









大数据
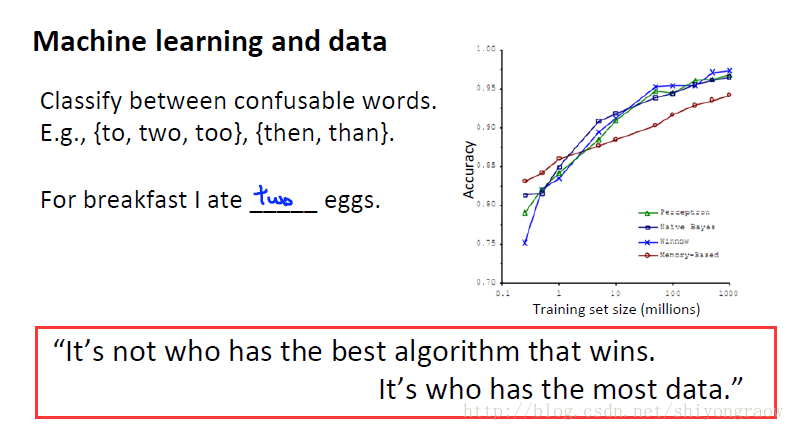
机器学习中约定俗成有这么一句话:更多的数据决定算法的好坏。
但是数据变多时,计算量也就相应增多。
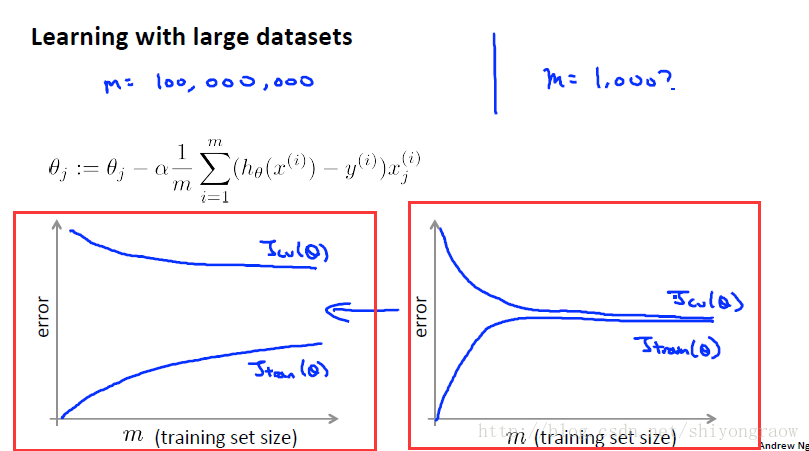
当我们的训练集大小为一亿时,训练集就非常大了。当我们训练集非常大时,我们会随机选取几千条数据来验证我们的算法是否合适。这里随机取1000个数据。画出学习曲线,左边处于高方差状态,我们需要增加训练集。右边处于高偏差状态,增加特征或是一个不错的方法。
这是从中选取1000个数据,但在大规模的机器学习下,我们还是需要找到相应的计算方法。
随机梯度下降
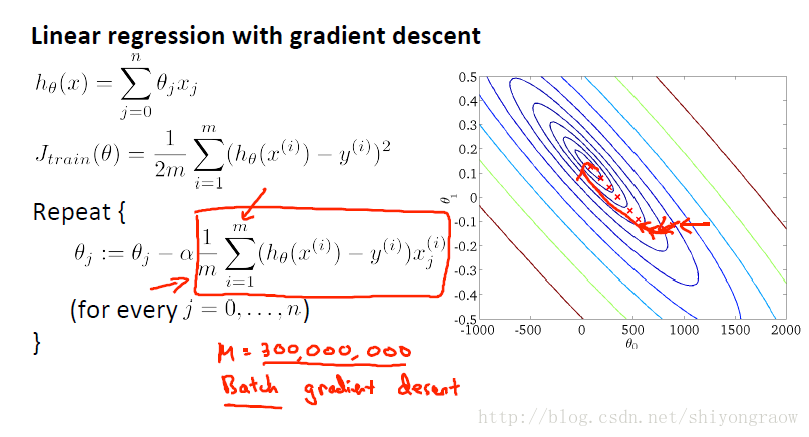
像前面的逻辑回归、线性回归等我们求最小值都是使用的批量梯度下降,也就说要使用当前所有的数据值,但当遇到大规模的数据时,每次计算代价就非常大,所以考虑引入随机梯度下降。
