







1.机器学习概述
1.1 分类
监督学习(Supervised Learning)
无监督学习(Unspervised Learning)
强化学习(Reinforcement Learning)
1.2 基本用语
1.自变量
实验或者建模里用到的录入值或者原因对应的变量
也叫录入变量,说明变量
2.因变量
实验或者建模里结果或者效果对应的变量,类似于函数值
也叫输出变量
3.学习模型
为了在电脑上展示显示的因果关系,用单纯抽象化的一种概念模型
主要是为了展示因变量、自变量
2.监督学习
2.1 定义
学习可以活用已知类别的数据中的自变量来预测因变量(正确答案)的学习模型的开发方法。监督学习是从标记的训练数据来推断一个功能的机器学习任务。
2.2 特征
1.针对预测结果存在正确答案
2.对学习模型的评价以及优化
2.3 代表分析方法
1.回归(regression)
对大量统计数据进行数学处理,并确定因变量与某些自变量的相关关系,建立一个相关性较好的回归方程(函数表达式)
根据因变量和自变量的函数表达式分为:线性回归分析和非线性回归分析。

2.分类(Classification)
分类是一种基本的数据分析方式,根据其特点,可将数据对象划分为不同的部分和类型,再进一步分析,能够进一步挖掘事物的本质

分类算法:
1.逻辑回归 Logistic Regression
2.K最近邻居算法 KNN(k-Nearest Neighbor)
3.Naïve Bayes (朴素贝叶斯)
4.决策树Decision Tree
2.4 举例
1.身高/体重模型:用身高数据来预测体重
2.射箭模型:根据箭的长短,重量调整射箭力度
3.非监督学习
3.1 定义
根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习
3.2 特征
1.对于预期结果的正确答案:无
2.对于学习模型难以评价/优化
3.3 代表分析方法
1.集群
2.降维
3.4 举例
一个孩子,在一开始认识事物的时候,父母会给他一些苹果和橘子,但是并不告诉他哪儿个是苹果,哪儿个是橘子,而是让他自己根据两个事物的特征自己进行判断,会把苹果和橘子分到两个不同组中,下次再给孩子一个苹果,他会把苹果分到苹果组中,而不是分到橘子组中。
4. 回归分析
python库:
numpy --处理数组
statsmodels --创建回归
pandas --增强numpy
scipy – 包含大量计算,可视化函数库
sklearn --机器学习
matplotlib --二维绘图,表现numpy
seaborn
4.1 简单线性回归示例
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
#读取数据
data = pd.read_csv("1.01. Simple linear regression.csv")
#描述数据
print(data.describe())
"""
SAT GPA
count 84.000000 84.000000
mean 1845.273810 3.330238
std 104.530661 0.271617
min 1634.000000 2.400000
25% 1772.000000 3.190000
50% 1846.000000 3.380000
75% 1934.000000 3.502500
max 2050.000000 3.810000
"""
# 1.假设两个变量存在回归关系
# y = b0 + b1x1
y = data["GPA"]
x1 = data["SAT"]
#1.1 绘图
plt.scatter(x1,y)
plt.xlabel("SAT",fontsize=20)
plt.ylabel("GPA",fontsize=20)
plt.show() # 如图1
#1.2 拟合
x = sm.add_constant(x1)
results = sm.OLS(y,x).fit()
print(results.summary()) #如图2
#1.3 绘制最优拟合线
plt.scatter(x1,y)
yhat = 0.0017*x1 + 0.275
fig = plt.plot(x1,yhat, lw=4, c="orange", label="regression line")
plt.xlabel("SAT",fontsize=20)
plt.ylabel("GPA",fontsize=20)
plt.show() #如图3
图1


图2

图3

4.2 变异性的分解
1.总离差查平方和 SST
已观察到的因变量机器平均值之间的差值平方和

2.回归平方和 SSR
预测值和平均值的差值平方和

如果SSR=SST, 那么这个模型就很完美
3.误差平方和 SSE
观察到的数值与预测数值的差值平方和
SSE = SST - SSR
误差越小,则估计能力越高

4.R^2
R^2 = 回归解释的可变性/总可变性 = SSR/SST
4.3 多重线性回归
房价不仅仅取决于房子大小,可能还取决于周围环境等。
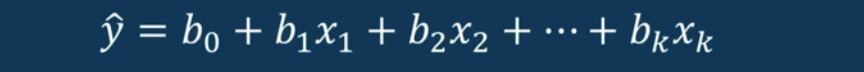
4.3.1 示例
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
#美化图表样式
import seaborn as sns
sns.set()
#读取数据
data = pd.read_csv("1.02. Multiple linear regression.csv")
# print(data.describe())
"""
" SAT GPA Rand 1,2,3
count 84.000000 84.000000 84.000000
mean 1845.273810 3.330238 2.059524
