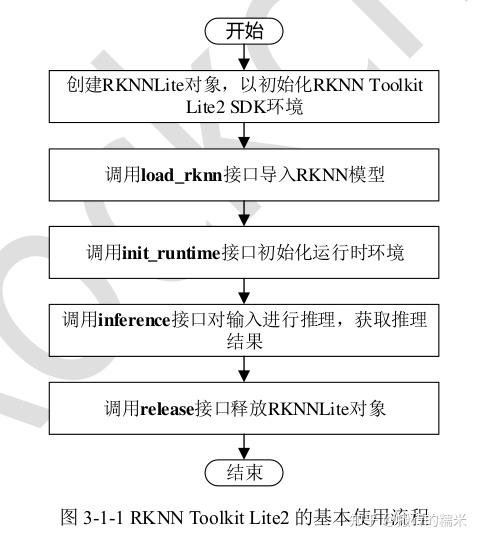
1.基本使用流程(官方手册在rknn-toolkit2-1.3.0/rknn_toolkit_lite2/docs下)
2. API详细说明
1)RKNNLite对象初始化以及对象释放:
rknn_lite = RKNNLite()
rknn_lite.release()
- 加载RKNN模型:
ret = rknn_lite.load_rknn('RKNN模型文件路径')
- 初始化运行时环境
ret = rknn_lite.init_runtime(core_mask=RKNNLite.NPU_CORE_AUTO)
if ret != 0:
print('Init runtime environment failed')
exit(ret)
- 模型推理
results = rknn_lite.inference(inputs=[img])
- 查询SDK版本
sdk_version = rknn_lite.get_sdk_version()
- 查询模型可运行平台
rknn_lite.list_support_target_platform(rknn_model=’mobilenet_v1.rknn’)
3. 示例代码
请见rknn-toolkit2-1.3.0/rknn_toolkit_lite2/examples/inference_with_lite/test.py
七. 报错解决:
1. 在.pth转.onnx时遇到报错,RuntimeError: Exporting the operator broadcast_tensors to ONNX opset version 9 is not supported. Please open a bug to request ONNX export support for the missing operator.
解决方法:当前pytorch版本不支持Normal操作,更新pytorch至11.0及以上即可。
2. 在.onnx转.rknn时遇到报错,Fatal: Meet unsupported operator: Expand(name=“/Expand”).
使用
查看模型结构,可以看到确实有Expand这个operator, 通过分析代码发现这个操作可以去掉。重新执行pytorch转onnx的过程,得到不包含Expand operator的onnx模型,然后再进行onnx转rknn的操作。
3. ImportError: libpython3.6m.so.1.0: cannot open shared object file: No such file or directory
解决方法:重新安装rknn-toolkit2即可。
八. 推理精度有问题时的排查


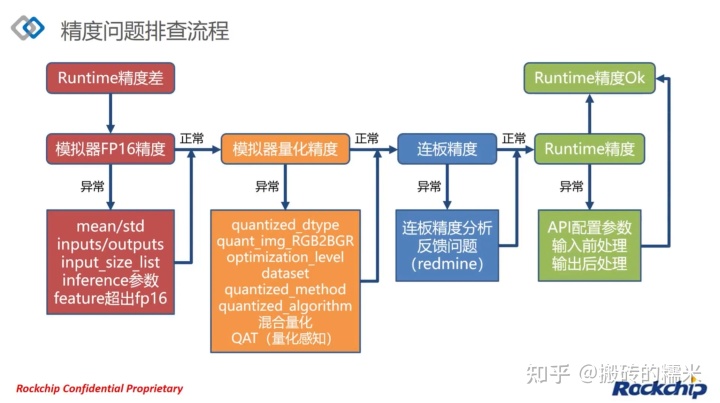
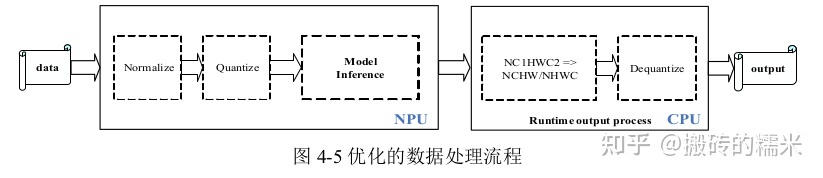
1.精度分析工具:

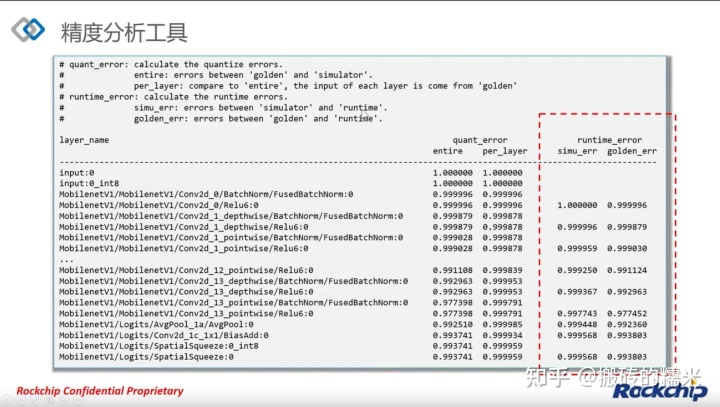
quant_error: 余弦距离,余弦相似性,越接近1表示精度越高
entire: 误差是累积的,表示的是模型每层真实的误差损失情况
per_layer: 单层的误差损失,用于评估该层本身的精度损失情况