随机梯度下降在每一步的迭代中不用考虑全部的训练样本,只需考虑一个训练样本。
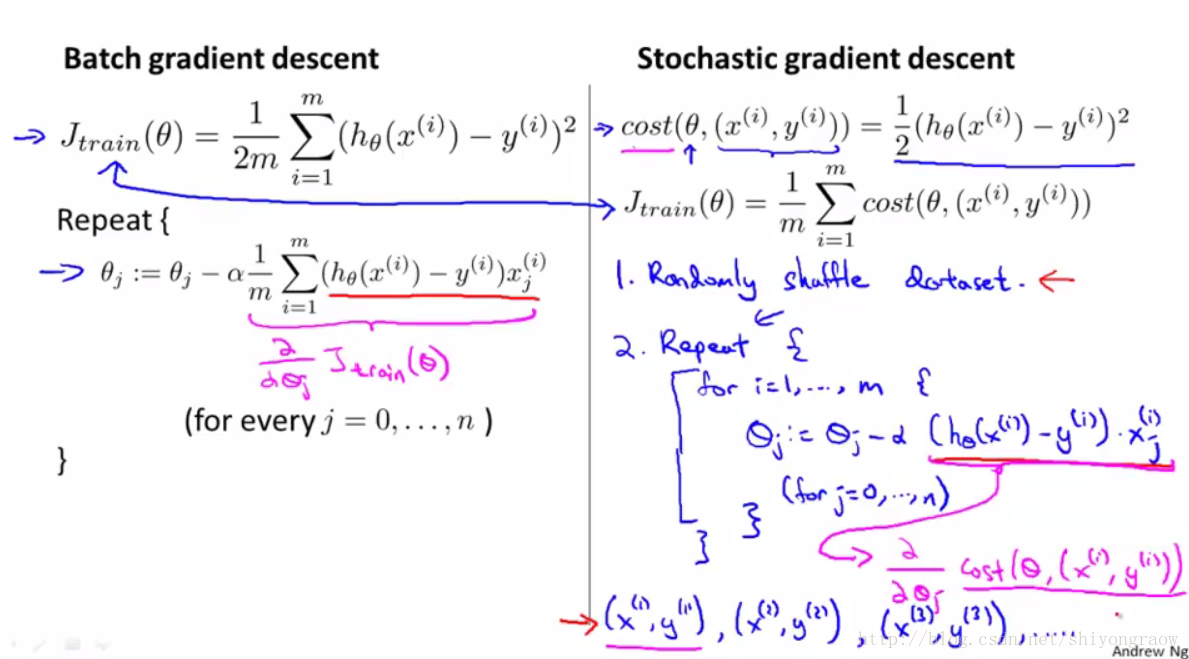
1、随机打乱全部数据。
2、重复执行梯度下降。但每次只从m个样本中随机取一个样本代入计算。
从图上更直观反映
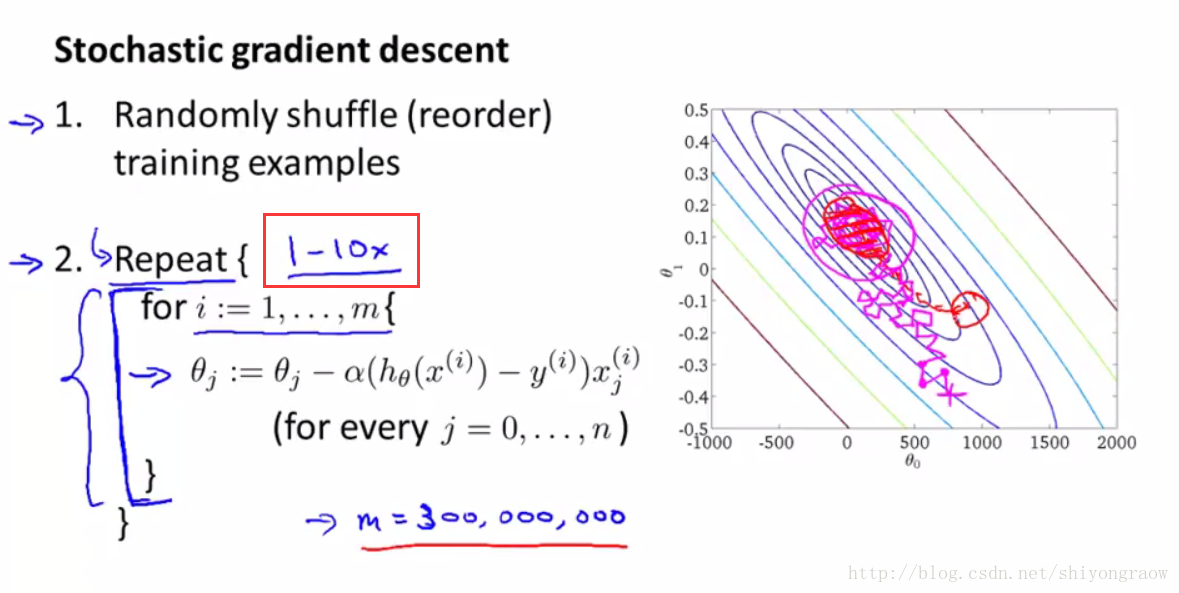
相比较于批量梯度下降,随机梯度下降过程中会更曲折一些,但迭代速度回更快。而且这俩个的收敛形式是不一样的,批量梯度下降会收敛到一个全局最小值,随机梯度下降最终是收敛到全局最小值区域内徘徊,并非固定在一个具体值。
注意:随机梯度下降中的外层循环我们一般设为1-10次都是合理的,当然如果m非常大,即内层循环非常大,那么我们外层循环这时设为1是合理的。
小批量梯度下降
小批量梯度下降有时甚至比随机梯度下降算法还要快一些。