std 104.530661 0.271617 0.855192
min 1634.000000 2.400000 1.000000
25% 1772.000000 3.190000 1.000000
50% 1846.000000 3.380000 2.000000
75% 1934.000000 3.502500 3.000000
max 2050.000000 3.810000 3.000000
"""
# # 1.假设存在多元回归关系
# # y = b0 + b1x1 + b2*Rand1,2,3
y = data["GPA"]
x1 = data[["SAT", "Rand 1,2,3"]]
x = sm.add_constant(x1)
result = sm.OLS(y,x).fit()
print(result.summary())

因为Rand1,2,3的p值大于0.05, 所以我们不能拒绝76%显著性水平的零假设,而且变量Rand1,2,3反而使得分析偏差更大了。
4.3.2 F-Test
H0:同时让所有β为0
H1: 至少有一个β不为0
4.3.3 示例(引入相关变量)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
#美化图表样式
import seaborn as sns
sns.set()
#读取数据
data = pd.read_csv("1.03. Dummies.csv")
# 标记Attendance
data = data.copy()
data["Attendance"] = data["Attendance"].map({"Yes":1,"No":0})
# print(data.describe())
"""
SAT GPA Attendance
count 84.000000 84.000000 84.000000
mean 1845.273810 3.330238 0.464286
std 104.530661 0.271617 0.501718
min 1634.000000 2.400000 0.000000
25% 1772.000000 3.190000 0.000000
50% 1846.000000 3.380000 0.000000
75% 1934.000000 3.502500 1.000000
max 2050.000000 3.810000 1.000000
"""
# # 1.假设存在多元回归关系
# # y = b0 + b1x1 + b2*Rand1,2,3
y = data["GPA"]
x1 = data[["SAT", "Attendance"]]
x = sm.add_constant(x1)
result = sm.OLS(y,x).fit()
print(result.summary())

我们发现调整R方升高了。
GPA = 0.6439 + 0.0014SAT + 0.2226Dummy
当Attendance为1:GPA = 0.6439 + 0.0014SAT + 0.22261=0.8665 +0.0014SAT
当Attendance为0:GPA = 0.6439 + 0.0014SAT + 0.22260=0.6439 + 0.0014SAT
绘制数据
##绘制数据
plt.scatter(data["SAT"], y, c=data["Attendance"], cmap="YlGnBu") #给点标记颜色
yhat_no = 0.6439 + 0.0014*data["SAT"]
yhat_yes = 0.8665 + 0.0014*data["SAT"]
fig = plt.plot(data["SAT"], yhat_no, lw=2, c="red")
fig = plt.plot(data["SAT"], yhat_yes, lw=2, c="green")
plt.xlabel("SAT", fontsize=20)
plt.xlabel("GPA", fontsize=20)
plt.sh

加入原回归线
##加入原回归线
plt.scatter(data["SAT"], y, c=data["Attendance"], cmap="YlGnBu") #给点标记颜色
yhat_no = 0.6439 + 0.0014*data["SAT"]
yhat_yes = 0.8665 + 0.0014*data["SAT"]
yhat = 0.0017*data["SAT"] + 0.275
fig = plt.plot(data["SAT"], yhat_no, lw=2, c="red", label="regression line1")
fig = plt.plot(data["SAT"], yhat_yes, lw=2, c="green", label="regression line2")
fig = plt.plot(data["SAT"], yhat, lw=2, c="blue", label="regression line")
plt.xlabel("SAT", fontsize=20)
plt.xlabel("GPA", fontsize=20)
plt.show()

预测
# # 1.假设存在多元回归关系
# # y = b0 + b1x1 + b2*Rand1,2,3
y = data["GPA"]
x1 = data[["SAT", "Attendance"]]
x = sm.add_constant(x1)
result = sm.OLS(y,x).fit()
# print(x) #由3列数据组成
"""
const SAT Attendance
0 1.0 1714 0
1 1.0 1664 0
2 1.0 1760 0
3 1.0 1685 0
4 1.0 1693 0
.. ... ... ...