2. 模拟器精度排查
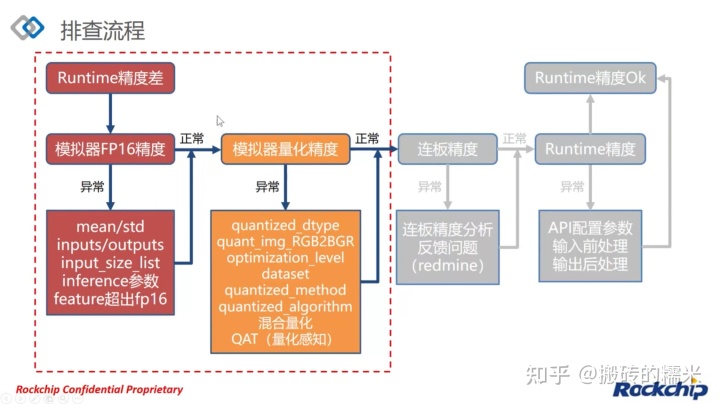






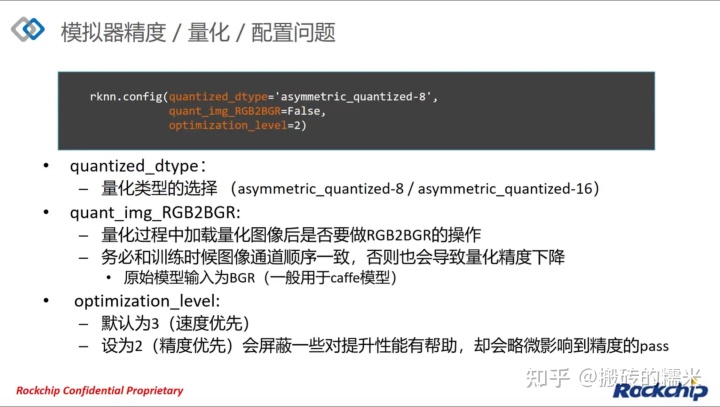










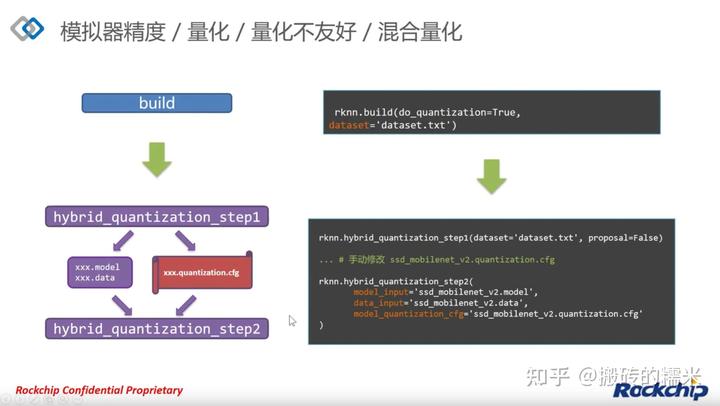
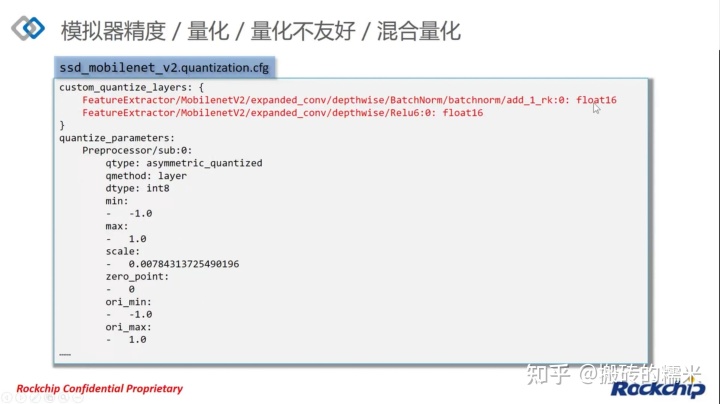
当设置proposal=True时



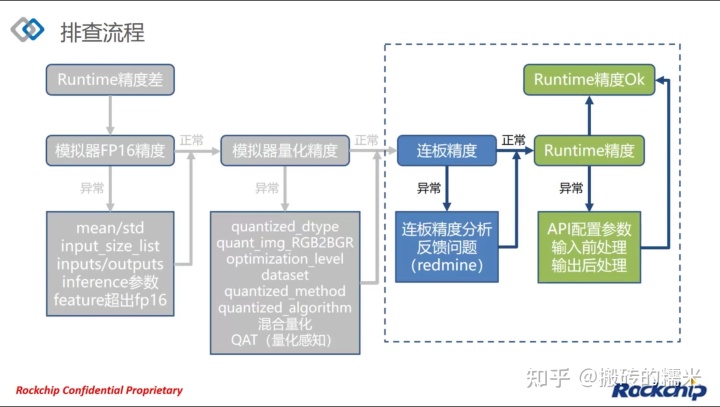
三、板端量化精度筛查


















 2056
2056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









