







每次回头看一些c的基础知识,都有新感觉,觉得这个怎么以前没见到过,靠,这么吊,这又是啥。零零碎碎的东西太多,脑子瞬间感觉不够用啦。
一些基础的就不在这啰嗦了,记录一些不常用的点,以后再来看,不用再翻箱倒柜的找了。
1.函数的缺省认定
这个主要提到函数原型的重要性,函数原型的作用就是让编译器知道函数的参数数量和类型,以及返回值类型。如果没有原型,直接调用,编译器是默认返回整型。
float f;
f = xyz();
在函数调用之前,编译器没能见到它的原型,便认定函数返回一个整型值。
2.函数的参数为数组名时
c函数的参数都是以“传值调用”方式来进行传递的。获得参数值的一份拷贝。当传递的参数使数组名时,函数中使用下标对数组元素修改时,实际修改的是调用程序的数组元素。看似好像是进行的是“传地址调用”,实际上,还是传值调用,只不过拷贝的是指针,这个指针也能访问内存中的位置。
3.函数的参数为数组时,为什么要同时有长度参数
在声明数组参数时不指定它的长度是合法的,因为函数并不为数组分配内存,而是访问调用程序中的数组元素。但是函数没用办法判断数组的长度,所以需要长度参数。
void clear_array( int array[],int length)
4.ADT(抽象数据类型)
就是限定用户的访问权限,隐藏具体的实现细节,用户只能也只用调用那些已经定义好的接口。这些就是c++中的封装特性。在c中主要通过关键字static来实现的,在函数之前加上static,这样就只能本文件内调用了,具有内部链接属性。
5.递归的讨论
一直递归都是我的痛处,老是纠缠于它的执行过程,想几个循环之后感觉就懵逼了。c和指针上的话说的很好:阅读递归的方法就是要相信递归函数会顺利完成任务。不要纠结于它的执行过程。如果你的限制条件正确,每个步骤正确,递归函数总是能正确完成任务。
c是通过运行时堆栈支持递归函数的实现。
递归原理:
当函数被调用时,它的变量的空间是创建于运行时的堆栈上的,如果在函数调用期间,又调用了其他的函数,则原理的变量仍保留在堆栈上,不过被新的函数的变量掩盖。
对于递归函数,当调用自身的时候,每调用一次自己,将创建一批新的变量,将掩盖递归函数前一次调用自己所创建的变量。当递归结束条件为真时,依次返回函数。
书上将的还是很清楚的,以4267为值调用递归函数,开始执行,堆栈的内容如图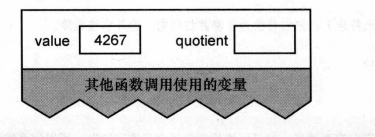
执行除法运算后:
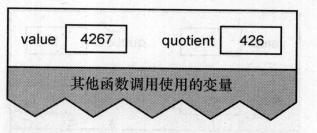
判断条件非真,递归调用

继续判断:
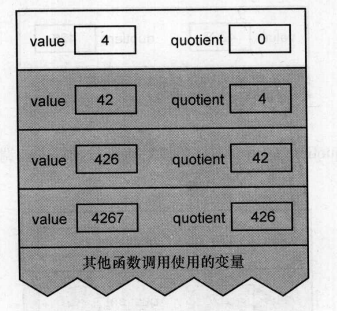
现在quotient变为零,递归函数不再调用自身,开始打印输出。然后函数返回,开始销毁堆栈上的变量值。
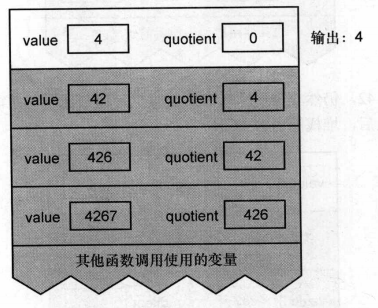
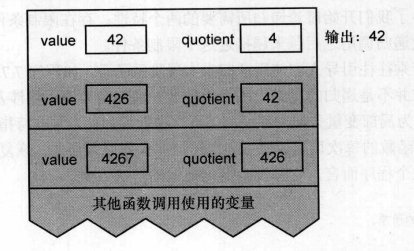
最后回到调用的起点。
递归的优点就是结构清晰,可读性高。
当然递归不是万能的,因为递归不断为局部变量分配内存空间,开销很大,而且有时候会重复计算,有时候简单的循环或者迭代也会起到很好的效果。
6.可变参数列表
这个在实际中用的比较少,一般我们的参数个数和类型在原型中已经声明好了,当时在项目中看到别人用到,感觉好神奇。但是感觉数组也能实现。
可变参数列表通过宏来实现的,stdarg.h ,它声明了一个类型va_list和三个宏va_start ,va_arg,va_end。
/*计算指定数量的值的平均值*/
#include <stdarg.h>
float average(int n_values,...)
{
va_list var; //用于访问参数列表中未确定的部分
int count;
float sum = 0;
va_start(var,n_values);//初始化,第二个参数是省略号前最后一个参数。
for(count =0;count < n_values ;count++)
sum +=va_arg(var,int); //va_arg返回参数的值,将var指向下一个可变参数
va_end(var);
return sum/n_values;
}缺点:
1,无法判断实际存在的参数数量
2,无法判断每个参数的类型,注意va_arg中使用类型















 3981
3981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