79 1.0 1936 1
80 1.0 1810 1
81 1.0 1987 0
82 1.0 1962 1
83 1.0 2050 1
[84 rows x 3 columns]
"""
# 如果我们检查两个学生,
# A:SAT得到1700,并且参加课程数未超过75%
# B:SAT得到1670,并且参加课程数超过75%
new_data = pd.DataFrame({"const":1,"SAT":[1700,1670],"Attendance":[0,1]})
new_data = new_data[["const","SAT","Attendance"]]
print(new_data)
"""
const SAT Attendance
0 1 1700 0
1 1 1670 1
"""
new_data= new_data.rename(index={0:"A",1:"B"})
print(new_data)
"""
const SAT Attendance
A 1 1700 0
B 1 1670 1
"""
#预测
prodictions = result.predict(new_data)
print(prodictions)
#结果包含两个预测
"""
A 3.023513
B 3.204163
dtype: float64
"""
#转换为数据帧
prodictionsdf = pd.DataFrame({"Prodictions":prodictions})
joined = new_data.join(prodictionsdf)
joined.rename(index={0:"A",1:"B"})
print(joined)
"""
const SAT Attendance Prodictions
A 1 1700 0 3.023513
B 1 1670 1 3.204163
"""
#结论:
#A毕业时大概可以得到学分3.023513
#B毕业时大概可以得到学分3.204163
5.Scikit-learn–线性回归
5.1 相关库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
from sklearn.linear_model import LinearRegression
5.2 基础
# # # 2.加载数据
# # data = pd.read_csv("1.01. Simple linear regression.csv")
# # # 3.创建回归
# # ## 3.1 申明自变量和因变量
# # x = data["SAT"]
# # x_matrix = x.values.reshape(-1,1)
# # y = data["GPA"]
# # ## 3.2 创建回归对象
# # reg = LinearRegression()
# # ## 3.3 拟合回归
# # reg.fit(x_matrix,y)
# # # LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
# #
# # #R方
# # print(reg.score(x_matrix,y)) #0.40600391479679765
# # #截距
# # print(reg.intercept_) #0.27504029966028076
# # #系数
# # print(reg.coef_) #[0.00165569]
# #
# # #预测:输入x得到y
# # print(reg.predict(np.array(1740).reshape(-1, 1))) #[3.15593751]
# #
# # new_data = pd.DataFrame(data=[1740,1760], columns=["SAT"])
# # print(reg.predict(new_data)) #[3.15593751 3.18905127]
# #
# # #添加到原始数据框
# # new_data["Predicted_GPA"] = reg.predict(new_data)
# # print(new_data)
# # """
# # SAT Predicted_GPA
# # 0 1740 3.155938
# # 1 1760 3.189051
# # """
# #
# # #绘制回归线
# # plt.scatter(x,y)
# # yhat = reg.coef_*x_matrix + reg.intercept_
# # fig = plt.plot(x, yhat, lw=4, c="red", label="regression line")
# # plt.xlabel("SAT", fontsize=20)
# # plt.xlabel("GPA", fontsize=20)
# # plt.show()
#
#
# #多重那个线性回归
# import numpy as np
# import pandas as pd
# import matplotlib.pyplot as plt
# import seaborn as sns
# sns.set()
#
# from sklearn.linear_model import LinearRegression
#
# #读取数据
# data = pd.read_csv("1.02. Multiple linear regression.csv")
# print(data.head())
#
# """
# SAT GPA Rand 1,2,3
# 0 1714 2.40 1
# 1 1664 2.52 3
# 2 1760 2.54 3
# 3 1685 2.74 3
# 4 1693 2.83 2
# """
# print(data.describe())
# """
# SAT GPA Rand 1,2,3
# count 84.000000 84.000000 84.000000
# mean 1845.273810 3.330238 2.059524
# std 104.530661 0.271617 0.855192
# min 1634.000000 2.400000 1.000000
# 25% 1772.000000 3.190000 1.000000
# 50% 1846.000000 3.380000 2.000000
# 75% 1934.000000 3.502500 3.000000
# max 2050.000000 3.810000 3.000000
# """
#
# #创建回归
# x = data[["SAT","Rand 1,2,3"]]
# y = data["GPA"]
# reg = LinearRegression()
# #拟合回归
# reg.fit(x,y)
#
# #两个变量的系数
# print(reg.coef_) #[ 0.00165354 -0.00826982]
#
# #截距
# print(reg.intercept_) #0.29603261264909486
#
# #R方
# r = reg.score(x,y)
# print(r) #0.4066811952814282
#
# #调整后的R方
# # R_adj = 1 - (1-R**2)*(n-1)/(n-p-1)
# """
# R**2: reg.score(x,y)
# # print(x.shape) (84, 2)
# n : 观察值
# p: 预测数
# """
# r2 = reg.score(x,y)
# n = x.shape[0]
# p = x.shape[1]
# adj_r2 = 1- (1-r2)*(n-1)/(n-p-1)
# print(adj_r2) #0.39203134825134
#
# #建测模型中不必要的变量 (p值大于0.5,我们就可以忽略变量)
# """
# 分别以每个变量创建回归,可以得到各自的p值
# """
# from sklearn.feature_selection import f_regression
#
# f = f_regression(x, y)
# print(f) #(array([56.04804786, 0.17558437]), array([7.19951844e-11, 6.76291372e-01]))
# #P值
# p_values = f_regression(x, y)[1]
# print(p_values) #[7.19951844e-11 6.76291372e-01]
# #保留三位小数
# print(p_values.round(3)) #[0. 0.676]
# #结论,SAT变量是有用的,Rand 1,2,3是无用的
#
# #把数据整理成表格
# reg_summary = pd.DataFrame(data=x.columns.values, columns=["Features"])
# print(reg_summary)
# """
# Features
# 0 SAT
# 1 Rand 1,2,3
# """
# reg_summary["Coefficients"] = reg.coef_
# reg_summary["p-values"] = p_values.round(3)
# print(reg_summary)
# """
# Features Coefficients p-values
# 0 SAT 0.001654 0.000
# 1 Rand 1,2,3 -0.008270 0.676
# """
#
# #功能缩放(标准化)
# from sklearn.preprocessing import StandardScaler
# scaler = StandardScaler()
# result = scaler.fit(x)
# x_scaled = scaler.transform(x)
# print(x_scaled)
#
# #拟合缩放
# reg = LinearRegression()
# reg.fit(x_scaled,y)
# print(reg.coef_)
# print(reg.intercept_)
#
# #添加到数据框架
# reg_summary = pd.DataFrame([["Intercept"],["SAT"],["Rand 1,2,3"]], columns=["Features"])
# reg_summary["Weights"] = reg.intercept_, reg.coef_[0],reg.coef_[1]
# print(reg_summary)
# """
# Weights:权重越接近0,影响越小
# Features Weights
# 0 Intercept 3.330238
# 1 SAT 0.171814
# 2 Rand 1,2,3 -0.007030
# """
# #使用标准化模型预测价值
# new_data = pd.DataFrame(data=[[1700,2],[1800,1]],columns=["SAT","Rand 1,2,3"])
# print(new_data)
# """
# SAT Rand 1,2,3
# 0 1700 2
# 1 1800 1
# """
# result = reg.predict(new_data)
# print(result) #[295.39979563 312.58821497], 我们发现预测值误差很大
# #被预测的数据也必须标准化
# new_data_scaled = scaler.transform(new_data)
# print(new_data_scaled)
#
# """
# [[-1.39811928 -0.07002087]
# [-0.43571643 -1.24637147]]
# """
# #使用标准化后的数据重新预测
# result = reg.predict(new_data_scaled)
# print(result.round(2)) #[3.09 3.26]
#
# #因为之前我得到结论:Rand 1,2,3对预测值几乎没有任何影响, 所以我们移除它预测,预测值是不变的
# reg_simple = LinearRegression()
# x_simple_matrix = x_scaled[:,0].reshape(-1,1)
# reg_simple.fit(x_simple_matrix,y)
# result = reg_simple.predict(new_data_scaled[:,0].reshape(-1,1))
# print(result.round(2)) #[3.09 3.26]
#
#
# #常见问题:
# # 1 过度拟合:过拟合是指为了得到一致假设而使假设变得过度严格
# # 我们需要将数据分为两部分:训练和测试
#
# # 2.低度拟合:模型没有捕获到数据的基本逻辑
#
# #怎么分割训练和测试数据
# import numpy as np
# from sklearn.model_selection import train_test_split
# #创建两个数组
# a = np.arange(1,101)
# b = np.arange(501,601)
#
# #分割数据
# # a_train, a_test = train_test_split(a,test_size=0.2)
# a_train, a_test, b_train, b_test = train_test_split(a, b,test_size=0.2,random_state=42)
# # a_train, a_test = train_test_split(a,test_size=0.2,shuffle=False)
# #test_size:2,8原则, shuffle:数据是否被打乱,random_state每次筛分的数据集相同
# print(a_test)
# print(b_test)
#
5.3 实例:汽车销售–根据二手车的规格预测二手车的价格