不同于随机梯度下降每次只用一个样本,小批量梯度下降每次采用b个样本。如下,小批量梯度下降每次采用10个样本更新。
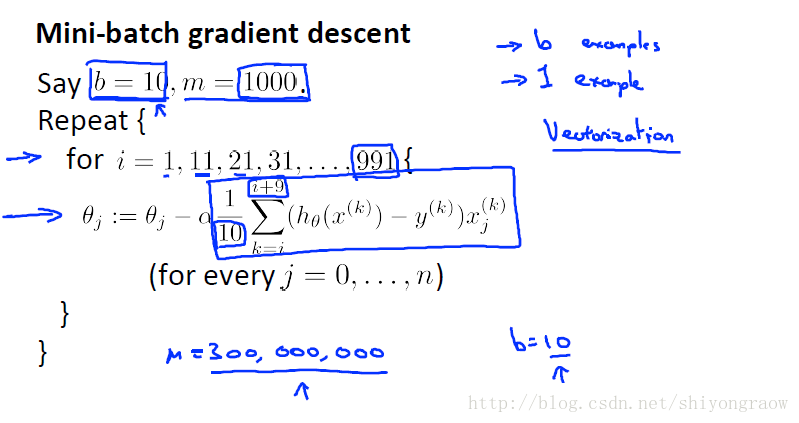
为什么小批量梯度下降比随机梯度下降效果要好呢,可以向量化实现。如上例,小批量梯度下降每次可以并行计算10个样本,随机批量梯度下降每次只计算一个样本。
随机梯度下降的收敛
当我们运行随机梯度下降算法时,如果确保算法是正常收敛还有如何去调整学习速率 α 的值呢?

随机梯度下降过程中,在每一次梯度下降的迭代执行前,我们都去用当前的随机样本
(x(i),y(i))
来计算当前的关于
θ
的
cost
函数。
在每次迭代之后都去更新
θ
,每个样本迭代一次。
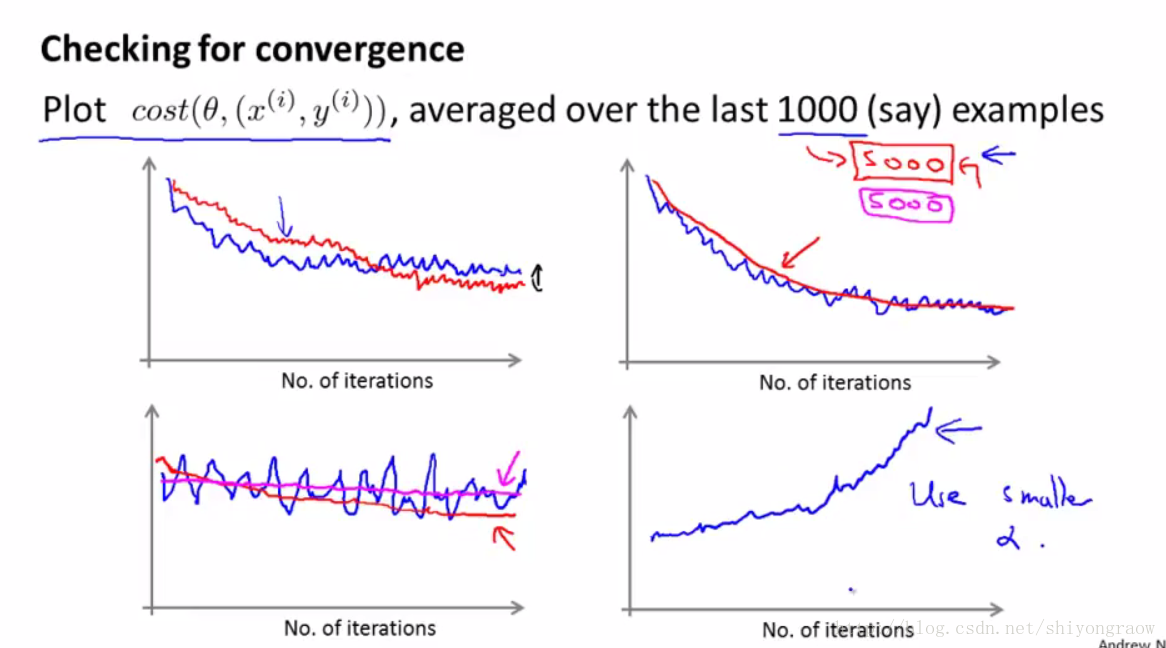
最后为了检查随机梯度下降的收敛性,我们要做的是每1000次迭代,我们可以画出前一步中计算出的 cost 函数。