#
# # 1.导入相关库
# import numpy as np
# import pandas as pd
# import matplotlib.pyplot as plt
# import seaborn as sns
# sns.set()
#
# from sklearn.linear_model import LinearRegression
# # 2.加载数据
# raw_data = pd.read_csv("1.04. Real-life example.csv")
# print(raw_data.head())
# """
# Brand Price Body ... Registration Year Model
# 0 BMW 4200.0 sedan ... yes 1991 320
# 1 Mercedes-Benz 7900.0 van ... yes 1999 Sprinter 212
# 2 Mercedes-Benz 13300.0 sedan ... yes 2003 S 500
# 3 Audi 23000.0 crossover ... yes 2007 Q7
# 4 Toyota 18300.0 crossover ... yes 2011 Rav 4
#
# [5 rows x 9 columns]
# """
# # 3.清理数据
# ## 3.1 探索数据
# print(raw_data.describe(include="all"))
# """
# Brand Price Body ... Registration Year Model
# count 4345 4173.000000 4345 ... 4345 4345.000000 4345
# unique 7 NaN 6 ... 2 NaN 312
# top Volkswagen NaN sedan ... yes NaN E-Class
# freq 936 NaN 1649 ... 3947 NaN 199
# mean NaN 19418.746935 NaN ... NaN 2006.550058 NaN
# std NaN 25584.242620 NaN ... NaN 6.719097 NaN
# min NaN 600.000000 NaN ... NaN 1969.000000 NaN
# 25% NaN 6999.000000 NaN ... NaN 2003.000000 NaN
# 50% NaN 11500.000000 NaN ... NaN 2008.000000 NaN
# 75% NaN 21700.000000 NaN ... NaN 2012.000000 NaN
# max NaN 300000.000000 NaN ... NaN 2016.000000 NaN
#
# [11 rows x 9 columns]
# """
# ## 3.2 删除变量
# data = raw_data.drop(["Model"], axis=1)
# print(data.describe(include="all"))
# """
# Brand Price Body ... Engine Type Registration Year
# count 4345 4173.000000 4345 ... 4345 4345 4345.000000
# unique 7 NaN 6 ... 4 2 NaN
# top Volkswagen NaN sedan ... Diesel yes NaN
# freq 936 NaN 1649 ... 2019 3947 NaN
# mean NaN 19418.746935 NaN ... NaN NaN 2006.550058
# std NaN 25584.242620 NaN ... NaN NaN 6.719097
# min NaN 600.000000 NaN ... NaN NaN 1969.000000
# 25% NaN 6999.000000 NaN ... NaN NaN 2003.000000
# 50% NaN 11500.000000 NaN ... NaN NaN 2008.000000
# 75% NaN 21700.000000 NaN ... NaN NaN 2012.000000
# max NaN 300000.000000 NaN ... NaN NaN 2016.000000
#
# [11 rows x 8 columns]
# """
# ## 3.2 数据预处理
# ### 3.2.1 判断是否为空
# print(data.isnull())
# """
# Brand Price Body Mileage EngineV Engine Type Registration Year
# 0 False False False False False False False False
# 1 False False False False False False False False
# 2 False False False False False False False False
# 3 False False False False False False False False
# 4 False False False False False False False False
# ... ... ... ... ... ... ... ... ...
# 4340 False False False False False False False False
# 4341 False False False False False False False False
# 4342 False False False False False False False False
# 4343 False False False False True False False False
# 4344 False False False False False False False False
#
# [4345 rows x 8 columns]
# """
# ### 3.2.2 统计空数据
# print(data.isnull().sum())
# """
# Brand 0
# Price 172
# Body 0
# Mileage 0
# EngineV 150
# Engine Type 0
# Registration 0
# Year 0
# dtype: int64
# """
# ### 3.2.3 删除存在缺省值的观测数据
# # 经验:
# """
# 1.如果删除的观测值少于5%,则可以直接删除
# """
# data_no_mv = data.dropna(axis=0)
# print(data_no_mv.describe(include="all"))
# """
# Brand Price Body ... Engine Type Registration Year
# count 4025 4025.000000 4025 ... 4025 4025 4025.000000
# unique 7 NaN 6 ... 4 2 NaN
# top Volkswagen NaN sedan ... Diesel yes NaN
# freq 880 NaN 1534 ... 1861 3654 NaN
# mean NaN 19552.308065 NaN ... NaN NaN 2006.379627
# std NaN 25815.734988 NaN ... NaN NaN 6.695595
# min NaN 600.000000 NaN ... NaN NaN 1969.000000
# 25% NaN 6999.000000 NaN ... NaN NaN 2003.000000
# 50% NaN 11500.000000 NaN ... NaN NaN 2007.000000
# 75% NaN 21900.000000 NaN ... NaN NaN 2012.000000
# max NaN 300000.000000 NaN ... NaN NaN 2016.000000
#
# [11 rows x 8 columns]
#
# """
# ### 3.2.4 探索概率分布函数
# # sns.displot(data_no_mv["Price"])
# # plt.show() #我们预期想得到一个正态分布,实际上不是
#
# ## 3.2.5 剔除异常值
# # 异常值:于其他观测值举例异常的观测值,会影响回归
# #经验:删除前1%的观测结果(百分位数)
# # 例如:将数据保持在99%以下的百分位数
# q = data_no_mv["Price"].quantile(0.99)
# print(q) #129812.51999999981
# # 保留只低于99%的观测值
# data1 = data_no_mv[data_no_mv["Price"]<q]
# print(data1.describe())
# """
# Price Mileage EngineV Year
# count 3984.000000 3984.000000 3984.000000 3984.000000
# mean 17837.117460 165.116466 2.743770 2006.292922
# std 18976.268315 102.766126 4.956057 6.672745
# min 600.000000 0.000000 0.600000 1969.000000
# 25% 6980.000000 93.000000 1.800000 2002.750000
# 50% 11400.000000 160.000000 2.200000 2007.000000
# 75% 21000.000000 230.000000 3.000000 2011.000000
# max 129222.000000 980.000000 99.990000 2016.000000
# """
#
# ### 3.2.6 再次检查探索概率分布函数
# # sns.displot(data1["Price"])
#
# # 里程:Mileage也是类似
# q = data1["Mileage"].quantile(0.99)
# data2 = data1[data1["Mileage"]<q]
# # sns.displot(data2["Mileage"])
# # plt.show()
#
# # 发动机的容积
# EngV = pd.DataFrame(raw_data["EngineV"])
# EngV = EngV.dropna(axis=0)
# EngV.sort_values(by="EngineV")
# # print(EngV)
# #标记异常值:通过查询,我们知道生活中的发动机容积最高为6.5
# data3 = data2[data2["EngineV"]<6.5]
# # sns.displot(data3["EngineV"])
#
# # Year
# q = data3["Year"].quantile(0.01)
# data4 = data3[data3["Year"]>q]
# # sns.displot(data4["Year"])
#
# #最终数据
# data_cleaned = data4.reset_index(drop=True)
# print(data_cleaned.describe(include="all"))
# """
# Brand Price Body ... Engine Type Registration Year
# count 3867 3867.000000 3867 ... 3867 3867 3867.000000
# unique 7 NaN 6 ... 4 2 NaN
# top Volkswagen NaN sedan ... Diesel yes NaN
# freq 848 NaN 1467 ... 1807 3505 NaN
# mean NaN 18194.455679 NaN ... NaN NaN 2006.709853
# std NaN 19085.855165 NaN ... NaN NaN 6.103870
# min NaN 800.000000 NaN ... NaN NaN 1988.000000
# 25% NaN 7200.000000 NaN ... NaN NaN 2003.000000
# 50% NaN 11700.000000 NaN ... NaN NaN 2008.000000
# 75% NaN 21700.000000 NaN ... NaN NaN 2012.000000
# max NaN 129222.000000 NaN ... NaN NaN 2016.000000
#
# [11 rows x 8 columns]
#
# """
# ## 3.3 检查OLS假设
# #用散点图检查线性
# # f, (ax1,ax2,ax3) = plt.subplots(1,3,sharey=True, figsize=(15,3))
# # ax1.scatter(data_cleaned["Year"], data_cleaned["Price"])
# # ax1.set_title("Price&Year")
# # ax2.scatter(data_cleaned["EngineV"], data_cleaned["Price"])
# # ax2.set_title("Price&EngineV")
# # ax3.scatter(data_cleaned["Mileage"], data_cleaned["Price"])
# # ax3.set_title("Price&Mileage")
# # sns.displot(data_cleaned["Price"]) #我们发现价格不是正态分布的,是指数型的
# # plt.show()
#
# #取价格的对数,再次绘制
# log_price = np.log(data_cleaned["Price"])
# data_cleaned["log_price"] = log_price
# print(data_cleaned.head())
# """
# Brand Price Body ... Registration Year log_price
# 0 BMW 4200.0 sedan ... yes 1991 8.342840
# 1 Mercedes-Benz 7900.0 van ... yes 1999 8.974618
# 2 Mercedes-Benz 13300.0 sedan ... yes 2003 9.495519
# 3 Audi 23000.0 crossover ... yes 2007 10.043249
# 4 Toyota 18300.0 crossover ... yes 2011 9.814656
#
# [5 rows x 9 columns]
# """
# # f, (ax1,ax2,ax3) = plt.subplots(1,3,sharey=True, figsize=(15,3))
# # ax1.scatter(data_cleaned["Year"], data_cleaned["log_price"])
# # ax1.set_title("log_price&Year")
# # ax2.scatter(data_cleaned["EngineV"], data_cleaned["log_price"])
# # ax2.set_title("log_price&EngineV")
# # ax3.scatter(data_cleaned["Mileage"], data_cleaned["log_price"])