我们把这些 cost 函数画出来,并对算法处理的最后1000个样本的 cost 值求平均值。如果你这样做的话它会很有效地帮你估计出你的算法在最后1000个样本上的表现。所以,我们不需要时不时地计算 Jtrain ,那样的话需要所有的训练样本。
下面给出几个例子
学习速率 α 的确定
一般来说, α 一般是保持不变的,如果你想让随机梯度下降确实收敛到全局最小值,你可以随时间的变化减小学习速率 α 的值。一般采用如下公式:
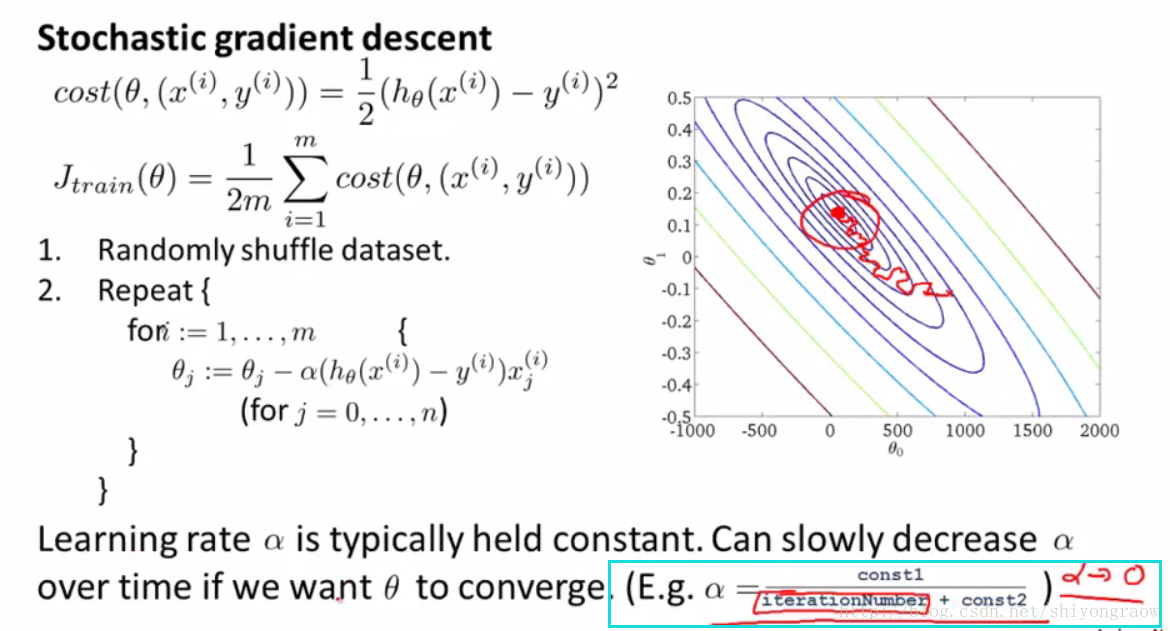
但是这样就要花更多时间在调整常数1和常数2上,这就更增加了工作量。所以一般还是采用固定 α 的方法。















 530
530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