# # ax3.set_title("log_price&Mileage")
# # sns.displot(data_cleaned["log_price"])
# # plt.show()
# #删除列Price
# data_cleaned = data_cleaned.drop(["Price"],axis=1)
#
# #3.4数据可能存在多重共线性(vif:方差膨胀因子)
# from statsmodels.stats.outliers_influence import variance_inflation_factor
# variables = data_cleaned[["Mileage","EngineV", "Year"]]
# vif = pd.DataFrame()
# vif["VIF"] = [variance_inflation_factor(variables.values, i) for i in range(variables.shape[1])]
# vif["features"] = variables.columns
# print(vif)
#
# """
# VIF features
# 0 3.791584 Mileage
# 1 7.662068 EngineV
# 2 10.354854 Year
# vif=1:没有多重共线性
# 1<vif<5:是完全正常的
# vif>10:不正常
# """
# data_no_multicollinearity = data_cleaned.drop(["Year"],axis=1)
#
# #添加虚拟变量
# data_with_dummies = pd.get_dummies(data_no_multicollinearity,drop_first=True)
# print(data_with_dummies.columns)
# #获取所有列
# print(data_with_dummies.columns.values)
# cols = ['log_price', 'Mileage', 'EngineV', 'Brand_BMW', 'Brand_Mercedes-Benz',
# 'Brand_Mitsubishi', 'Brand_Renault', 'Brand_Toyota', 'Brand_Volkswagen',
# 'Body_hatch', 'Body_other', 'Body_sedan', 'Body_vagon', 'Body_van',
# 'Engine Type_Gas', 'Engine Type_Other', 'Engine Type_Petrol',
# 'Registration_yes']
# data_preprocessed = data_with_dummies[cols]
# print(data_preprocessed.head())
#
# # 3.5 创建回归
# targets = data_preprocessed["log_price"]
# inputs = data_preprocessed.drop(["log_price"],axis=1)
# ## 3.5.1 缩放数据
# from sklearn.preprocessing import StandardScaler
# scaler = StandardScaler()
# scaler.fit(inputs)
# inputs_scaled = scaler.transform(inputs)
# ## 3.5.2 拆分数据
# from sklearn.model_selection import train_test_split
# x_train,x_test, y_train,y_test = train_test_split(inputs_scaled, targets, test_size=0.2, random_state=365)
# ## 3.5.3 创建回归
# reg = LinearRegression()
# reg.fit(x_train,y_train)
# #检测线性回归
# y_hat = reg.predict(x_train)
# plt.scatter(y_train, y_hat)
# plt.xlabel("target y_train",size=18)
# plt.ylabel("predict y_hat",size=18)
# plt.xlim(6,13)
# plt.ylim(6,13)
#
# #残差检测:必须是正态分布
# sns.displot(y_train-y_hat)
# plt.title("PDF", size=18)
# # plt.show()
#
# #R方
# r2 = reg.score(x_train,y_train)
# print(r2) #0.744996578792662
#
# #截距
# print(reg.intercept_) #9.415239458021299
#
# #系数
# print(reg.coef_)
# # [-0.44871341 0.20903483 0.0142496 0.01288174 -0.14055166 -0.17990912
# # -0.06054988 -0.08992433 -0.1454692 -0.10144383 -0.20062984 -0.12988747
# # -0.16859669 -0.12149035 -0.03336798 -0.14690868 0.32047333]
#
# reg_summary = pd.DataFrame(inputs.columns.values,columns=["Feartures"])
# reg_summary["Weights"] = reg.coef_
# print(reg_summary)
# """
# Feartures Weights
# 0 Mileage -0.448713
# 1 EngineV 0.209035
# 2 Brand_BMW 0.014250
# 3 Brand_Mercedes-Benz 0.012882
# 4 Brand_Mitsubishi -0.140552
# 5 Brand_Renault -0.179909
# 6 Brand_Toyota -0.060550
# 7 Brand_Volkswagen -0.089924
# 8 Body_hatch -0.145469
# 9 Body_other -0.101444
# 10 Body_sedan -0.200630
# 11 Body_vagon -0.129887
# 12 Body_van -0.168597
# 13 Engine Type_Gas -0.121490
# 14 Engine Type_Other -0.033368
# 15 Engine Type_Petrol -0.146909
# 16 Registration_yes 0.320473
# """
# # 当权重都为0,那么变量将会是基准
# print(data_cleaned["Brand"].unique())
# # ['BMW' 'Mercedes-Benz' 'Audi' 'Toyota' 'Renault' 'Volkswagen' 'Mitsubishi']
# # 我们发现Audi没有在权重表中, Brand_BMW =0.014250, 那么BMW比Audi贵,Brand_Renault=0.179909,那么Renault比Audi便宜
#
# #测试
# y_hat_test= reg.predict(x_test)
# plt.scatter(y_test, y_hat_test, alpha=0.2)
# plt.xlabel("target y_test",size=18)
# plt.ylabel("predict y_hat_test",size=18)
# plt.xlim(6,13)
# plt.ylim(6,13)
# # plt.show()
#
# df_pf = pd.DataFrame(np.exp(y_hat_test), columns=["Prediction"])
# y_test = y_test.reset_index(drop=True)
# df_pf["Target"] = np.exp(y_test)
# df_pf["Residual"] = df_pf["Target"] - df_pf["Prediction"]
# df_pf["Difference%"] = np.absolute(df_pf["Residual"]/df_pf["Target"]*100)
# # print(df_pf)
# # print(df_pf.describe())
# # pd.options.display.max_rows=100
# new_df = df_pf.sort_values(by=["Difference%"])
# print(new_df.head(100))
6.逻辑回归(分类)
6.1 基础
import numpy as np
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
from sklearn.cluster import KMeans
#1.读取数据
data = pd.read_csv("3.01. Country clusters.csv")
print(data)
#2. 绘图
plt.scatter(data["Longitude"],data["Latitude"])
plt.xlim(-180,180)
plt.ylim(-90,90)
# plt.show()
#3.聚集
#数据切片
x = data.iloc[:,1:3]
print(x)
kmeans = KMeans(3) #3 要生成的集群数
res = kmeans.fit(x)
#集群结果
identified_clusters = kmeans.fit_predict(x)
print(identified_clusters) #[0 0 2 2 2 1]
data_with_clusters = data.copy()
data_with_clusters["Cluster"] = identified_clusters
print(data_with_clusters)
"""
Country Latitude Longitude Language Cluster
0 USA 44.97 -103.77 English 0
1 Canada 62.40 -96.80 English 0
2 France 46.75 2.40 French 2
3 UK 54.01 -2.53 English 2
4 Germany 51.15 10.40 German 2
5 Australia -25.45 133.11 English 1
"""
#绘制散点图
plt.scatter(data["Longitude"],data["Latitude"], c=data_with_clusters["Cluster"],cmap="rainbow")
plt.xlim(-180,180)
plt.ylim(-90,90)
# plt.show()
6.2 实例
#1.加载数据
raw_data = pd.read_csv("2.01. Admittance.csv")
data = raw_data.copy()
data["Admitted"] = data["Admitted"].map({"Yes":1,"No":0})
print(data)
"""
[168 rows x 2 columns]
SAT Admitted
0 1363 0
1 1792 1
2 1954 1
3 1653 0
4 1593 0
.. ... ...
163 1722 1
164 1750 1
165 1555 0
166 1524 0
167 1461 0
[168 rows x 2 columns]
"""
#定义因变量
y = data["Admitted"]
#定义自变量
x1 = data["SAT"]
#2.回归
x = sm.add_constant(x1)
reg_log = sm.Logit(y,x)
result_log = reg_log.fit()
print(result_log)
"""
Optimization terminated successfully.
Current function value: 0.137766
Iterations 10
<statsmodels.discrete.discrete_model.BinaryResultsWrapper object at 0x000001E00A4ADBE0>
"""
#概要
print(result_log.summary())
"""
Logit Regression Results
==============================================================================
Dep. Variable: Admitted No. Observations: 168
Model: Logit Df Residuals: 166
Method: MLE Df Model: 1
Date: Mon, 10 May 2021 Pseudo R-squ.: 0.7992
Time: 16:16:02 Log-Likelihood: -23.145
converged: True LL-Null: -115.26
Covariance Type: nonrobust LLR p-value: 5.805e-42
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const -69.9128 15.737 -4.443 0.000 -100.756 -39.070
SAT 0.0420 0.009 4.454 0.000 0.024 0.060
==============================================================================
Possibly complete quasi-separation: A fraction 0.27 of observations can be
perfectly predicted. This might indicate that there is complete
quasi-separation. In this case some parameters will not be identified.
"""















 5442
5442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









